Мы уже давно привыкли к тому, что Яндекс делает умные колонки и делает их хорошо. В портфолио компании целая куча Яндекс Станций, в линейку входит даже ТВ. Но до сегодняшнего дня взять Алису с собой можно было только в «портативной» версии Станции — Стрит. И то, на улице она в большей степени работала как обычная bluetooth-колонка. Да и хотим ли мы делиться данными, задавать личные вопросы и слушать ответы на них на весь парк? Думаем, нет! И кажется именно об этом подумали в Яндекс.
Впервые наушники от Яндекс показали примерно полгода назад, в виде небольшого тизера — одной картинки. Сразу стало понятно, что Яндекс и Алиса AI идут в сторону персонального аудио. Собственно, Яндекс Дропс — это первая попытка перенести Алису AI в карман. И, забегая вперед, кажется удачная…
Интереснее всего то, что продажи начались сегодня и осуществляются они в чате с Алисой AI и одноименном приложении. Так что можно сказать, что ИИ продает сам себя!
Как выглядят Яндекс Дропс?
Корпус стандартный для TWS-наушников: тут сложно чем-то удивить. Кейс выполнен из качественного матового пластика, на ощупь очень приятный. Во внешности выделяется разве что логотип Яндекс. Снизу на корпусе USB-C разъем и кнопка для сопряжения со смартфоном. Конечно можно соединить устройство и автоматически, открыв кейс и увидев моргание светового индикатора.
Сразу отметим, что наушники будут выпускаться и продаваться в трех расцветках: белая (как у нас), черная и фиолетовая, фирменный цвет Алисы AI.
В коробке кроме наушников и кейса также нашлось место амбушюрам: полупрозрачные силиконовые размера M закреплены на наушниках, но их можно менять на S или L. С посадкой проблем не возникло: наушники сели в ухо идеально и не выпадали, лишь изредка хотелось их поправить. Отмечу также, что при ходьбе и езде на самокате не было ощущения, что они вылетят из слухового прохода, в то же время никакого дискомфорта при длительном ношении.
Как звучат Яндекс Дропс?
По звуку TWS-наушники тоже не удивляют, но звучат они, скажем так, достойно. Я бы даже описал их, как «звучат дороже, чем стоят». Но это ощущения: кому-то звук может показаться грубоватым, бумкающим, но лично я не очень сильно ждал каких-то откровений.
Коротко пройдемся по спецификациям:
Диапазон частот — 20-20 000 Гц
Bluetooth 5.4
Два динамика 11 мм
Суммарная акустическая мощность 5 мВт х 2
Микрофоны — 6 штук, по 3 в каждом наушнике.
Из важного: тут есть активное шумоподавление, которое хорошо работает в городе — не слышно едущих вокруг машин, в метро, автобусе он также справляется со своей работой. Прозрачный режим вряд ли назовешь прорывным: нет ощущения, что ухо открыто, все же чувствуется усиление, поэтому проще наушники снимать.
Из любопытного, подключаются наушники в приложении Алиса AI: с одной стороны логично, с другой, вспоминая Яндекс Станции, мы привыкли подключать умные устройства от компании через приложение «Дом с Алисой».
Звуком я остался доволен: наушники в меру громкие, нет каких-то излишних басов. По умолчанию, звук можно сказать универсальный и я даже не пытался подстроить его в эквалайзере. К слову, в приложении Алиса AI он есть, то есть можно настроить все под себя.
Тут же можно настраивать шумоподавление, управление наушниками нажатием на «ножку» (одиночное, двойное, тройное и долгое).
Алиса на борту
Главная фишка — голосовой ассистент Алиса AI на борту. Конечно, Яндекс не первые, кто встроил персонального голосового ассистента, но в нашей стране просто так не запустить Gemini с тех же Nothing, с Pixel Drops будут те же проблемы.
Поэтому, можно говорить о том, что для многих пользователей подобный опыт общения с наушниками будет первым. Чтобы запустить ассистента достаточно сказать «Алиса, [продиктовать свой запрос]»: в домашней сети это может быть включение/выключение света, умной розетки, телевизора, в «городе» можно пользоваться голосовым поиском, создавать заметки, просить добавить напоминание.
Я протестировал устройства в Екатеринбурге, просто гуляя по городу и находясь там впервые. Первая мысль — получить удобную и простую навигацию, не переставая слушать музыку и не пользуясь смартфоном. Но это, как минимум пока не работает. Тоже самое касается и какого-либо поиска мест в Яндекс Картах. Вероятнее всего, такие функции будут появляться в будущем и если локация будет определяться корректно, то такая функция точно будет востребована.
Гуляя по городу, я дошел до ДК им. Свердлова, именно здесь в конце 1980-х годов появился и работал Свердловский Рок-Клуб и именно здесь начинали творить
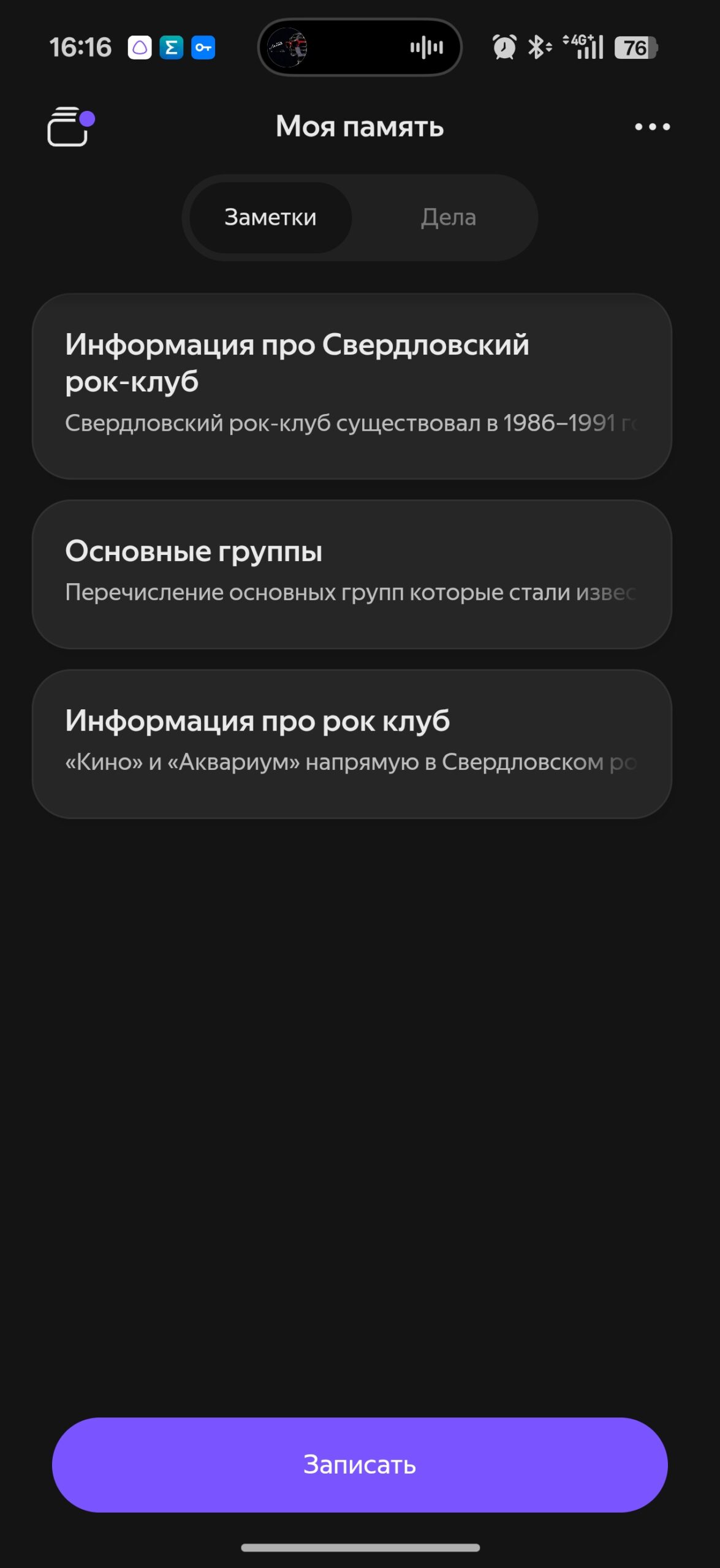
Nautilus Pompilius, Чайф, Агата Кристи, Смысловые галлюцинации и другие. Место знаковое, и именно тут я решил спросить об этом здании, о его истории, как и истории Рок-Клуба. Так, проходя мимо здания, восстановил в памяти и все названия групп и события связанные с этим местом. Но самое главное — тут же воспользовался главной из работающих фишек Дропс — функцией «Моя память». Я просто перенес полученную информацию в нее, чтобы потом вернуться и прочесть все заново. То же самое можно делать с номерами домофонов, адресами друзей, списками покупок: причем все это будет доступно как в приложении, так и в браузерной версии Алиса AI в отдельной вкладке.
Сколько работают Яндекс Дропс?
Могу сказать честно, что ни разу так и не посадил наушники до конца. Это достаточно сложно. По заявлению производителя с включенным шумоподавлением устройство может проработать до 5 часов, а кейс добавляет еще 20 часов.
Нужны ли Яндекс Дропс?
Можно сказать, что Дропс — первый шаг Яндекса в новом направлении. Развитие умных колонок и телевизоров с Алисой как будто бы достигло своего пика и уперлось в определенный потолок. Согласитесь, мы уже давно не видим обновление линейки этих устройств.
В этом смысле, давно пора выходить за рамки умного дома: отчасти из-за этого Яндекс Дропс подключаются не к приложению «Дом с Алисой», а к Алиса AI. При этом бесшовное взаимодействие одной программы с другой, а также команды для умного дома работают корректно и быстро.
На момент своего выхода Дропс — в первую очередь, продукт для энтузиастов. Эти TWS-наушники обладают хорошим звуком, качественным шумоподавлением и на данный момент дают возможность знакомиться с ИИ-функциями постепенно. Опять же, пока количество функции и ИИ-фишек достаточно скромное и стоит ожидать большого количества обновлений. Наверняка, у Яндекса есть целая дорожная карта по развитию продукта и ИИ-функций внутри него.
Но при этом у Дропс крайне приятная цена, что позволяет говорить и о возможном успехе нового продукта прямо со старта: устройство получилось доступным и качественным за свою цену. И в данном случае, цена решает…
Искусственный интеллект заменит Яндекс и Google? Большая история поиска в интернете
От первого поисковика Archie до ИИ-поиска: история интернет-поиска, Google, Яндекс и будущее с нейросетями и AGI
Ещё каких-то тридцать пять лет назад интернет был совершенно жутким местом. Действительно настоящей паутиной — запутанной, непроходимой и лишённой каких-либо ориентиров. Только представьте себе: чтобы найти нужный ресурс, вам приходилось искать его адрес в газете или специальном печатном каталоге. Да, речь идёт о времени до изобретения поиска в интернете.
А ведь, если задуматься, именно поиск изменил нашу жизнь и десятикратно облегчил доступ к информации. Это напоминает то, что сейчас, в 2025 году, происходит с искусственным интеллектом. Не находите?
В этой статье мы проследим весь путь поиска в интернете: как он зародился, как работает, почему он столь важен и, главное, какое будущее его ждёт.
Поиск вчера: от газетных вырезок до алгоритмов
Условно историю поиска можно поделить на три эпохи: каким он был вчера, что представляет собой сегодня и каким станет завтра. Давайте по порядку.
Главная проблема интернета прошлого — это отсутствие нормальной поисковой системы. Выкручивались все по-разному. Кто-то записывал на бумажке нужные ссылки. В кружках по интересам печатали журналы с адресами полезных ресурсов, а иногда информация передавалась просто из уст в уста, по старинке. Конечно, существовали и веб-подборки — специальные страницы, на которых можно было вручную искать нужный интернет-сайт. Не слишком удобно, но такая ситуация была вполне логичной: контента было мало, пользователей тоже, и в основном это были технические энтузиасты. Бизнеса в интернете не существовало как такового.
Archie — первый поисковик в истории
И вот молодой канадский студент по имени Алан Эмтейдж (Alan Emtage) устал от такого положения дел. Осенью 1990 года он представил первый в истории поисковик интернета — Archie (сокращение от «Archives»). Конечно, по нынешним меркам это была примитивная система, но даже в таком виде она значительно упростила жизнь людям.
Archie объединял и индексировал содержимое общедоступных FTP-серверов. Возможно, кто-то ещё помнит такие «FTP-шники»: в те времена именно там можно было скачать игры вроде Duke Nukem, аниме или любой другой контент. Сервис собирал воедино названия файлов, а пользователю нужно было лишь ввести нужное ключевое слово. Проблема заключалась в том, что если в названии файла была ошибка, то Archie просто не мог его обнаружить.
Однако начало было положено. Цель тогда была проста: быстро находить хоть какую-либо подходящую информацию.
Индексация: библиотечная картотека для всего интернета
Чтобы двигаться дальше в изучении поиска, необходимо разобраться с одним чрезвычайно важным термином — индексация. Что вообще означает «проиндексировать интернет»?
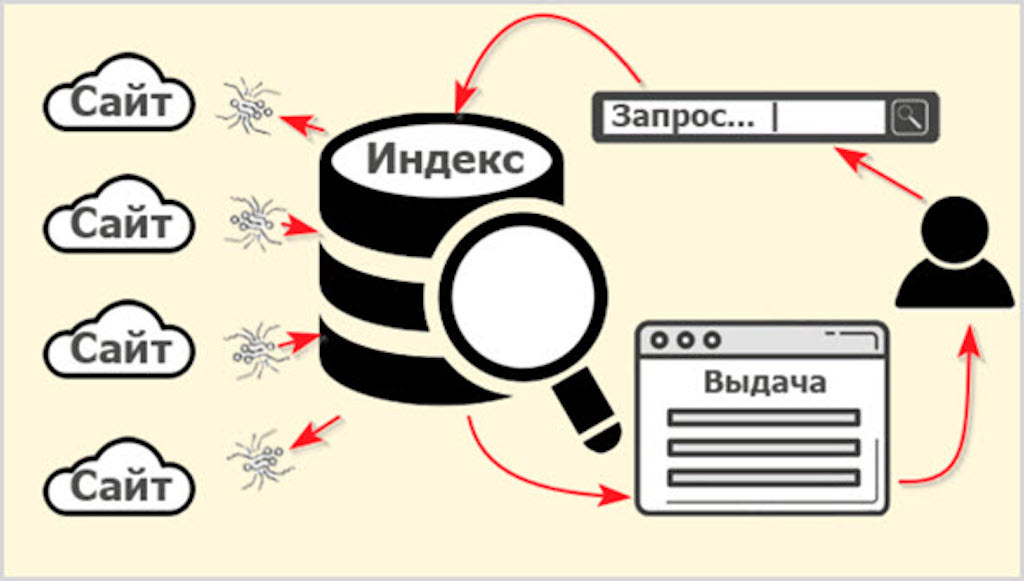
Чтобы любой поисковик мог найти нужный ответ, ему сначала необходимо создать некую базу данных, в которой этот ответ будет храниться. Но ведь весь интернет — это колоссальный объём данных. По некоторым оценкам, речь идёт о нескольких зеттабайтах. Для понимания масштаба: один зеттабайт равен миллиарду терабайт. А по данным на 2025 год, в интернете накоплено уже несколько десятков зеттабайт информации. Естественно, поисковик физически не может пропускать через себя каждый раз такой массив данных. Именно поэтому было найдено подходящее решение — индексация.
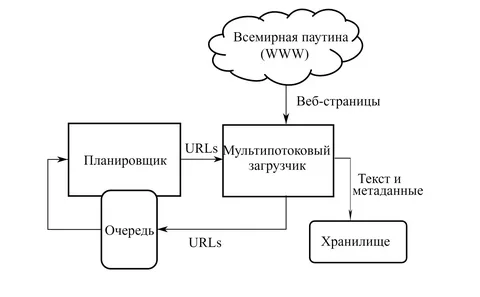
Принцип прост. Специальный поисковый бот регулярно обследует всё интернет-пространство и обрабатывает информацию. Сначала программа-планировщик выстраивает маршрут для обхода сайтов. Этот маршрут зависит от важных характеристик сайтов — например, их цитируемости или частоты обновления. Затем планировщик передаёт этот маршрут другой части поискового робота — так называемому «пауку» (crawler). Паук обходит документы по заданному маршруту, и если сайт работает и доступен, он выкачивает содержимое и отправляет его в хранилище.
Таким образом, бот создаёт нечто вроде слепка интернета — библиотечной картотеки, если угодно, которая хранится на серверах. Туда переносится не весь интернет целиком, а только полезная информация — без спама, дубликатов и прочих ненужных документов. В результате получаются проиндексированные веб-страницы: поисковик знает адрес, по которому находится подходящий запросу пользователя контент — слова, изображения или любые другие данные.
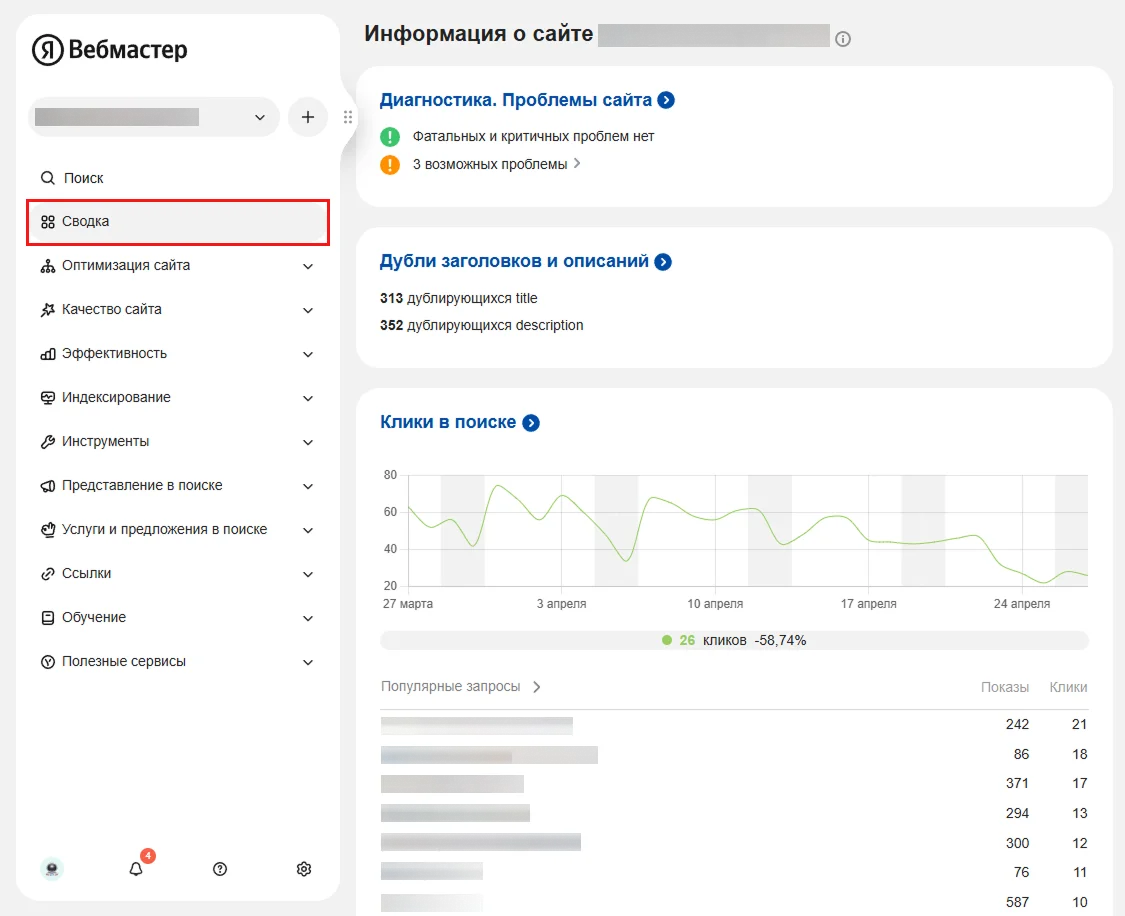
После индексации слепок веб-сайта добавляется в регулярно обновляемую базу данных, чтобы поиск не занимал много времени. Визуально увидеть проиндексированную веб-страницу обычный пользователь не может, однако с помощью специального инструмента это всё же возможно. Например, у Яндекса существует сервис Вебмастер, где можно проверить свой ресурс на индексацию.
Таким образом, проиндексированные веб-страницы — это важнейший элемент любого поисковика, будь то Google, Microsoft Bing или Яндекс. Без подобной картотеки оперативно находить нужную информацию попросту невозможно.
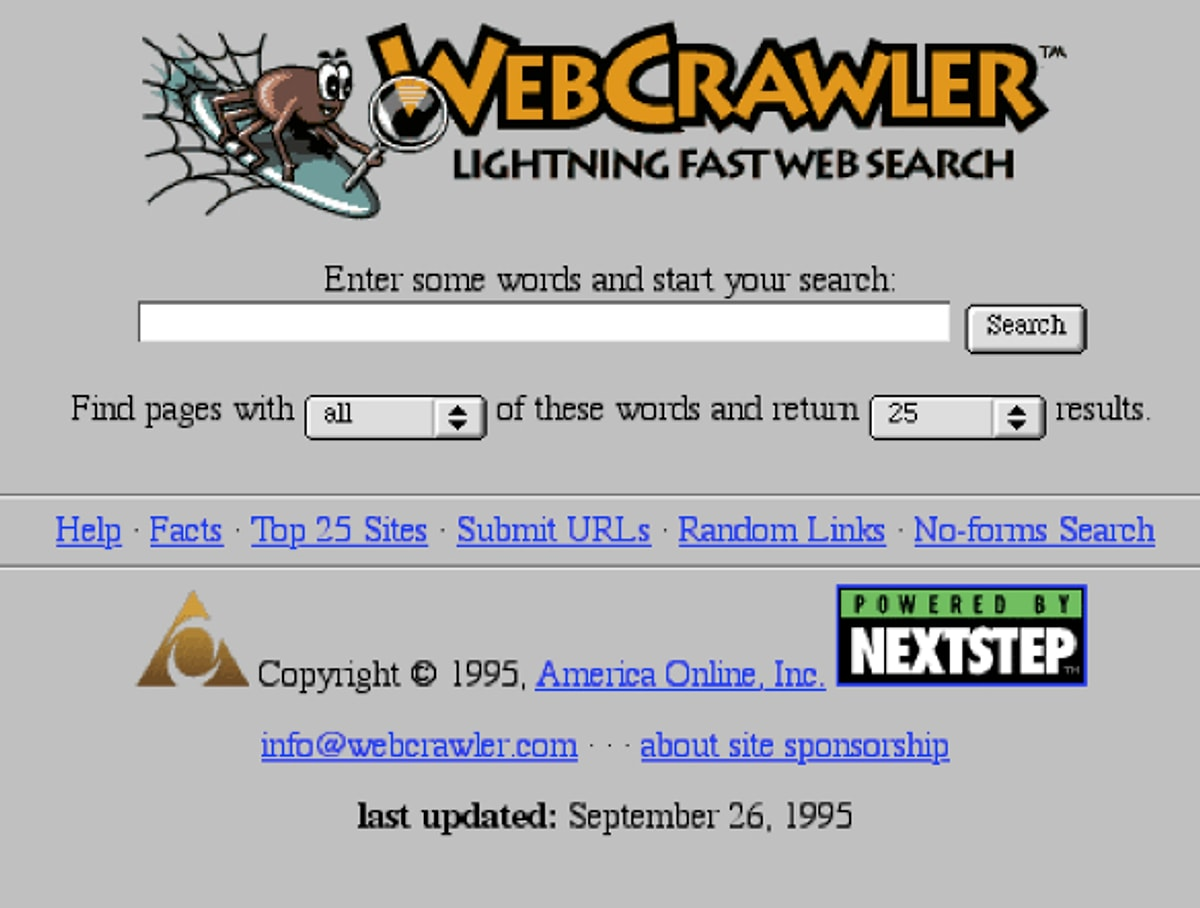
WebCrawler — стандарт на десятилетие
Первым поисковиком, который стал использовать индексацию в более или менее современном виде, стал WebCrawler, запущенный в 1994 году. Его робот-«паучок» собирал информацию со всей сети, индексировал её и вносил в собственную базу данных. Разработка имела огромный успех и, в сущности, задала стандарт на десятилетие вперёд. Даже сейчас принципы, которые заложил WebCrawler, продолжают работать в основе современных поисковых систем.
Морфология языка: как Яндекс покорил великий и могучий
Но просто собрать и проиндексировать информацию — это лишь половина дела. Главное — правильно понять, что именно ищет пользователь. И здесь особенно интересен опыт Яндекса в работе с морфологией русского языка.
Дело в том, что поисковой системе необходимо находить не просто точное совпадение слов, а понимать смысл запроса. Подумайте сами: слово «шляпка» может относиться к грибу, головному убору или гвоздю. Русский язык полон подобных многозначных слов, что делает задачу на порядок сложнее, чем в английском.
Именно поэтому так показателен пример Яндекса. Компания анализировала, как часто слова встречаются вместе в текстах, используя данные Национального корпуса русского языка. Если пользователь ищет, например, «воронежский», система может автоматически добавить к поиску слово «Воронеж».
Яндекс также научился различать языки, чтобы не путаться при обработке запросов. Система определяла язык запроса по алфавиту, характерным сочетаниям букв и даже по региону пользователя. И, разумеется, люди постоянно допускают опечатки — примерно 12% поисковых запросов содержат ошибки. Поэтому поисковик автоматически проверял запрос на грамотность и предлагал исправленную версию.
Вот так, в зависимости от особенностей языка, поисковики справлялись с проблемами человеческих запросов.
Google и революция PageRank
Существовало и множество других поисковиков того времени — AltaVista, Excite и другие. Функционал у всех был примерно одинаковым, поэтому подробно останавливаться на каждом не имеет смысла. Важны первые и по-настоящему революционные.
Примерно в это же время, в 1998 году, два аспиранта из Стэнфордского университета — Сергей Брин и Ларри Пейдж — разработали поисковик Google. О нём, конечно, можно рассказывать долго. Но на самом деле важен не столько сам поисковик, сколько технология, которую для него разработали эти двое. Она называется PageRank.
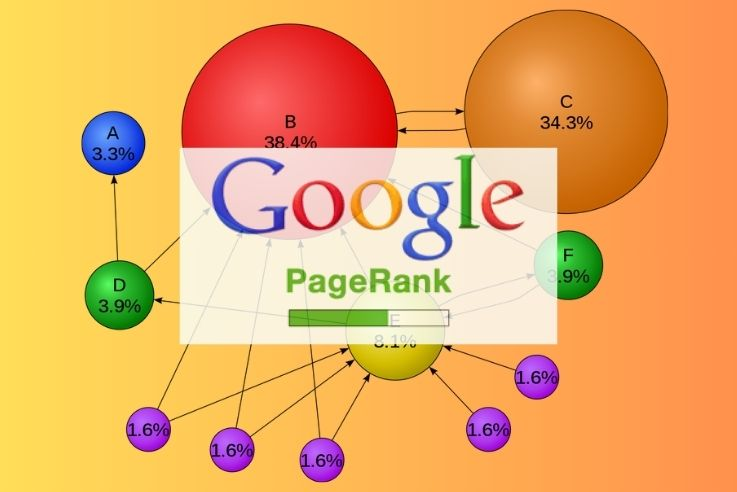
Это была по-настоящему революционная вещь. Давайте разберёмся, в чём заключалась основная проблема поисковиков того времени. Да, благодаря индексации они могли находить ресурсы с нужной информацией, но вот качество найденных сайтов оставалось под большим вопросом. Грубый пример: если бы вы дали поисковику того времени запрос «как поменять лампочку», на первом месте мог бы оказаться не форум электриков, а сайт анекдотов. То есть релевантность поиска была практически на нуле.
PageRank же делал простую, но гениальную вещь. Алгоритм присваивал каждой странице показатель важности. Чем больше ресурсов в интернете ссылалось на определённую веб-страницу, тем более важной она становилась. Соответственно, при запросе пользователя на первые позиции выходила ссылка на тот ресурс, который зарекомендовал себя в интернете. Просто и изящно.
Внедрение PageRank совершило настоящую революцию в зарождающейся отрасли поисковых систем. Буквально за считанные месяцы все конкуренты создали аналогичные системы ранжирования. Со временем аналоги PageRank эволюционировали в нечто гораздо более сложное, где учитывалось множество факторов — вплоть до местоположения пользователя. Но об этом чуть позже.
MatrixNet от Яндекса: машинное обучение раньше всех
Кстати, поиск от Яндекса и сама компания в целом были важными первопроходцами в индустрии. Разработчики Яндекса буквально первыми стали использовать машинное обучение в поиске, когда Google ещё даже не задумывался об этом.
В 2009 году Яндекс сделал важный шаг в развитии поисковых технологий, начав использовать машинное обучение (ML — Machine Learning) значительно раньше Google. Компания разработала собственную технологию под названием MatrixNet, которая совершила настоящий прорыв в области поисковых систем.
К тому моменту интернет уже был огромным, и по некоторым запросам находились миллионы страниц. Просто показать все сайты, содержащие слова из запроса, было уже недостаточно — ведь пользователю пришлось бы целую вечность листать страницы с результатами. Требовалось научиться определять, какие страницы действительно отвечают на вопрос пользователя.
Для этого поисковик анализировал множество факторов: как часто встречаются слова из запроса, сколько на сайт ведёт ссылок, насколько он популярен у пользователей, и так далее. Всего таких факторов были тысячи, и первоначально они отслеживались вручную. Специалисты-эксперты — так называемые асессоры — помогали системе учиться, оценивая качество результатов поиска. Они оценивали конкретные страницы по конкретным запросам, и затем на этих оценках обучалась формула, которая ранжировала сайты по любому запросу.
Главная особенность MatrixNet заключалась в том, что он мог автоматически работать с огромным количеством таких факторов и при этом не переобучаться. То есть формула ранжирования сайтов стала подбираться на основании всех известных факторов и знаний о том, какие страницы лучше соответствуют запросу, а какие — хуже. Обычные алгоритмы в подобной ситуации начинали находить несуществующие закономерности, а MatrixNet оставался точным.
Более того, сама система могла настраивать поиск для разного типа запросов. Например, можно было улучшить поиск по музыке, не испортив при этом поиск по другим темам. А ещё MatrixNet был невероятно быстрым: он успевал проверить все факторы за доли секунды. Всё это работало на тысячах серверов одновременно — каждый искал по своей части интернета, находил лучшие результаты, а потом они объединялись в единый список, и пользователь практически мгновенно получал именно те сайты, которые ему были нужны.
Эта технология стала важнейшим шагом в развитии поиска. Она позволила учитывать намного больше факторов, чем раньше, и при этом делать это точно. С появлением MatrixNet поиск стал значительно умнее — он начал гораздо лучше понимать, чего хочет пользователь.
Самое забавное: технология настолько опередила своё время, что инженерам Яндекса пришлось сооружать инсталляцию из водяных труб, чтобы наглядно объяснить журналистам, что такое машинное обучение.
Три кита поиска прошлого
Подведём итог «поиска вчера» и назовём три главных кита, на которых он держится:
Индексирование веб-страниц — создание своеобразной картотеки всего интернета.
Настройка релевантности поиска — по типу PageRank от Google.
Машинное обучение — впервые полноценно применённое Яндексом в 2009 году.
Поиск сегодня: от тысяч факторов до нейросетей
Нынешние поисковые системы эволюционировали в совершенно невероятные сервисы, которыми мы пользуемся каждый день. Когда компании осознали, что на продаже рекламы на самых посещаемых ресурсах интернета можно прекрасно зарабатывать, организации, которые изначально просто занимались поиском веб-страниц, превратились в настоящих технологических гигантов. Достаточно посмотреть на Google или Яндекс и оценить, в скольких сферах они присутствуют сегодня.
С расширением интернета стало очевидно, что искать нужно не только сайты, но и отдельные видеоролики, изображения, рестораны, природные локации и многое другое. Работы меньше не стало — интернет за последние десятилетия вырос многократно.
Предугадывание запросов
Например, чтобы ускорить поиск информации, появилась функция угадывания запроса пользователя. Специальный алгоритм запоминал, к какому слову привязана самая частая продолжающая связка — с учётом местоположения пользователя, самых частых запросов и множества других факторов. Если человек начинает вводить запрос «кто такой», поисковик мгновенно предлагает несколько вариантов продолжения. Попробуйте проверить это сами — результаты могут удивить.
От единиц к тысячам факторов
По сути, все технологии из «поиска вчера» перекочевали в «поиск сегодня», но на совершенно иных мощностях. Если раньше использовались лишь несколько метрик (вспомните PageRank от Google), то сегодня поисковики оперируют тысячами факторов ранжирования. Давным-давно для присвоения статуса полезности нужна была всего одна метрика — цитируемость ссылки. Теперь же алгоритмы анализируют колоссальное число параметров. MatrixNet от Яндекса, о котором мы уже рассказали, в своё время был именно таким исключением — он опережал эпоху.
Администрировать эти тысячи факторов вручную, естественно, невозможно. И тут на помощь приходит машинное обучение.
RankBrain от Google: поиск вещей, а не строк
Нейросети прочно вошли в нашу жизнь. С их помощью мы генерируем изображения, создаём видео, пишем тексты. И революция, которая происходит вокруг нас сейчас, стала возможной в том числе благодаря поиску в интернете. Ведь прародителями современных нейросетей с начала 2010-х годов стало именно машинное обучение.
Google тоже не стоял на месте. В 2015 году компания представила технологию RankBrain, и поисковик научился искать вещи, а не строки.
Чтобы обучить алгоритмы, инженеры Google сначала «скармливали» ему данные из различных источников, чтобы он начал их сопоставлять и упорядочивать выдачу на основе этих вычислений. Затем RankBrain наблюдал, как пользователи взаимодействуют с результатами поиска, созданными при помощи машинного обучения. Если пользователи оставались довольны результатами, алгоритм продолжал работать в том же направлении. Если результат не устраивал — машина начинала процесс заново.
RankBrain также оценивал релевантность контента на странице. Речь шла не только о сопоставлении ключевых слов, но и о глубоком понимании контекста. Он мог различать фрагменты, которые затрагивают разные аспекты и подтемы, связанные с основной темой запроса.
В целом, RankBrain выполнял две основные задачи. Во-первых, учился понимать поисковые запросы — их смысл и ключевые слова на веб-страницах. Во-вторых, измерял удовлетворённость пользователя результатами и подстраивался соответственно.
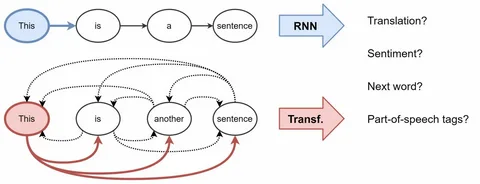
Нейросети-трансформеры: поиск по смыслу
Внедрение машинного обучения многократно улучшило опыт поиска. Он стал значительно персонализированнее и намного умнее. Именно благодаря нейросетям нового типа — так называемым нейросетям-трансформерам — и Google, и Яндекс научились понимать смысл запроса, а не просто искать совпадения слов.
Например, сегодня можно написать в поисковой строке «фильм, где мужчина выращивает картошку на Марсе», и вы получите множество релевантных ссылок с правильным ответом — фильм «Марсианин». Всё это происходит потому, что поисковик понимает смысл запроса, а не просто ищет ключевые слова на страницах.
Поиск завтра: эра искусственного интеллекта
Однако всё вышесказанное — лишь часть картины. Речь не только о машинном обучении. За последние несколько лет произошла настоящая революция — появились чатботы на основе больших языковых моделей.
На самом деле поиск будущего уже среди нас, и его можно смело назвать поиском настоящего. Это третий этап в развитии интернета и в поведении пользователей. Теперь в интернете есть все и всё: бизнес, инвестиции, сильные команды и продукты. Сейчас недостаточно просто находить актуальную информацию быстро. Теперь важно быстро находить самое лучшее из всего существующего контента.
У чатбота можно узнать практически что угодно, причём максимально персонализированно. В последний год компании массово внедряют чатботов в свои поисковые системы.
Экзистенциальный кризис поисковиков
Любопытно, что когда чатботы только начали появляться, поисковые компании пережили своего рода экзистенциальный кризис. Google вообще ввёл «красный код» внутри компании и стал считать ChatGPT своей главной угрозой. Однако спустя время стала очевидна одна крайне важная вещь: чатботы ошибаются. Причём не просто ошибаются, а порой галлюцинируют — выдумывают факты, которых не существует в реальности.
Простыми словами, чатбот, который должен был стать абсолютным поиском, оказался неспособен в одиночку справиться с этой задачей. Однако решение проблемы нашлось: объединить чатбота и поисковую систему.
Симбиоз: чатбот + поисковая система
Выгода от подобного симбиоза получается превосходная. Чатбот естественным языком отвечает на поставленный вопрос, превосходя все алгоритмы прошлого в десятки раз. С ним можно просто разговаривать как с человеком, и нет необходимости переходить по множеству ссылок, потому что вся информация суммируется сразу в один готовый ответ. А технологии поиска, в свою очередь, помогают чатботу находить достоверную и актуальную информацию, подкрепляя ответ релевантными ссылками на источники.
Copilot от Microsoft
Одним из первых представителей такого подхода стал Copilot от Microsoft. Компания инвестировала миллиарды долларов в OpenAI и встроила в свой поисковик Bing на тот момент самый мощный чатбот в истории — GPT-4 Turbo. То есть технология поиска работала совместно с чатботом, чтобы выдать максимально персонализированный результат.
Google AI Overviews и Gemini
Google же решила подойти к проблеме более фундаментально. В мае 2024 года компания представила собственную модель Gemini, специально адаптированную для поиска. Система получила название AI Overviews и работает через так называемые «ИИ-обзоры».
Когда пользователь задаёт вопрос, Gemini не просто ищет информацию, но анализирует её, структурирует и представляет в удобном формате. При этом система всегда указывает источники информации, позволяя пользователю проверить данные.
Одна из самых интересных возможностей — анализ видео для поиска решения технических проблем. Например, если у вас сломался проигрыватель виниловых пластинок, достаточно снять короткое видео проблемы, и система поможет найти решение.
Google также анонсировала системы, которые не только помогают с поиском, но и выполняют действия за пользователя. Например, можно написать: «Купи билет из Москвы в Стамбул», и нейросеть самостоятельно оформит покупку.
SearchGPT от OpenAI
Не остаётся в стороне и сама компания OpenAI. В конце 2024 года она представила собственный поисковик SearchGPT (впоследствии интегрированный в ChatGPT как функция поиска). Он объединяет возможности языковой модели GPT-4o с прямым доступом к актуальной информации из интернета.
SearchGPT работает принципиально иначе, нежели привычные поисковики. Когда вы задаёте вопрос, система не просто выдаёт список ссылок, а сразу формирует подробный ответ, основанный на данных из различных источников. При этом каждый факт в ответе сопровождается ссылкой на первоисточник — будь то новостная статья, научная публикация или специализированный блог.
В SearchGPT также появились специальные визуальные форматы для определённых типов запросов. Например, при поиске погоды пользователь видит детальный прогноз с графиками. При запросе котировок — биржевые данные в реальном времени. Для спортивных событий — актуальное расписание матчей и результаты.
Однако подобные решения, разумеется, есть и у других игроков рынка. И в этом отношении OpenAI пока остаётся в роли догоняющего. Главное преимущество SearchGPT — это возможность вести полноценный диалог: можно задавать уточняющие вопросы, и система будет учитывать контекст всего разговора.
Яндекс и поиск с Нейро
Отечественные разработчики тоже не отстают. В октябре 2024 года Яндекс представил масштабное обновление своего поисковика, интегрировав в него технологию Нейро. Поиск с Нейро работает по той же модели: он сразу даёт ответ на вопрос, ссылаясь на источники в интернете. Система автоматически определяет, когда её помощь будет действительно полезна, и появляется в результатах поиска самостоятельно. Если же нейросетевой ответ не был показан автоматически, достаточно нажать на специальную кнопку под поисковой строкой.
Поиск с Нейро умеет работать со сложными составными вопросами, и с ним можно вести полноценный диалог, поскольку он понимает контекст. Например, вы можете спросить: «Какая сегодня ключевая ставка?» А потом просто уточнить: «А когда изменится?» И поиск ответит датой следующего заседания Центрального банка. Раньше для этого пришлось бы делать два полноценных независимых поисковых запроса.
Кроме того, система научилась работать и с изображениями. В поиске по картинкам или через умную камеру можно задавать вопросы о конкретных деталях на фотографии. Сфотографировали автомобиль — и просто спросили, сколько он стоит. Не нужно знать марку и модель: вы сразу получаете готовый ответ. А если на фотографии рядом с основным объектом присутствует другой предмет — например, велосипед — поиск поймёт контекст и всё равно ответит именно про автомобиль.
Более того, можно сфотографировать задачу по математике для девятого класса, и поиск самостоятельно её решит — даже если такой задачи нет в интернете. (Простите за это опасное знание.)
Поиск завтрашнего дня: AGI и абсолютная персонализация
Всё описанное выше — это поиск сегодня, и мы уже живём с ним бок о бок. Но что ждёт нас в будущем?
По прогнозам экспертов, в ближайшее время поиск сможет давать ответы на основе не только текстовой, но вообще любой информации в интернете — например, на основе содержимого конкретного видеоролика.
Однако использование нейросетей в связке с поиском — это, по всей видимости, промежуточный вариант. Настоящий поиск будущего должен быть связан с AGI — Artificial General Intelligence, то есть так называемым «настоящим» искусственным интеллектом. Не просто алгоритмом, который пытается угадать, что хочет пользователь, а полноценным цифровым разумом, способным мыслить и понимать.
Только представьте, насколько поиск станет совершеннее, когда у вас появится собственный ассистент, который знает вас лучше, чем кто-либо другой, и способен буквально по первым нескольким буквам угадать, что вам нужно. А с учётом того, как стремительно всё развивается в 2025 году, подобный поиск мы, возможно, увидим достаточно скоро.
Судите сами: нынешние технологии уже умеют искать по тексту и изображениям, вести с пользователем полноценный диалог, а персонализированный ИИ-ассистент сможет делать всё это индивидуально для каждого.
Персонализация — вот главная черта поиска будущего, если всё пойдёт так, как предрекают лидеры индустрии.
Заключение
История интернет-поиска — это история человеческого стремления к знаниям. От бумажных каталогов и примитивного Archie в 1990 году — через революцию PageRank и MatrixNet — к нейросетевым ассистентам, которые разговаривают с нами на естественном языке. Каждый этап этой эволюции делал доступ к информации проще, быстрее и точнее.
Сегодня мы стоим на пороге новой эпохи, в которой границы между поисковой системой и интеллектуальным собеседником окончательно стираются. И если прошлое научило нас чему-то, то это тому, что следующий скачок может произойти быстрее, чем кто-либо из нас ожидает
Яндекс расширяет программу стажировок и пригласит рекордные 2800 стажёров
В 2025 году Яндекс пригласит рекордные 2800 стажёров — в том числе нетехнических специальностей.
Яндекс запускает обновлённую программу стажировок. В 2025 году к «технарям» присоединятся студенты гуманитарных и экономических специальностей — появилось новое направление бизнес-стажировок. Всего за год компания планирует нанять 2800 стажёров, что на 20% больше, чем в 2024 году.
Основные направления остаются прежними: фронтенд-, бэкенд-разработка, машинное обучение, аналитика и мобильная разработка — на них приходится 80% вакансий. Студенты нетехнических специальностей смогут стажироваться в финансах, маркетинге, PR, управлении продуктами, HR, закупках и юриспруденции. Набор первых бизнес-стажёров стартует в марте, их число за год вырастет до 500.
Стажировки проходят в офисах Яндекса в Москве, Санкт-Петербурге, Екатеринбурге, Казани, Новосибирске и других городах, а также дистанционно. Все стажёры получают зарплату, могут совмещать работу с учёбой, а у каждого есть ментор. В 2024 году 54% выпускников программы остались в компании.
Яндекс регулярно адаптирует стажировки под запросы молодых специалистов. «Почти треть наших разработчиков начинали со стажировки. Мы видим высокий спрос на бизнес-направления и расширяем программу», — говорит Марина Максимова, руководитель направления по работе с молодёжью.
Yandex Cup 2024: Регистрация на международный чемпионат по программированию открыта
Компания Яндекс объявила о старте приема заявок на международный чемпионат по программированию Yandex Cup 2024 с призовым фондом 12,5 млн рублей.
Яндекс объявил о старте регистрации на седьмой международный чемпионат по программированию Yandex Cup. В этом году турнир будет разделён на три категории: для начинающих и опытных программистов, для юниоров в возрасте от 14 до 18 лет и для сотрудников Яндекса, которые поборются за звание лучшего среди коллег. Призовой фонд чемпионата увеличен с 8,5 до 12,5 млн рублей.
Соревнования охватывают шесть направлений: аналитика, фронтенд и бэкенд-разработка, мобильная разработка, машинное обучение и «Алгоритм», ориентированный на спортивное программирование. В последнем участники могут выбирать между русским и английским языками, что открывает турнир для программистов по всему миру. Для юниоров доступны направления «Аналитика» и «Алгоритм» на русском языке.
Чемпионат Yandex Cup 2024 включает три этапа. С 14 по 20 октября пройдет онлайн-квалификация, 2 ноября — онлайн-полуфинал, а финал и церемония награждения состоятся с 2 по 6 декабря в Ташкенте. На этапе квалификации участники смогут попробовать силы в нескольких направлениях, а к полуфиналу выбрать одно.
Особенностью Yandex Cup 2024 станет Gold-финал, где победители всех категорий, включая юниоров и сотрудников Яндекса, будут бороться за звание абсолютного чемпиона в каждом направлении.
Зарегистрироваться можно на сайте турнира до 20 октября. Победители получат денежные призы, а участники с лучшими результатами в своих направлениях смогут пройти упрощённое собеседование в Яндексе.
Яндекс проводит программные соревнования с 2011 года. В 2023 году на участие в Yandex Cup подали заявки более 16 тысяч человек из 70 стран, а финал, прошедший в Алматы, собрал 120 участников из 16 стран.
Work-art balance: Яндекс и «Гараж» открыли осенний коворкинг на крыше Музея
Яндекс открыл коворкинг на крыше музея «Гараж». Он будет работать в течение месяца: тут будут всевозможные активности!
6 сентября Яндекс совместно с Музеем «Гараж» открыл новый коворкинг на крыше Музея современного искусства в Парке Горького. Это пространство объединило современные технологии и искусство.
Коворкинг рассчитан на 60 рабочих мест. Посетители могут не только работать, но и участвовать в карьерных консультациях, коуч-сессиях, паблик-токах, кинопоказах, играть в пинг-понг и настольные игры, слушать диджей-сеты — всё это в открытом пространстве с видом на парк.
На открытии выступила группа «нееет, ты что», известная своими треками в стиле джаз-хопа, фанка и экспериментального рока. О культурных и технологических аспектах Яндекса рассказали HR-директор Даша Золотухина и директор по развитию технологий Александр Крайнов.
В течение месяца в коворкинге будут проходить кинопоказы, публичные обсуждения и экспертные сессии по темам искусства и технологий, организованные Яндексом и «Гаражом». Среди спикеров — куратор выставок Яндекс Музея Александра Пучкова, руководитель развлекательных сервисов Яндекса Александр Сафронов, художник и пионер нет-арта Алексей Шульгин и другие. Кроме того, в библиотеке музея будет представлена специальная подборка книг на тему искусства и технологий.
Одним из мероприятий станет вечерняя партия настольной ролевой игры Dungeons & Dragons, которая продлится до закрытия музея.
Осенний коворкинг будет работать до 4 октября, доступ возможен по предварительной регистрации на сайте.
Яндекс Станция Дуо Макс: Алиса говорит и показывает, а также звонит по видео!
Алиса говорит и показывает: Яндекс Станция Дуо Макс — устройство с дисплеем, камерой и колонкой!
Сегодня компания Яндекс открыла предзаказ на Станцию Дуо Макс — умную колонку компании, оснащённую экраном и камерой. Правда это не первое устройство с дисплеем, в продаже уже есть телевизоры Яндекс ТВ Станция и Яндекс ТВ Станция Про, но сравнивать эти устройства сложно. Новое устройство будет стоить 42 990 рублей, а в свободной продаже Дуо Макс появится 5 декабря.
Станцией Дуо Макс можно управлять не только голосом, также можно будет делать это касаниями и жестами. При этом благодаря дисплею, который кстати поворачивается на 90 градусов, можно будет выводить информацию на экран, смотреть Яндекс Карты, а также видеоролики на YouTube через встроенный браузер или даже смотреть фильмы, сериалы и ТВ-передачи через приложение Кинопоиск.
Алиса сможет показывать на экране текст, фото, картинки и другую информацию, которая дополняет голосовой ответ. Колонка оснащена 10-дюймовым поворотным сенсорным экраном. Благодаря этому устройство легко впишется в интерьер, а пользователям будет удобно смотреть любой контент. Например, при просмотре сериала на Кинопоиске можно повернуть экран горизонтально, а при просмотре снятого на смартфон видео — вертикально.
А еще Станция Дуо Макс хорошо звучит: в оснговании колонки стоят два высокочастотных динамика и сабвуфер общей мощностью 60 Вт. Технология Room Correction адаптирует звук под акустику помещения. Если положение экрана меняется, звук автоматически подстраивается под конфигурацию устройства.
Также новая колонка призвана стать центром управления умным домом. Она снабжена модулем Zigbee и позволяет включать устройства и проверять их статус на сенсорном дисплее. К колонке можно подключать разнообразные датчики, лампочки и розетки. А если создать сценарий с Zigbee-устройствами, он будет работать даже без интернета — например, когда сработает датчик движения, включится свет.
Кроме этого тут есть камера (она оснащена физической шторкой (микрофон, кстати, тоже можно отключить), которая позволяет совершать видеозвонки в Telegram. Благодаря нейронному процессору, колонка может в реальном времени центрировать изображение, чтобы пользователь всегда был крупным планом: то есть речь идет об аналоге функции Central Stage от Apple.
Колонка доступна в бежевом, красном, зелёном и чёрном цветах и снабжена круговой LED-подсветкой у основания, благодаря ччему может казаться, что Станция Дуо Макс немного парит в воздухе.
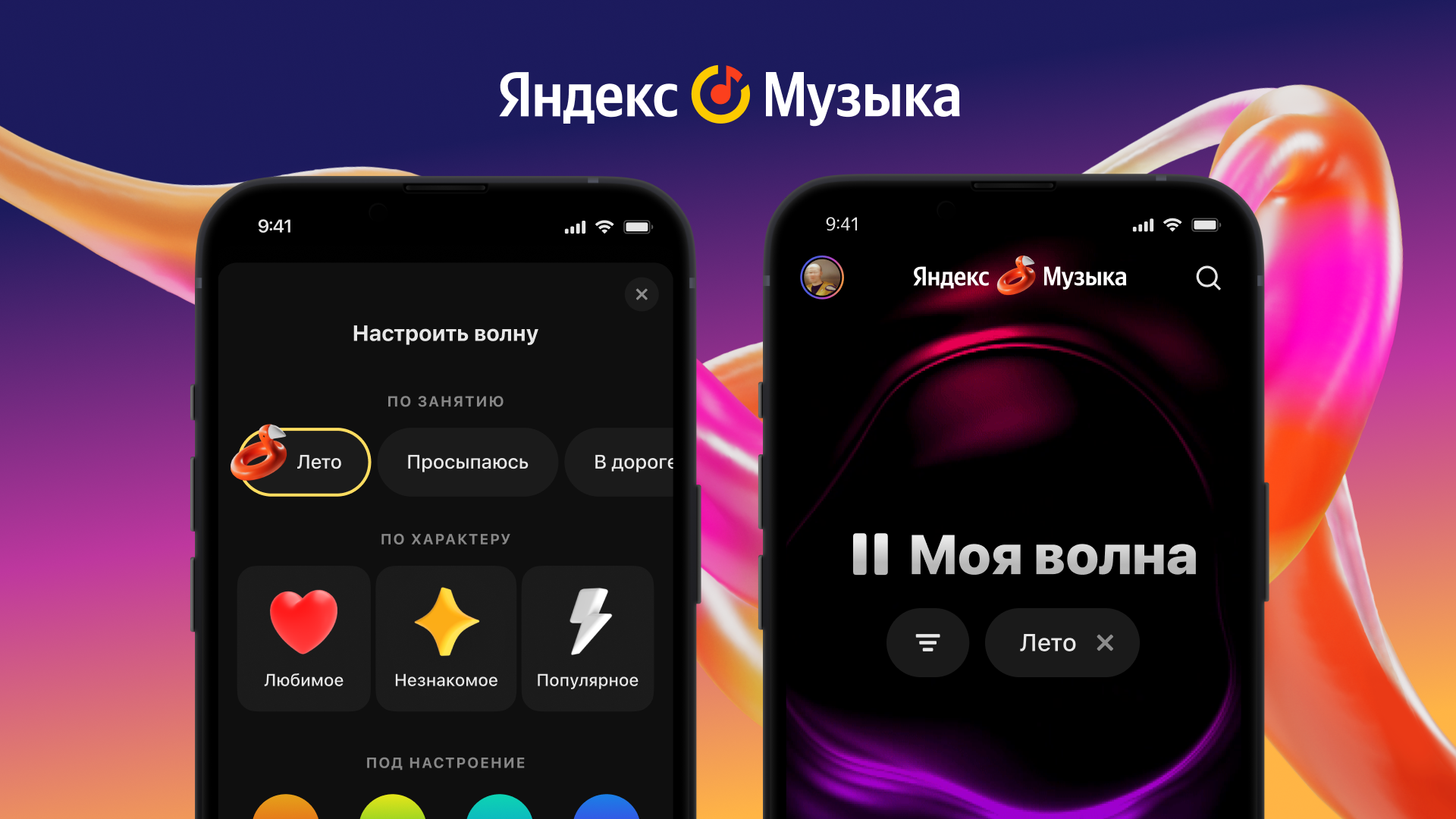
Яндекс Музыка запустила Мою волну «Лето»
Моя Волна стала теперь еще и летней: редакция Яндекс Музыки выбрала летние треки, чтобы почувствовать настроение самого жаркого периода года.
Команда Яндекс Музыки придумала, как определять, какую музыку считать летней, и запустила Мою волну «Лето» – бесконечный поток летней музыки.
Моя волна «Лето» появилась в результате объединения человеческой экспертизы, где редакция Яндекс Музыки определила, что такое летнее настроение в музыке, и работы системы персональных рекомендаций, которая анализирует, какие треки нравятся слушателю и формирует индивидуальный музыкальный поток.
Для запуска Моей волны «Лето» эксперты из редакции Яндекс Музыки определили общую концепцию летней музыки. Они проанализировали особенности в звучании треков, которые подписчики Яндекс Музыки слушают летом, летних хитов прошлых годов и новинок этого сезона, а также треков, которые ставят летом популярные радиостанции. На основе этих данных сработала система персональных рекомендаций, которая проанализировала показатели аудио каждого трека – жанры, мотивы, темпы и др., и выбрала, какие треки из каталога Яндекс Музыки можно считать летними.
В результате системой персональных рекомендаций было отобрано более 3,5 миллионов летних треков, которые Моя волна подбирает индивидуально для каждого пользователям в зависимости от его настроения и музыкальных предпочтений. Благодаря ей, классная музыка и летнее настроение будут сопровождать слушателей Яндекс Музыки везде – будь то офис, поездка на дачу или дни под зонтиком на пляже.
По случаю выхода Моей волны «Лето»» Яндекс Музыка обновила логотип внутри приложения, добавив в него фирменный знак в виде розового надувного фламинго. Обновление уже появилось на устройствах с операционной системой iOS и в скором времени появится на Android. Включить летнюю Мою волну можно на сайте и в приложении Яндекс Музыки – для этого нужно запустить Мою волну с главного экрана и в настройках выбрать «Лето», или сказать «летняя Моя волна» Яндекс Станции.
Яндекс Музыка поделилась статистикой: какие треки слушали пользователи в 2022 году?
По доброй традиции в декабре музыкальные сервисы делятся общими и персональными итогами года. Яндекс Музыка назвала самых популярных артистов.
Как и всегда в первых числах декабря музыкальные сервисы подводят итоги года. Сервис Яндекс Музыка проанализировал, что слушали пользователи в уходящем году, а
также собрал ключевые музыкальные тенденции. Персональная статистика и плейлисты с самыми прослушиваемыми треками года также стали доступны в приложении.
По наблюдениям сервиса, пользователи стали больше слушать музыку. Так, к концу года время прослушивания выросло до 29 часов в месяц. Это на 3 часа больше, чем в начале 2022 года. На это, прежде всего, повлиял запуск персональной рекомендательной системы – Моя волна. На данный момент больше половины дневной аудитории Яндекс Музыки слушают Мою волну, а среднее время прослушивания пользователями рекомендательного потока достигает более часа в день. Система рекомендаций помогает открывать пользователям новую музыку: ежемесячно из рекомендательного потока они добавляют к себе в коллекцию около 20 новых треков.
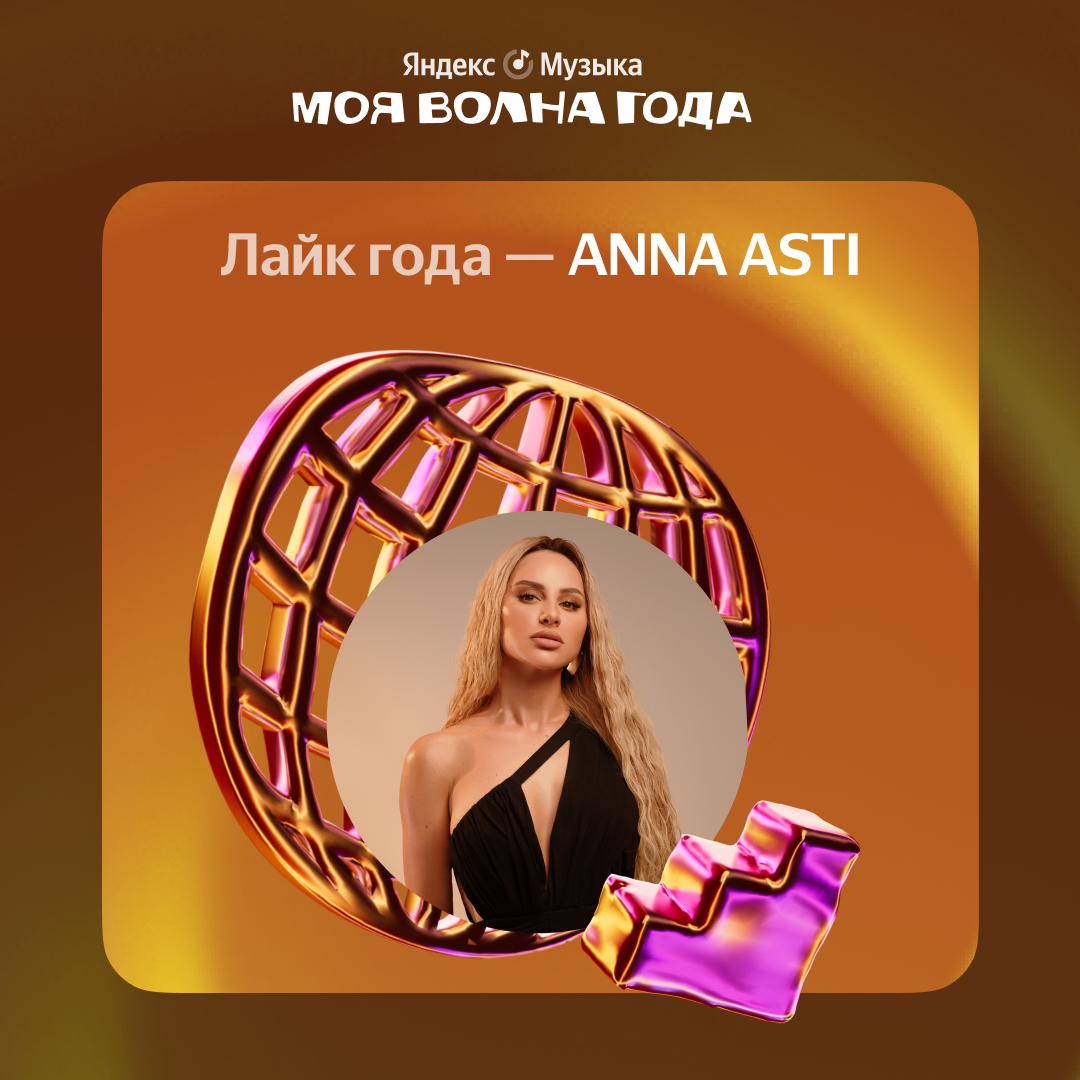
Лайк года — ANNA ASTI
В этом году ANNA ASTI начала свою сольную карьеру с трека «Феникс»: он вышел в январе 2022 года и до сих пор не покидает чарт Яндекс Музыки. Её треки набрали больше всего лайков в Моей волне.
Прорыв в Моей волне — INNA
Румынская певица, чьи песни становятся международными хитами, оказалась самой популярной в Моей волне. Ее треки в системе рекомендаций пользователи слушали в этом году больше всего.
Самый успешный альбом — Miyagi & Эндшпиль «HATTORI»
Сразу после выхода все треки нового альбома заняли верхние позиции в Суперлонче — в топе самых прослушиваемых новинок за первый уикенд. Альбом также побил рекорд «LAST ONE» от MORGENSHTERN, который ранее получил звание самого прослушиваемого альбома за выходные после релиза.
Самый зашеренный трек — ЕГОР КРИД и Михаил Шуфутинский «3 сентября»
Трек стал таким же популярным, как его предшественник — хит Михаила Шуфутинского. К слову, гуру шансона перезаписал припев популярной песни ради ремейка с Кридом.
Фрешмен года — Aarne
Aarne — музыкальный продюсер и битмейкер, чье творчество отражает весь диапазон трендовой музыки последних лет. Победу в номинации «Фрешмен года» продюсеру принес его дебютный альбом «AA LANGUAGE», который он готовил на протяжении нескольких лет. В альбом вошли 15 фитов почти со всей современной хип-хоп-сценой: в записи есть треки с Big Baby Tape, FEDUK, MORGENSHTERN, SLAVA MARLOW и многими другими.
Яндекс Музыка собрала для каждого пользователя личный плейлист «Мой 22-й» с его самыми прослушиваемыми треками в уходящем год. Персональная статистика за год также уже доступна подписчикам Плюса в приложении Яндекс Музыки. К предстоящим праздникам в Моей волне появилась новогодняя настройка. С ней рекомендательная система подберет новогодние композиции с учетом музыкальных вкусов каждого слушателя.
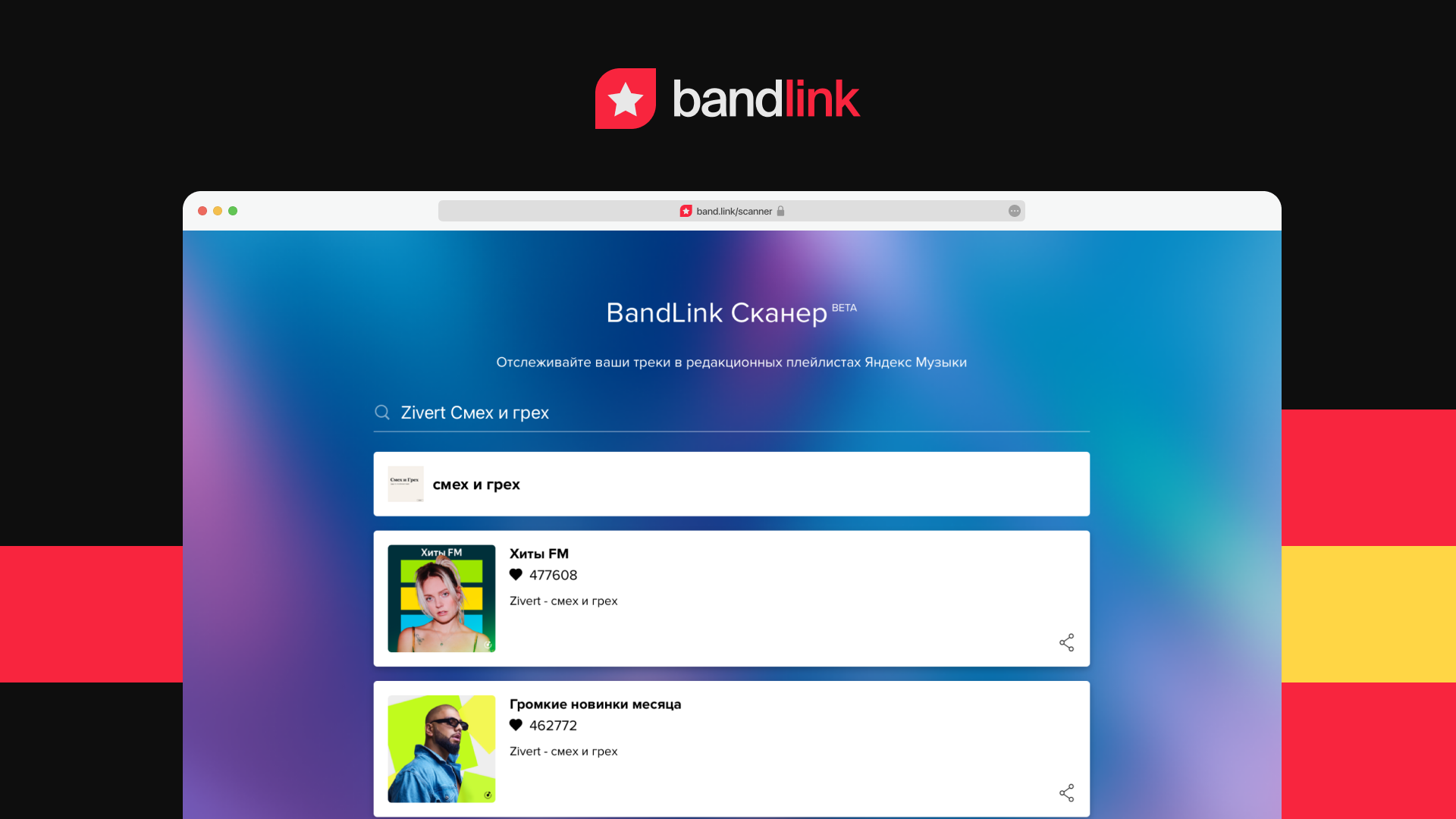
Сканер BandLink показывает артистам треки в плейлистах Яндекс Музыки
Сервис BandLink нужен музыкантам и их продюсерам. Сканер — удобное средство, чтобы понимать в какие плейлисты попадают новые треки…
Сервис продвижения творчества артистов BandLink запустил новый инструмент для музыкантов и их менеджеров. Теперь на главной странице BandLink есть раздел Сканер, в котором за несколько кликов можно получить полную картину поддержки треков артиста в плейлистах аудиостримингов. Сейчас Сканер показывает попадания в плейлисты Яндекс Музыки. В будущем он будет также показывать место трека в чарте Яндекс Музыки и попадания в плейлисты других аудиостриминговых площадок.
Для того, чтобы воспользоваться Сканером, нужно просто ввести имя артиста или название его трека в поисковую строку. После этого Сканер сразу покажет список редакционных плейлистов Яндекс Музыки, в которые попал трек артиста. Это может быть новый «Суперлонч», флагманский «Громкие новинки месяца», плейлист от верифицированных музыкальных сообществ (например, «Родного звука» или STUDIO21) или любой другой. Данные Сканера обновляются несколько раз в сутки, это помогает оперативно следить за
изменениями.
Сейчас Сканер доступен всем — даже незарегистрированным пользователям BandLink — в режиме бета-тестирования.
В «Кинопоиске» заметили, контент от Warner Bros. В формате «Скоро в подписке».
На стриминг-платформе «Кинопоиск» появятся третьи сезоны сериалов от Warner Bros. Может и до фильмов дойдет…
На днях пользователи сервиса «Кинопоиск» заметили, что на вкладке «Скоро в подписке» есть контент от Warner Bros, компания, которая ранее ушла из России. В этой владке увидели сразу четыре шоу, права на которые есть у Warner Bros: «Харли Квинн», «Пенниуорт», «Кунг-фу» и «Старгёрл».
В случае с каждым сериалом на «Кинопоиске» доступны первые два сезона (выходили ранее), но самое главное третий сезон шоу должен появиться «скоро». Правда никаких дат — не указывается.
Третий сезон сериалов «Пенниуорт» и «Кунг-фу» начались в октябре, а сериал «Старгёрл» пошел на свой третий сезон раньше — в конце августа. Сезоны выходят постепенно, в то время как третий сезон «Харли Квинн» уже полностью прошел.
«Кинопоиск» официально прокомментировал данную ситуацию: «Действительно, в подборке «Скоро в подписке» публикуется контент, который в ближайшее время появится на Кинопоиске. Кроме этого, на странице фильма или сериала можно увидеть ожидаемую дату публикации и расписание выхода серий. Чтобы не пропустить новинку пользователь может отметить её значком «Буду смотреть» – и найти её затем на экране «Моё» в онлайн-кинотеатре.»