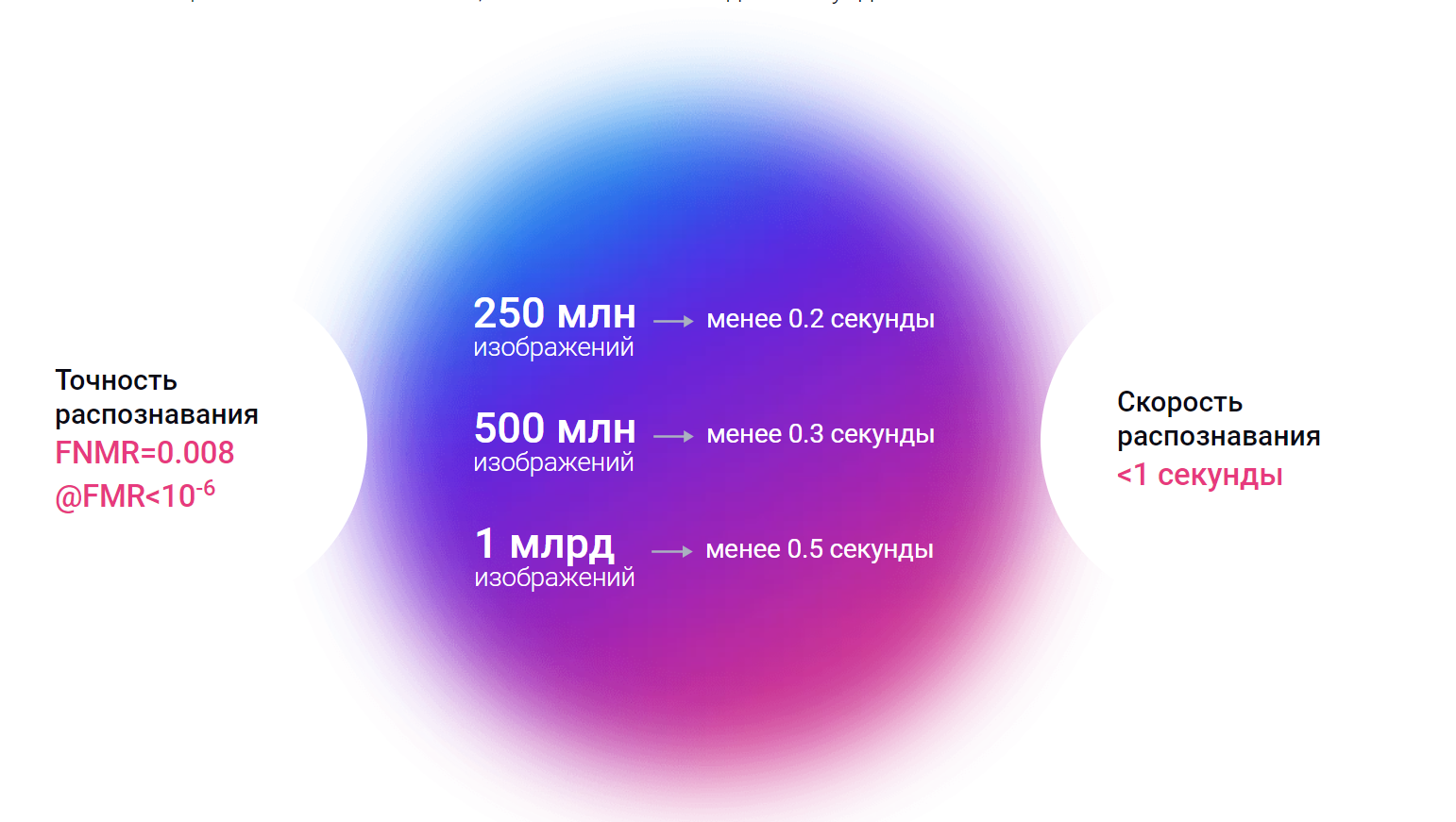
Среднестатистический человек может идентифицировать знакомое лицо в толпе с точностью 97,53%. Вы скажете, это немало и будете правы. Но это ничто по сравнению с современными алгоритмами, которые добились точности 99,8% еще в 2014 году. А в последние несколько лет они достигли практически совершенства! Современный алгоритм, использующийся в камерах видеонаблюдения в Москве способен обрабатывать 1 миллиард изображений менее чем за полсекунды с точностью близкой к 100%.
Этот алгоритм насколько крут, что уже в этом году в Московском Метро планируют ввести систему прохода по лицу — FacePay. При этом нам обещают, что система будет работать даже если человек в медицинской маске.
Как вы понимаете, жизнь уже не будет прежней. Поэтому давайте разберемся:
- Как работают алгоритмы распознавания лиц?
- Страшны ли эти алгоритмы на самом деле и где их применяют во благо?
- А также поговорим какого будущего нам ждать.
Причины
Технологии машинного зрения и распознавания лиц развивались очень активно с середины прошлого века. Но только сейчас стали по-настоящему хорошо работать. Причин тому три штуки:
- Появились действительно мощные компьютеры, способные справиться с задачей. За это спасибо закону Мура.
- Появились базы данных с нашими с вами фотографиями. За что спасибо социальным сетям.
- Ну и конечно, произошел прорыв в области нейросетей.
Все эти события позволили создать практически идеальные алгоритмы распознавания лиц. Так давайте же разберемся, как они работают.
Этап 1. Обнаружение
В первую очередь, для того, чтобы лицо распознать, надо его сначала обнаружить. Задача на самом деле не тривиальная. Для этого мы бы могли использовать натренированные нейросети, но это слишком долго, дорого и ресурсоемко. Поэтому для обнаружения лица используется очень простой метод Виолы — Джонса, разработанный еще в 2001 году.
Как эта штука работает?
Этот алгоритм просто сканирует изображение при помощи вот таких прямоугольников, они называются примитивами Хаара:

И еще вот таких прямоугольников:
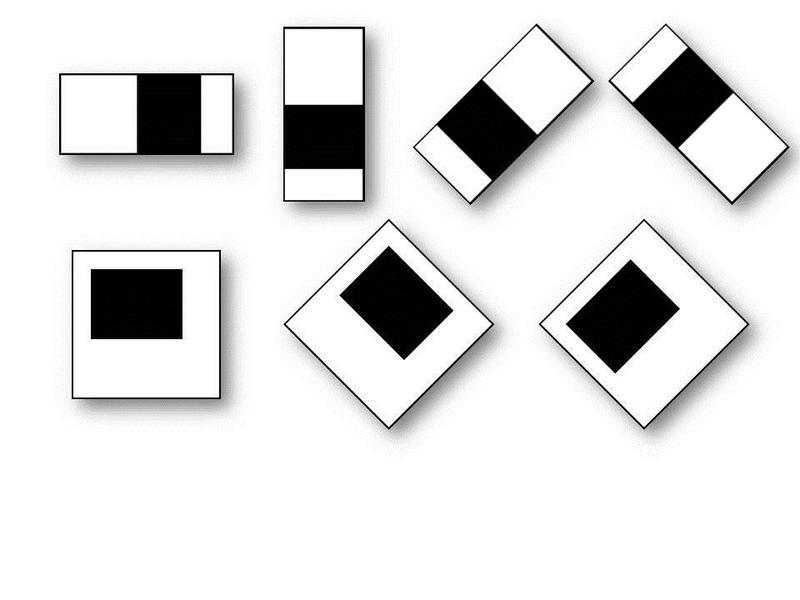
Задача этих объектов — находить более светлые и темные области на изображении, характерных конкретно для человеческих лиц.
Например, если усреднить значения яркости область глаз будет темнее щек или лба, а переносица будет светлее бровей.

В общем таких характерных признаков много и естественно не только у человеческих лиц могут быть подобные паттерны. Поэтому алгоритм работает в несколько этапов:
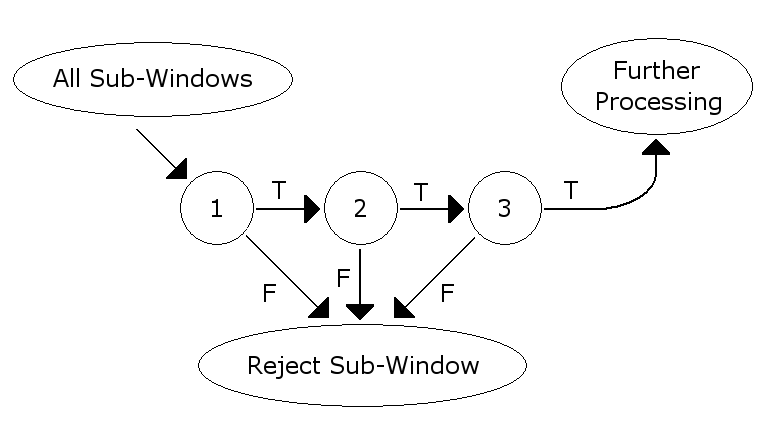
Сначала находится первый признак, система понимает: «В этой области может быть лицо». Тогда она начинает там же искать второй признак, а потом третий. И если в одной области найдено 3 признака, уже можно уверенно сказать — да, это лицо! После чего система получает область изображения, в котором есть только лицо.
Этап 2. Антропометрические точки
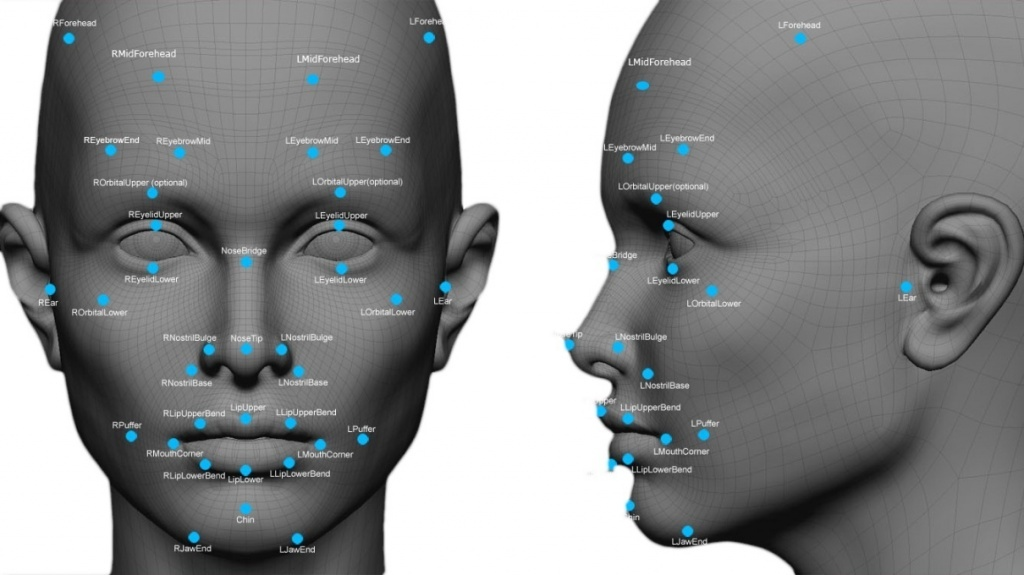
Получив область для анализа, дальше в дело вступает главный секрет каждой системы распознавания — биометрический алгоритм.
Он расставляет на лице антропометрические точки, по которым впоследствии и будут вычисляться индивидуальные характеристики человека: разрез глаз, форма носа, подбородка, расстояние между ними и прочее. Таких признаков может быть много, вплоть до нескольких тысяч. Но в целом, таких точек должно быть как минимум 68.
Этап 3. Исправление искажений
А дальше начинается настоящая магия. В идеале нам нужно лицо, которое смотрит анфас, то есть прямо в камеру. Но такая удача бывает редко, особенно если речь идет о распознавании человека в толпе.
Поэтому система производит дополнительное преобразование изображения: устранятся поворот и наклон головы. А также проводится 3D-реконструкция лица из 2D-изображения. Таким образом, даже если человек на изображении смотрел вбок, мы всё равно можем получить четкий фронтальный снимок, что существенно повышает качество распознавания.

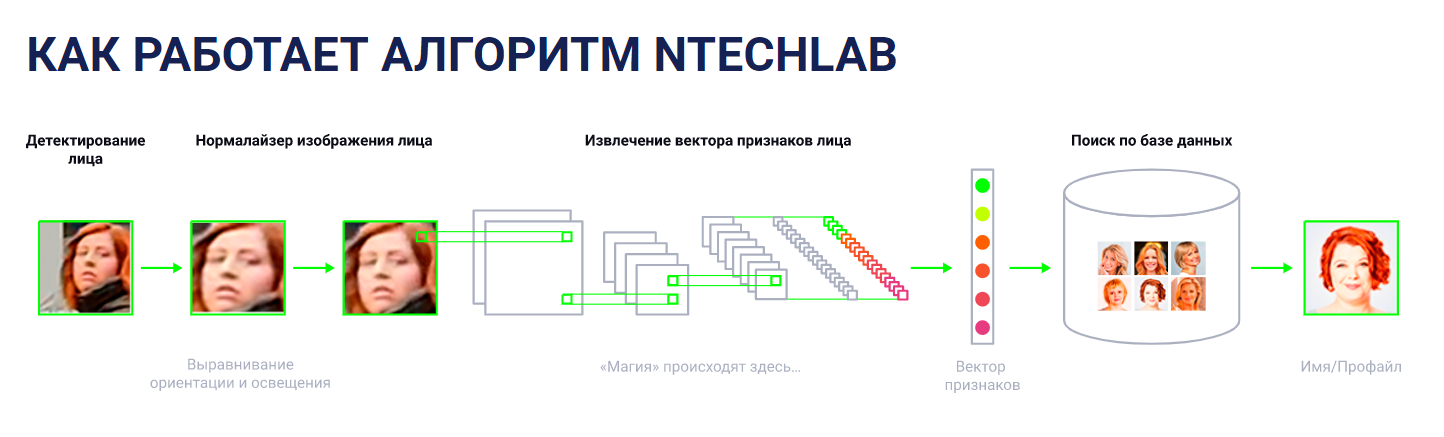
Этап 4. Вектор лица
Ну а дальше происходит самое главное. В бой вступает нейросеть, которая присваивает каждому лицу вектор признаков. Что это такое?
По сути, это просто какое-то число, которое складывается из суммы характеристик лица: расстояний между опорными точками, текстуры определенных областей на лице и прочее. Таких характеристик может быть множество. Основное правило: они должны описывать лицо независимо от посторонних факторов: макияжа, прически, возрастных изменений.
Этап 5. Идентификация
Ну а дальше остаётся сравнить полученный вектор с базой других векторов. И готово. Система вас идентифицировала.

Где и как используется?
Помимо очевидных кейсов применения, помимо обнаружения правонарушителей в общественных пространствах и оплаты билетов в метро. Где и как могут применяться эти технологии?
Во-первых, системы могут быть настроены не на идентификацию а на анализ поведения или настроения. В такси можно можно быстро вычислять неадекватных водителей или пассажиров. В магазинах, можно находить грустных покупателей и повышать уровень сервиса. Ритейлеры одежды или продуктовые магазины используют камеры для анализа поведения покупателя, чтобы проанализировать настроение покупателя на кассе. Или например в школах, можно искать скучающих детей и корректировать программу обучения. Так, кстати уже делают в Китае. Вот такой мир будущего, и мы уже в нём живём не зная этого.
Cisco
Также есть просто огромный пласт применения в бизнесе. К примеру, Cisco активно использует распознавание лиц в своих продуктах для конференций и совместной работы. Например, Cisco Webex умеет распознавать лица сотрудников на больших общи[ онлайн-конференциях и подписывать их имена, что очень полезно для крупных компаний.
Но самая крутая фича — это People Focus. Эта технология распознает лица и силуэты людей и оптимально подстраивает верстку приложения, чтобы всех было видно. И даже если в кадре сидят несколько человек, они всё равно будут распознаны и показаны в отдельном окошке с указанием имени. Вот бы в умные очки такую фичу!
Также распознавание лиц, активно используется не только в приложении Webex, но и в различных Webex-устройствах: это различные умные экраны, моноблоки, веб-камера и прочее оборудование, которое используется в переговорных, конференцзалах или даже индивидуальные кабинеты.
Так при помощи Webex-устройств можно считывать эмоции сотрудников на собраниях, собирать статистику о посещениях и реакции и много всего другого. В общем, ребята точно опережают время в корпоративном секторе.
Что будет в будущем?
Чего же нам ждать в будущем? Распознавание лиц для разблокировки iPhone, входа в Windows или во время конференций — это прекрасная, удобная технология, упрощающая жизнь и мы уже ей пользуемся. Но вот повсеместные камеры наблюдения в городах рисуют в воображении самые мрачные картины в духе Джорджа Оруэлла.
Отсюда возникает вопрос — можно ли защитить себя от систем видеонаблюдения? Конечно, с развитием технологий развиваются и средства обхода этих технологий.
Люди придумывают макияж и украшения, которые сбивают с толку алгоритм обнаружения лиц, тот самый из 2001 года, создают инфракрасные очки, засвечивающие сенсоры камер, а также делают всякую криповую одежду и маски.





Но по большому счету такой лук скорее больше привлечет внимания, а алгоритмы подстроятся под обманки. Поэтому единственный способ защиты — это закон. Бизнес активно не внедряет системы распознавания лиц только потому, что это несет большие юридические издержки. В ЕС активно разрабатывается новый закон, который уже прозвали GDPR 2: он будет строго регулировать системы распознавания лиц и прочие системы искусственного интеллекта, вызывающие законные опасения.
В России с этим пока что не так хорошо. Тем не менее отечественные компании, которые присутствуют на международном рынке также будут вынуждены соблюдать новые правила игры, как произошло с первым GDPR.

То есть, как вы поняли, есть светлая сторона технологии, которая упрощает нам жизнь и темная, что приближает нас к миру большого брата.







:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/63710235/netflix-prize1.0.1537040369.0.jpg)