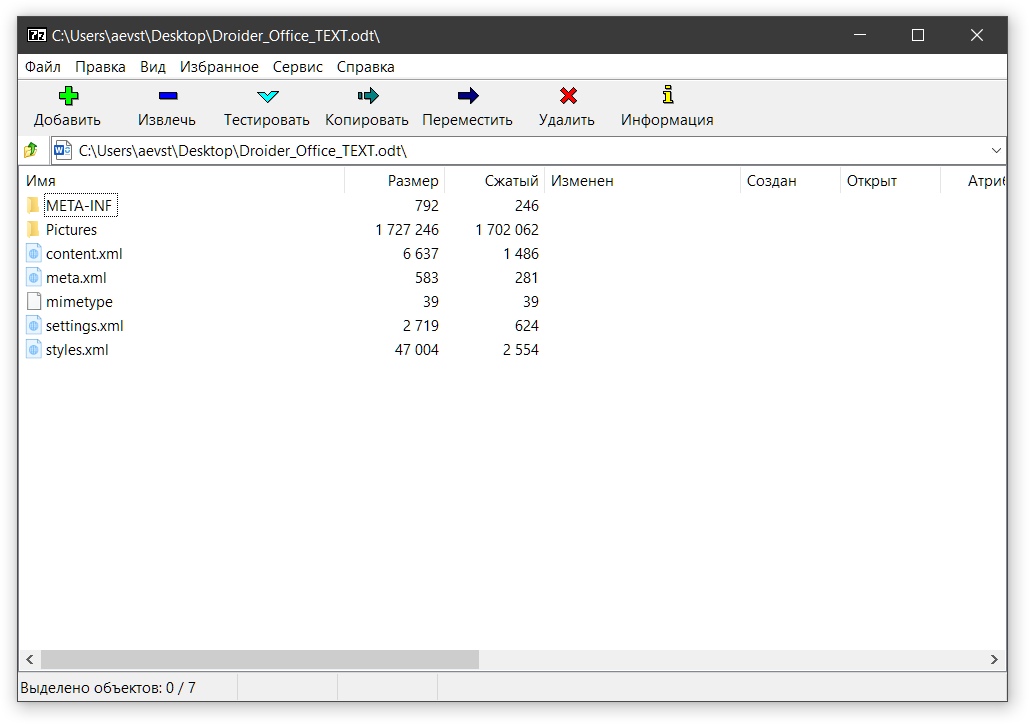
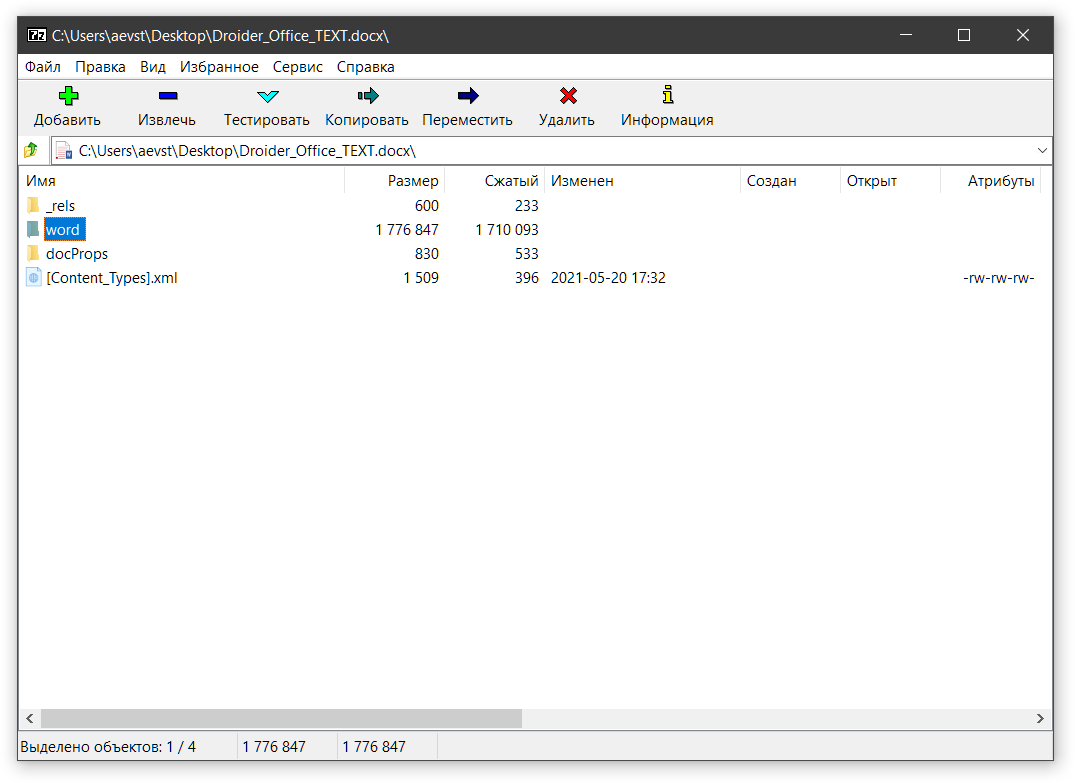
Мы постоянно видим текст на экране. Даже в YouTube вокруг ролика куча разных слов и буковок. Но мы редко задумываемся, как устроен компьютерный текст и почему он такой. Сегодня мы разберемся в компьютерных шрифтах.
Поговорим о том, зачем шрифту засечки? Научимся отличать готический шрифт от готского. Узнаем где Стив Джобс спрятал овцу? Разберемся в шрифтовых форматах и узнаем почему нам стоит отказаться от Times New Roman и Arial?
Введение в шрифты
Для начала давайте немного разберемся какие бывают шрифты и почему они такие.
Вообще классификаций шрифтов много и нет единой признанной, но именно компьютерные шрифты принято делить на две группы: с засечками и без.
Шрифты с засечками это Serif, что так и переводится с французского — засечки. Ну а sans serif — это буквально “без засечек”.
- sérif с фр. — засечки
- sans sérif с фр. — без засечек
Возьмем к примеру веб-дизайн. Когда нужно, чтобы текст был написан шрифтом без засечек, в коде указывают не только конкретный шрифт, скажем Arial, но и группу шрифтов sans serif.
Это нужно на случай если, к примеру, вы сидите на свободноом ПО, типа Ubuntu, где Arial или Helvetica у вас в системе нет. В этом случае автоматически подхватится шрифт без засечек, который у вас есть.

Но давайте на секунду отвлечемся и поговорим о том, откуда вообще появились засечки?
Антиква
Вообще, группу шрифтов с засечками в типографической среде называют не Serif, а Антиква и по названию уже чувствуется, что речь пойдёт про древность.
Жили-были финикийцы в 16-м веке до нашей эры. И был у них вот такой алфавит.

Это отец-прародитель всей европейской письменности. Кстати, буква алеф значит бык. Присмотритесь к пиктограмме, это голова быка которую повернули на бок, а потом и вовсе перевернули, и получилась буква А. И так с каждой буквой финикийского алфавита. Почитайте, это интересно.
Так вот, финикийцы писали быстро без всяких засечек и заглавных букв. Видимо, им было не до красоты.

Но потом появились римляне, а у римлян было много свободного времени. И начали они красиво выводить буквы на пергаменте тростниковым пером.
Штрихи получались разной толщины и чтобы как-то визуально сбалансировать форму, на концах букв римляне стали добавлять декоративные штришки, то есть засечки.

А потом еще выяснилось, что это не только красиво, но и удобно. Штришки визуально объединяют строки в линии. Отчего считается, что так удобнее читать большие объемы текста (но это научно не подтверждено). Зато на камне высекать хлесткие римские фразы строго по линиям, точно удобнее.


Но потом случилось Средневековье и появилось готическое письмо. А с украшательствами случился перебор. Выглядит классно, но читать такое невозможно. Вот, например, первая печатная книга — Библия Гутенберга 1455 года.


Поэтому в эпоху Возрождения люди опомнились. Начали переписывать античные тексты и заодно стали имитировать античную манеру писать, выводя красивые буквы с засечками. А называть тип письма стали Антиква, что значит “древний”.
Так что современные шрифты с засечками — это дань памяти древним римлянам, аккуратно выводящим красивые буквы пером на пергаменте.
Гротеск
Но, как говорится, всё идет по кругу. Поэтому в 19 веке от засечек потихонечку стали отказываться. Первым это сделал потомственный типограф с тотальным отсутствием вкуса Уильям Кэзлон IV.

И получилось у него не очень. Поэтому люди стали называть такие шрифты гротескными, то есть нелепыми или готскими, то есть варварскими. Поэтому в типографике шрифты без засечек называют, либо Grotesque, либо Gothic. В смысле готский, а не готический, не путайте.
- Grotesque — гротескный
- Gothic — варварский
Впрочем люди быстро заметили, что такие “нелепые” шрифты отлично подходят для крупных надписей в различных рекламах, плакатах, а позже для дорожных знаков, навигации на заводах и, конечно же, для дисплеев компьютеров.


Растровые шрифты
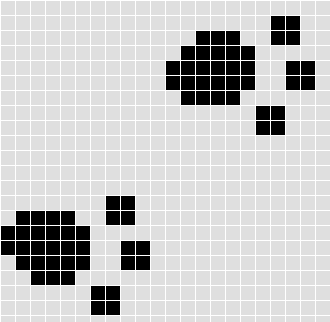
С появлением первых компьютеров шрифты пришлось придумывать заново. Дело в том, что мониторы первых компьютеров не отличались высоким разрешением. Оно даже измерялось не в пикселях (как сейчас), а в символах. При этом, на 1 символ отводилось 8х8 или 8х16 точек. А для нормального отображения векторного шрифта и разрешения нужно было повыше и мощей надо было побольше. Поэтому стали рисовать растровые шрифты, т.е. пиксельные.
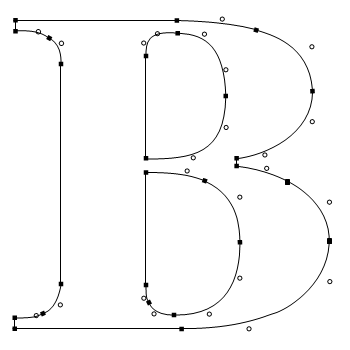
Такие шрифты приходилось рисовать по несколько раз для каждого размера. Кстати, несколько начертаний одного и тоже шрифта (жирный, тонкий, курсивный и так далее) называются гарнитурой.

Так вот одна из самых знаковых растровых гарнитур — это Chicago. Системный шрифт Macintosh с 1980-х по 1990-е годы, а также шрифт старых добрых iPod Classic.
![]()


Тут стоит отдать должное Apple, Стиву Джобсу и, конечно, дизайнеру Сьюзен Кэр. Буквам из нескольких пикселей сложно придать индивидуальность, поэтому системный шрифт мог получиться совершенно условным, но нет. Чикаго вышел прикольным и узнаваемым.

Да и другие растровые гарнитуры Macintosh, тоже получились прикольные. Более того, среди символов тех шрифтов дизайнеры умудрились разместили пасхалки. Так в шрифте Geneva можно найти символ овечки, а в Athens отпечатки лапок.

 Моноширинные шрифты
Моноширинные шрифты
Также помимо растровых шрифтов, компьютеры породили моноширинные шрифты.

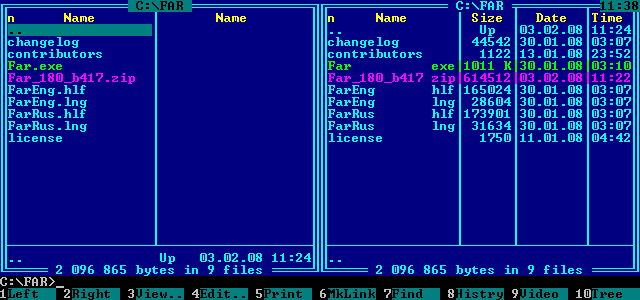
Обычно в шрифтах: разные символы имеют разную ширину. А в таких шрифтах все знаки, а точнее площади, которые занимают знаки, одинаковые по ширине.
Моноширинные шрифты, в первую очередь, используются в текстовых интерфейсах типа, Norton Commander, FAR и так далее. Такие моноширинные шрифты до сих пор используются в Linux в приложении Midnight Commander.
Postscript
Но в мире операционных систем постепенно текстовые интерфейсы стали сменяться графическими, а разрешения дисплеев и вычислительные мощности стали расти. Соответственно, растровые шрифты стали устаревать, ведь они не могли нормально масштабироваться. И поэтому их стали заменять векторными.
Но возникла другая проблема: нужно было разработать такую технологию, которая позволила бы векторному шрифту одинаково хорошо отображаться и на дисплее, и при печати. И такая технология была у компании Adobe и называлась она PostScript. Главной фишкой технологии были “хинтинги” (от слова hint — намёк, подсказка).
Это такие специальные программные инструкции, которые подсказывают, как нужно сгладить контур буквы, чтобы он шикарно отображался и при низком разрешении, и при мелком кегле.
Вот посмотрите, первая строка текста без хинтинга, а вторая с хинтингом. Разница на лицо.

Для своего времени технология была супер прорывной. Но возможно, Adobe так бы и не убедил рынок в том, что такая технология в принципе нужна. Если бы не Стив Джобс… В 1985 году продажи Macintosh начали падать, поэтому Apple нужна была киллер-фича, которую бы имели только компьютеры Apple. Стив Джобс инвестировал 2,5 млн долларов в Adobe и в компанию Aldus. Первая компания на эти деньги сделала PostScript-контроллер для принтера Apple LaserWriter, а вторая — программу PageMaker. Так компьютеры Apple первыми научились печатать рефераты для студентов. А PostScript стал стандартом в области допечатной подготовки. Строго говоря, PostScript — это язык программирования текста.
TrueType
Была только одна проблема. Технология хинтинга держалась в строжайшем секрете и использовалась только Adobe. Поэтому очень долгое время Abobe был единственным производителем высококачественных шрифтов. Тогда Apple и Microsoft объединили усилия и в 1991 году явили миру новую полностью открытую спецификацию спецификацию TrueType, поддержку которой добавили в MacOS и Windows 3.1.
TrueType умел почти всё тоже самое, что и PostScript, но только был полностью свободной и бесплатной технологией.
OpenType
Но и тут не обошлось без проблем: TrueType был безумно ресурсоемкий. Рендерить эти шрифты было мукой для компьютеров того времени. Поэтому в 1996 году Adobe и Microsoft замутили еще более продвинутый открытый шрифтовой формат — OpenType, в который добавили поддержку обеих технологий сглаживания, и TrueType, и PostScript, а также еще кучу фишек, типа поддержки всяких глифов, лигатур, дробей и прочих. Шрифты формата OpenType сегодня мы видим и на Linux, и на Windows, и на macOS.
Итого мы получили очень продвинутый и свободный шрифтовой формат, которым могут все пользоваться. За что мы можем сказать сказать спасибо будущим гигантам типа Adobe, Microsoft и Apple.
Лицензирование шрифтов
Но, всегда есть но. Компании стремились защитить свои результаты интеллектуальной деятельности и начали лицензировать шрифты. Это привело к тому, что использовать какие хочешь шрифты, к сожалению, нельзя.
Например, мы с вами привыкли, что в документах используются те же шрифты, что идут в комплекте с ОС Windows, но все эти шрифты проприетарные и платные. А проприетарные шрифты недоступны на многих смартфонах и на открытых ОС. И да, есть риск искажения форматирования.
XO Fonts
Поэтому в мире стали разрабатывать альтернативные свободные шрифты. В России одной из тех, кто взял на себя эту благородную ношу, стала компания-разработчик приложений МойОфис. Целый год они разрабатывали новые шрифты. И в 2016-м году на свет появилась первая версия шрифтового набора XO Fonts.
Набор XO Fonts — это метрические аналоги популярных гарнитур Times, Courier и тому подобное. Что это значит?
Метрический аналог — это оригинальный шрифт, символы которого занимают столько же места. Таким образом, при замене одного шрифта на его метрический аналог, верстка документа не поедет. И это касается всех начертаний шрифта: жирный, курсив, жирный курсив.
Новые гарнитуры XO Fonts были разработаны шрифтовым дизайнером Владимиром Чуфаровским и студией Letterhead совместно с командой МойОфис. А вот и ссылка на подробный рассказ с историей создания шрифтов XO Fonts.

В наборе в настоящее время 11 шрифтов в 24-х начертаниях. И все они используются в приложениях МойОфис: в текстовых, табличных, веб-редакторах и в мобильных приложениях. Все шрифты можно скачать по ссылке в описании и свободно использовать.

Более того, спустя два года после выхода первой версии XO Fonts в России внесли изменения в ГОСТы. И теперь (ГОСТ Р 7.0.97-201) вместо проприетарных Times New Roman и Arial «Для создания документов необходимо использовать свободно распространяемые бесплатные шрифты». Иными словами, теперь в России переходят на «свободно распространяемые» гарнитуры.
Но даже если ГОСТы вас не касаются, новые бесплатные шрифты в кириллице и латинице, да еще и в 24-х начертаниях — это ж просто подарок.