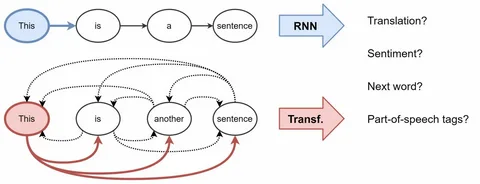
Ещё несколько лет назад имя Nvidia ассоциировалось прежде всего с геймерами, которые спорили на форумах о частоте кадров и объёме видеопамяти. Сегодня это имя произносят аналитики с Уолл-стрит, директора крупнейших корпораций и главы государств. По состоянию на июнь 2026 года рыночная капитализация компании колеблется в диапазоне от 4,9 до 5,3 триллиона долларов — в зависимости от дня торгов — и Nvidia уверенно удерживает звание самой дорогой публичной компании в мире. Для сравнения: совокупный объём экономики Германии — четвёртой по величине в мире — составляет около 4,5 триллиона долларов. Один производитель чипов стоит дороже, чем вся немецкая экономика. Как это стало возможным?
Ответ на этот вопрос — не просто история предпринимательского успеха. Это история о том, как правильно поставленная техническая задача, удачный момент и редкая дальновидность руководства способны изменить ход технологической цивилизации.
Трое инженеров и их большая ставка
В начале 1990-х годов индустрия компьютерных игр переживала бурный рост, однако до превращения в многомиллиардный бизнес, конкурентоспособный по масштабу с кинематографом, ей оставалось ещё около десяти лет. Именно в этот период трое американских инженеров увидели в игровой графике нечто большее, чем развлечение.

В апреле 1993 года в Саннивейле, штат Калифорния, была основана компания Nvidia. Её создателями стали Дженсон Хуанг, Крис Малаховский и Кёртис Прием — на тот момент уже состоявшиеся специалисты в области компьютерных технологий. Трёхмерные игры набирали популярность, а рынок графических ускорителей только зарождался. Цель была сформулирована просто: создать чип, который сделает видеоигры более реалистичными и доступными. Никто тогда и не предполагал, что эти чипы однажды выйдут далеко за пределы индустрии развлечений.

Стоит развеять распространённое заблуждение: Nvidia не изобретала видеокарты. Первый трёхмерный видеоускоритель был создан компанией IBM ещё в 1982 году. В 1990-х на этом рынке уже действовали такие игроки, как IBM, Matrox и 3Dfx. Nvidia была одной из многих — и поначалу ничто не предвещало её будущего триумфа.
Первый провал и первое спасение
В мае 1995 года, спустя два года разработки, Nvidia представила свой дебютный продукт — мультимедийную плату STG 2000 на базе чипа NV1. Карта объединяла трёхмерный ускоритель, блок обработки двухмерной графики и звуковую карту в одном устройстве. Она работала с четырёхугольными примитивами — по аналогии с популярными тогда приставками Sega Saturn. Несколько игр с этой консоли, в частности Virtua Fighter и Panzer Dragoon, были даже портированы под ПК с поддержкой STG 2000.

Однако практически сразу после выхода первого продукта Microsoft представила программный интерфейс DirectX, ориентированный на работу с треугольными полигонами. Это стало приговором для NV1: принцип ускорения графики в чипе Nvidia принципиально расходился с новым стандартом. Карта оказалась несовместима с подавляющим большинством игр, в которые хотели играть пользователи персональных компьютеров.

Молодая компания оказалась на краю гибели. На создание первого продукта был потрачен почти весь венчурный капитал. Дженсону Хуангу пришлось провести масштабные сокращения. В один из критических моментов в кассе компании оставалось денег ровно на один месяц выплаты зарплат.

Nvidia выжила. И это выживание само по себе стало стратегическим уроком: компания перестала изобретать собственные стандарты там, где отрасль уже сделала выбор, и сосредоточилась на том, чтобы создавать лучшие продукты в рамках существующей экосистемы.
Прорыв, который изменил правила игры
В 1997 году Nvidia выпустила карту RIVA 128, уже совместимую с DirectX 5 и OpenGL 1.0. Это был первый по-настоящему массово востребованный продукт компании. Карта предлагала обработку двухмерного и трёхмерного изображения в одном устройстве, тогда как конкурирующий Voodoo Graphics от 3Dfx Interactive для полноценной работы требовал отдельной двухмерной карты.

Но подлинная революция произошла в 1999 году с выпуском GeForce 256. Nvidia позиционировала его как первый в мире «графический процессор» — термин, который впоследствии вошёл в профессиональный лексикон всей индустрии. GeForce 256 впервые объединил в одном чипе обработку геометрии, освещения и текстур. Он не являлся абсолютным лидером по мощности, однако предлагал исключительное соотношение цены и производительности. Грамотный маркетинг сделал остальное: Nvidia заняла лидирующие позиции на рынке и впервые привлекла к себе внимание не только геймеров, но и крупных разработчиков программного обеспечения.
Поле битвы: рынок графических процессоров
В начале 2000-х годов компания развивалась стремительно. В 2002 году Nvidia приобрела активы 3Dfx Interactive — одного из своих ключевых соперников, — окончательно сформировав дуополию на рынке дискретных видеокарт.

К тому времени на рынке графических процессоров сложился треугольник лидеров: Nvidia, Intel и ATI. Однако Intel после неудачного запуска ускорителя i740 предпочла сосредоточиться на встроенной графике и других направлениях. На арене остались двое.
В 2000 году ATI выпустила серию Radeon, и между компаниями развернулась острая конкуренция. Nvidia обеспечила себе контракт с Microsoft на поставку графики для первой Xbox, однако впоследствии Microsoft перешла к ATI. Невзирая на это, Nvidia быстро переориентировалась: заключила партнёрские соглашения с Sony и Apple, став эксклюзивным поставщиком видеочипов для консолей PlayStation и компьютеров Macintosh. Среди нестандартных партнёрств того периода выделяется сотрудничество с Audi — Nvidia поставляла графические чипы для информационно-развлекательных систем немецких автомобилей.

В 2005 году компания провела ещё один стратегический манёвр: приобрела ULi Electronics, ключевого поставщика чипсетов для ATI. Позднее ATI объединилась с AMD и продолжила борьбу уже в новом составе. Существует версия, что AMD в своё время намеревалась купить саму Nvidia, однако Дженсон Хуанг отказался от сделки. Противостояние Nvidia и AMD на рынке дискретных видеокарт продолжается по сей день — уже почти двадцать лет.
Поворотный момент: параллельные вычисления и рождение CUDA
Компания могла остановиться на достигнутом. Рынок видеокарт был завоёван, конкуренты оттеснены. Но именно тогда Nvidia сделала шаг, который в конечном счёте и предопределил её нынешнюю стоимость.

Руководство компании обратило внимание на архитектурную особенность графических процессоров: в отличие от центральных процессоров, состоящих из нескольких мощных ядер, GPU строится на тысячах небольших ядер, предназначенных для одновременного решения множества однотипных задач. Именно такая архитектура делает его идеальным инструментом для параллельных вычислений.
В 2007 году Nvidia представила платформу CUDA (Compute Unified Device Architecture), открывшую возможность использовать вычислительную мощность видеокарт не только для рендеринга графики, но и для любых задач, традиционно выполнявшихся центральным процессором. Разработчики получили возможность писать программы для GPU на стандартных языках программирования — C и C++.

Поначалу технология привлекала лишь узкий круг специалистов. Но в 2012 году произошло событие, которое изменило всё.

На конкурсе ImageNet Large Scale Visual Recognition Challenge — своеобразном чемпионате мира среди алгоритмов распознавания изображений — победила нейронная сеть AlexNet, обученная на вычислительных мощностях чипов Nvidia с использованием CUDA. Результат был настолько убедительным, что в академическом сообществе не осталось сомнений: будущее искусственного интеллекта связано с графическими процессорами. Примечательно, что одним из создателей AlexNet был Илья Суцкевер — впоследствии сооснователь OpenAI и один из наиболее влиятельных исследователей в области искусственного интеллекта.
Архитектура интеллекта: что стоит за мощью чипов Nvidia
Понимая, что рынок искусственного интеллекта открывает исторические возможности, Nvidia приступила к активным инвестициям в специализированное программное обеспечение и библиотеки для машинного обучения — в частности, cuDNN и TensorRT. Эти инструменты позволяют ускорять и оптимизировать процессы глубокого обучения, существенно упрощая разработку систем искусственного интеллекта.

Одним из ключевых нововведений стали тензорные ядра (Tensor Cores) — специализированные вычислительные блоки внутри GPU, оптимизированные для операций с тензорами. Тензор — математический объект, обобщающий понятия скаляра, вектора и матрицы на произвольное число измерений. В задачах машинного обучения данные представляются именно в тензорной форме: пиксель изображения, например, описывается трёхмерным тензором с осями по горизонтали, вертикали и цветовым каналам. Операции над такими структурами составляют основу глубокого обучения, и тензорные ядра Nvidia оптимизированы именно для них.

В 2020 году компания представила карту A100 на архитектуре Ampere — 6 912 вычислительных ядер CUDA, 432 тензорных ядра и до 80 гигабайт памяти. В задачах искусственного интеллекта A100 превосходила своих предшественников до двадцати раз. Эта карта немедленно стала стандартом в самых современных вычислительных центрах мира.
Следующим шагом стала H100 на архитектуре Hopper, ещё более нарастившая отрыв от конкурентов. Именно эти чипы оказались в центре «золотой лихорадки» искусственного интеллекта: когда ChatGPT в конце 2022 года вызвал взрывной интерес к генеративным технологиям, выяснилось, что для обучения и работы подобных систем нужны прежде всего чипы Nvidia. Компания оказалась единственным массовым поставщиком «лопат» в новой технологической золотой лихорадке.

В 2024 году Nvidia анонсировала архитектуру Blackwell — следующее поколение GPU для задач искусственного интеллекта. Флагманский чип B200 содержит 208 миллиардов транзисторов, поддерживает 192 гигабайта памяти HBM3e и в сочетании с центральным процессором Grace образует суперчип GB200. По данным компании, система GB200 NVL72 — стойка из 72 чипов Blackwell — обеспечивает производительность при инференсе крупных языковых моделей до 30 раз выше, чем H100, при потреблении энергии в 25 раз меньше.
Цифры, которые переписывают историю
В мае 2023 года рыночная капитализация Nvidia впервые превысила 1 триллион долларов. В феврале 2024 года компания преодолела отметку в 2 триллиона. В конце 2025 года Nvidia стала первой компанией в истории, достигшей капитализации в 5 триллионов долларов. По состоянию на начало июня 2026 года стоимость компании колеблется в районе 5 триллионов долларов, удерживая звание крупнейшей публичной компании в мире — опережая Apple, Microsoft и Saudi Aramco.

За последние двенадцать месяцев капитализация Nvidia выросла более чем на 60%. Темп, не имеющий прецедентов среди компаний подобного масштаба.
Во многом этому способствовал ChatGPT и последовавший за ним повсеместный интерес к генеративному искусственному интеллекту. Сегодня практически каждый технологический стартап, претендующий на революцию в той или иной отрасли, строит свою инфраструктуру на чипах Nvidia. Компания не только поставляет оборудование: она активно сотрудничает с университетами и исследовательскими группами, обеспечивая академическое сообщество доступом к своим ресурсам и формируя лояльность следующего поколения разработчиков.

Немаловажную роль играет и то, что Nvidia остаётся fabless-компанией — то есть не имеет собственного производства. Она разрабатывает архитектуры и технологии, тогда как физическое изготовление чипов передаётся партнёрам — прежде всего тайваньской TSMC. Это позволяет концентрировать ресурсы исключительно на интеллектуальной составляющей бизнеса.
Тень успеха: регуляторное давление
Столь стремительный взлёт неизбежно привлёк внимание регуляторов. Министерство юстиции США в 2024 году инициировало антимонопольное расследование в отношении Nvidia. Следователей заинтересовало, не оказывает ли компания давление на покупателей, вынуждая их приобретать исключительно её продукты, и не устанавливает ли повышенные цены на сетевое оборудование для тех клиентов, которые одновременно закупают чипы у конкурентов — AMD или Intel. Помимо этого, расследованию подверглось приобретение израильского стартапа Run:ai за 700 миллионов долларов: регуляторов насторожило, не было ли целью сделки подавление технологии, способной снизить спрос на GPU.

Антимонопольные претензии к Nvidia предъявляют и за рубежом. Французский регулятор — Autorité de la Concurrence — провёл обыски в офисах компании ещё в сентябре 2023 года и впоследствии констатировал признаки злоупотребления доминирующим положением. Китайское ведомство по регулированию рынка в сентябре 2025 года объявило о продолжении расследования в отношении Nvidia.
Сама компания настаивает на том, что её успех обусловлен исключительно качеством продуктов и десятилетиями инвестиций в исследования и разработки, и заявляет о готовности к полному сотрудничеству с регуляторами.

Антимонопольные разбирательства — не первое серьёзное испытание для Nvidia. Компания уже переживала момент, когда её судьба висела на волоске после первого же продукта. Она выстояла. И есть все основания полагать, что она выстоит снова.
Больше чем чипы
Сегодня Nvidia — это уже не просто производитель видеокарт. Это компания, чья инфраструктура лежит в основе современного искусственного интеллекта: от обучения крупнейших языковых моделей до систем автономного вождения, от медицинской диагностики до моделирования климата.

Технологии трассировки лучей (ray tracing) и алгоритм масштабирования DLSS кардинально изменили облик современных видеоигр. Платформа CUDA стала стандартом де-факто для научных вычислений. Архитектура Blackwell открывает возможности для моделей с триллионами параметров, которые ещё несколько лет назад казались недостижимыми.
Дженсон Хуанг основал компанию с целью сделать видеоигры красивее. Три десятилетия спустя его детище формирует инфраструктуру, на которой строится следующий этап технологического развития человечества.

История Nvidia — это напоминание о том, что величайшие технологические революции нередко начинаются не с грандиозных деклараций, а с очень конкретного технического решения, принятого в нужный момент нужными людьми