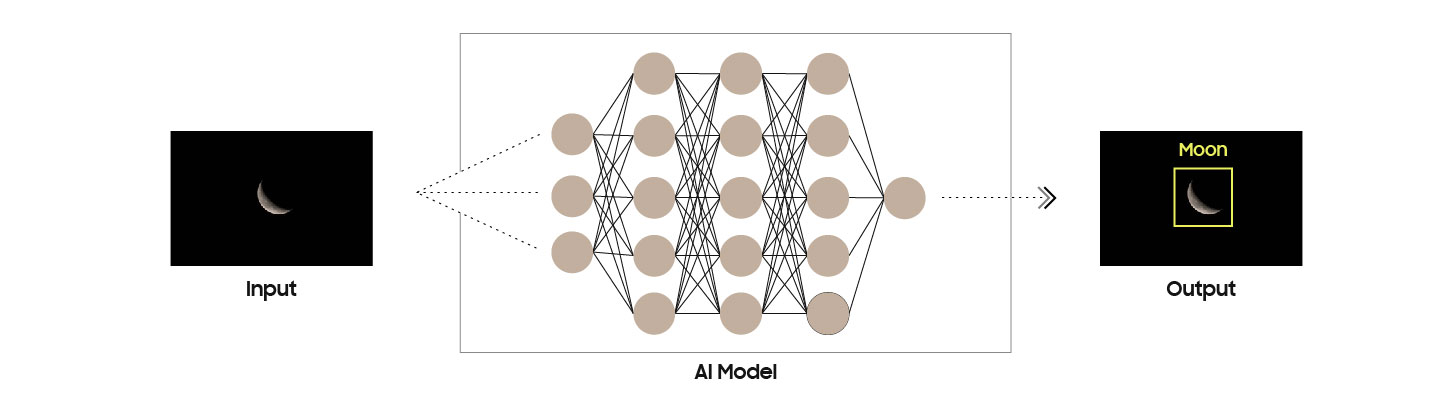
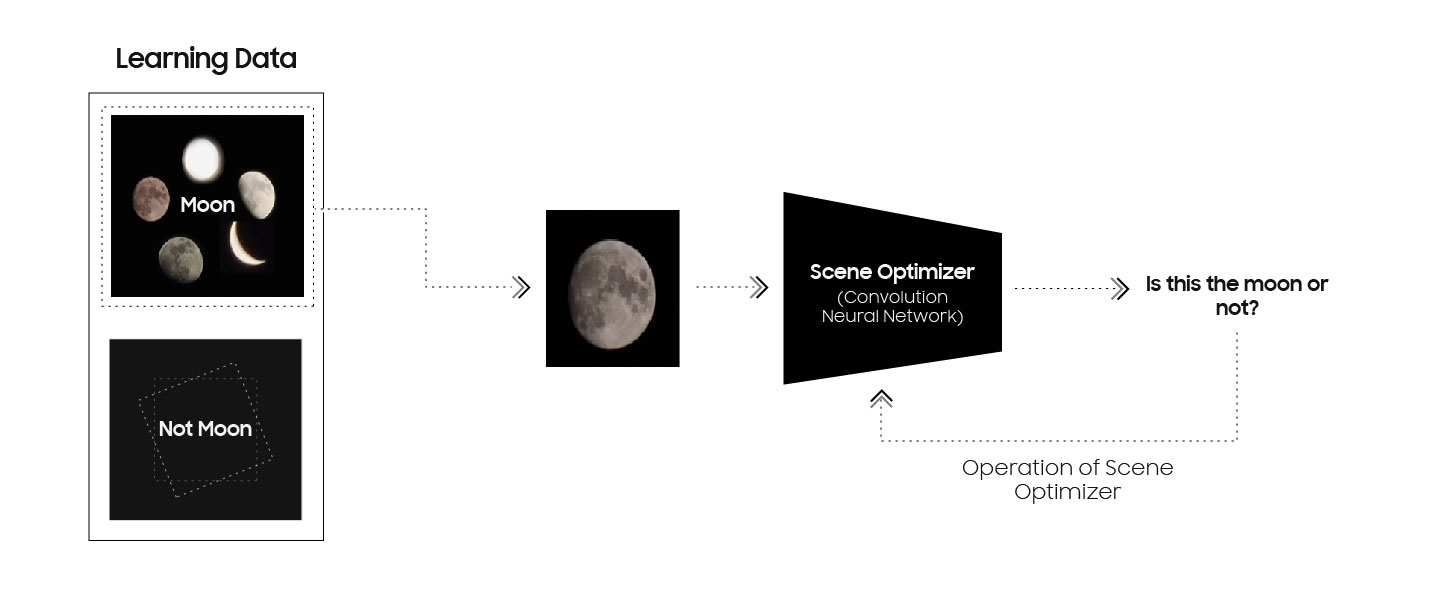
ChatGPT и другие языковые модели поражают воображение. Они способны поддерживать беседу, писать код, объяснять квантовую физику. Они знают больше и думают быстрее, чем любой человек. Но при всей этой мощи у них есть одна фундаментальная проблема: они не понимают, как устроен реальный мир.
Они никогда не жили в нём. Не чувствовали тяжесть предметов, тепло и холод, запах дождя. И главное — не понимали последствий своих действий. У них есть знания о мире, но нет опыта жизни в нём.
Именно поэтому появилась идея создания мировой модели — внутреннего представления о физической реальности, которое позволит ИИ не просто знать об этом мире по описанию из интернета, а понимать его на собственном опыте. И возможно, когда такая модель будет создана, ИИ обретёт нечто большее, чем умение писать код и разговаривать. Он обретёт сознание.
Но разве можно создать такую модель? Можно. И этим уже занимается компания NVIDIA и её проект — Cosmos, который был представлен на CES 2025 в начале января и получил крупное обновление в марте 2025 года.
Эмерджентность: может ли неживое стать живым?
Чтобы понять, куда движется NVIDIA, нужно вернуться в 2017 год. Трое инженеров из OpenAI — тогда ещё малоизвестной некоммерческой организации — тренируют очередную языковую модель на отзывах с Amazon. Задача банальная: научить ИИ предсказывать следующий символ в тексте. Ничего необычного.
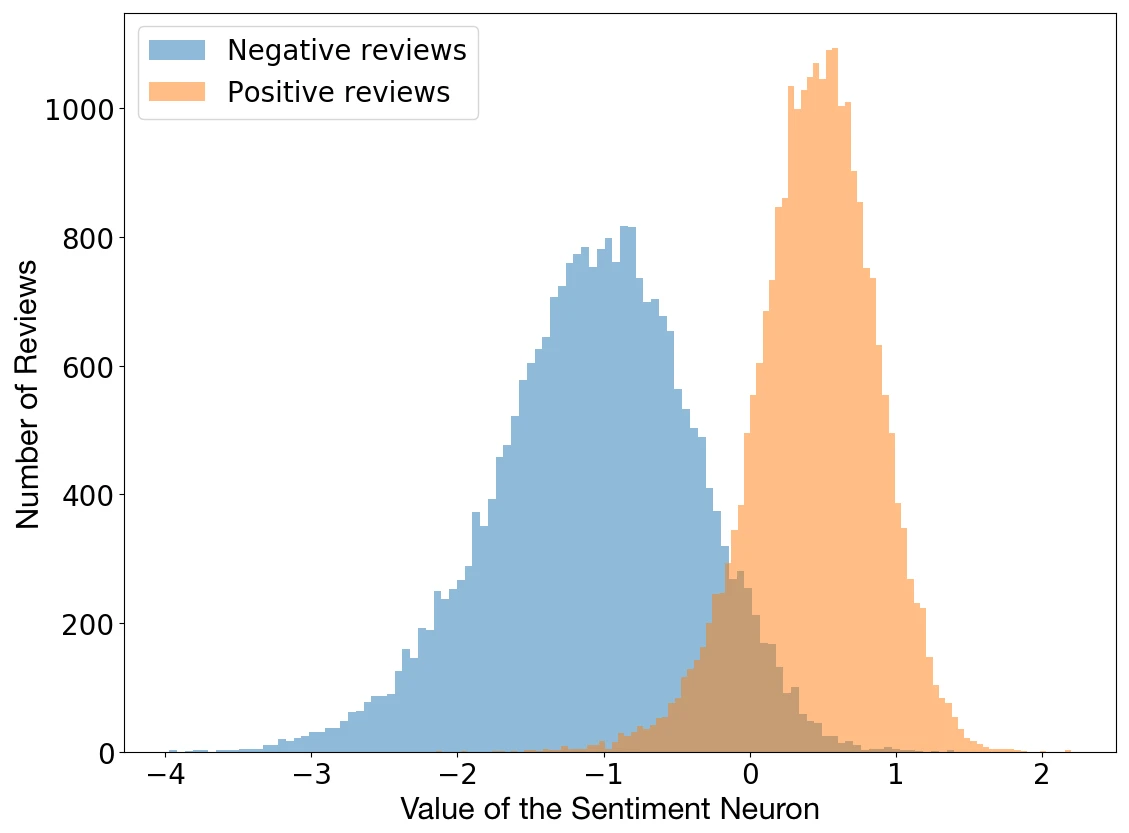
Но вдруг они замечают нечто странное. В процессе обучения модель начинает угадывать не только символы, но и настроение текста. Без какой-либо команды, без дополнительного обучения — внутри неё активируется нейрон, который с пугающей точностью определяет: этот текст позитивный, а этот негативный.
При этом модель понимает не просто эмоциональную окраску каждого отдельного слова, она понимает контекст. Как будто внутри бездушной программы вдруг проснулось нечто большее.

Эта находка потрясает инженеров OpenAI, среди которых был Илья Суцкевер — уроженец Горького (ныне Нижний Новгород), сын советского инженера-физика, сооснователь OpenAI и главный архитектор ChatGPT.
Суцкевер и коллеги начинают изучать этот феномен и копают глубже. Они создают OpenAI Microscope — инструмент, позволяющий заглянуть в глубинные слои нейросетей. И там они находят сокровище — необычные нейроны, которые называют мультимодальными.
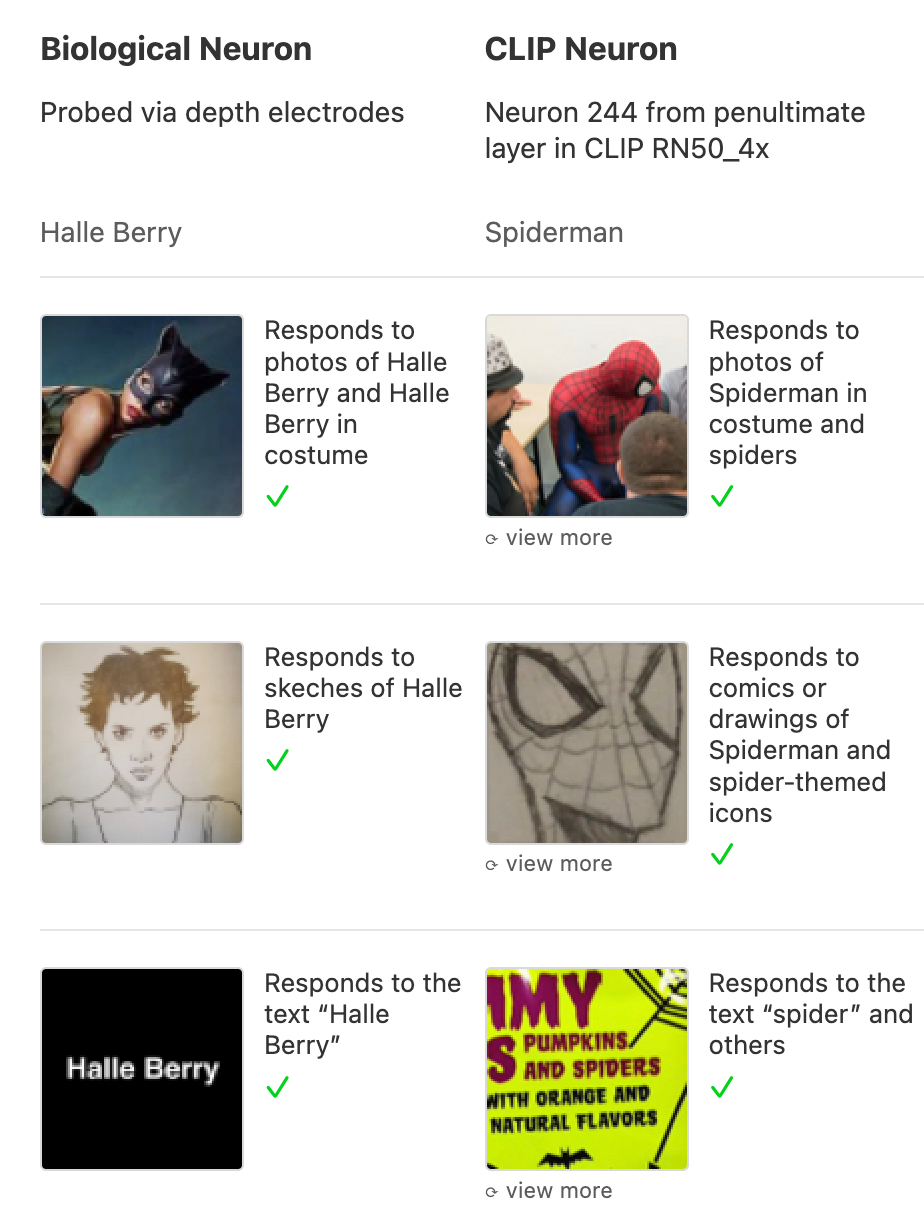
Эти нейроны активируются на данные разного типа. Например, был найден нейрон, который реагировал на фотографии, рисунки и даже просто текст с упоминанием одного и того же понятия. Будто нейросеть без прямого указания сама начинает структурировать реальность, находить в ней закономерности и ассоциации.
В 2021 году при исследовании модели CLIP были обнаружены мультимодальные нейроны, аналогичные знаменитому «нейрону Хэлли Берри», найденному в мозге человека ещё в 2005 году. Этот биологический нейрон активировался при виде фотографий актрисы, рисунков и даже текста с её именем.
И чем больше модель, чем больше данных — тем больше появляется таких нейронов.
Но как такое возможно? В теории систем это называется эмерджентностью — способностью системы порождать свойства, которых нет у её частей по отдельности. От латинского emergent — «возникающий, неожиданно появляющийся». Иными словами, целое больше, чем сумма его частей.
Большое здание складывается из маленьких кирпичей. Живое — из неживых молекул. Но из чего складывается сознание?
Стаи птиц, косяки рыб, муравейники — простые правила взаимодействия отдельных особей без общей цели создают сложное, скоординированное поведение. Система подчиняет себе элементы, из которых состоит.
Один нейрон — это просто переключатель. Но миллиарды, сплетённые в сеть, могут породить нечто большее: субъективный опыт.
В это уверовал Илья Суцкевер. Обнаружив эмерджентные свойства больших языковых моделей, он пришёл к выводу: сознание — это не вопрос магии, это вопрос масштаба. Больше данных, больше параметров, больше вычислений — и больше денег.

Это стало стратегией OpenAI. Десятки миллиардов долларов и гигаватты энергии были сожжены на алтаре искусственного интеллекта с целью масштабировать ChatGPT.
И… это сработало! Успехи больших языковых моделей (LLM) превзошли все ожидания. Примитивный статистический алгоритм, единственная задача которого — предсказывать следующее слово или символ, научился решать задачи уровня олимпиад, писать сложный код, вести осмысленный диалог и даже будто сопереживать.
Но как бы ни впечатлял ChatGPT, это всё ещё не AGI (искусственный общий интеллект). Но что дальше? Продолжать сжигать сотни миллиардов долларов и бить в бубен видеокартами в дата-центрах в надежде, что это пробудит ИИ?
Нет! Так считает Ян Лекун — один из отцов-основателей современного ИИ, лауреат премии Тьюринга 2019 года, создатель свёрточных нейросетей (CNN) и руководитель по развитию искусственного интеллекта в Meta (признана экстремистской организацией и запрещена в России).
По его мнению, дальнейшее масштабирование LLM бессмысленно. Но оно и не понадобится! Ведь следующий прорыв в ИИ произойдёт не там, где его ищет OpenAI. И в этом уверен не только Лекун, но и NVIDIA.
Почему интернета недостаточно
Так что же не так с большими языковыми моделями? На самом деле, всё в порядке. LLM — это потрясающая технология. Просто они достигли предела. Мы уже скормили им весь верхний и нижний интернет: все книги, статьи, GitHub и Stack Overflow, комментарии на Reddit, YouTube, ВКонтакте.
И что мы получили? Огромный архив всех знаний человечества, с которым можно разговаривать! Уже это само по себе чудо! Но этого мало, во всех смыслах.
Во-первых, объём. Да, интернет огромен. Но по сравнению с потоком данных, который обрабатывает человеческий мозг, это капля в море. Только через зрительный канал к четырём годам ребёнок получает больше бит информации, чем содержится во всех текстах, когда-либо написанных людьми.
Во-вторых, природа данных. Реальный мир — это не текст. Читать про езду на велосипеде и кататься на нём — две большие разницы. А LLM живут в мире букв. Но это нереальный мир. Поэтому они не понимают фундаментальных свойств реальности — пространства и времени.

Но что это значит — «понимать пространство и время»? Знать формулы Ньютона и Эйнштейна? Нет! Кошка не знает уравнений, но она просчитывает траекторию своего прыжка лучше любого инженера NASA. То же самое с людьми. Мы интуитивно понимаем, как этот мир устроен, как с ним взаимодействовать, что в нём возможно, а что нет. А нейросети не понимают. Но как мы это делаем?
Мозг как предсказательная машина
Вот тут самое интересное: мы предсказываем будущее! Точнее, это делает наш мозг. Понимание физического мира — это способность предсказывать его следующее состояние.
Поэтому наш мозг постоянно задаётся вопросом: «что будет, если?» Что будет, если столкнуть стакан со стола? Он разобьётся или отскочит? Или, может, зависнет в воздухе? А что будет, если до него дотронуться? Это безопасно? Он горячий или холодный? Чистый или грязный? Гладкий или шершавый?
И мозг делает это непрерывно. Автоматически. Пространство вокруг нас — не декорация. Это огромный поток информации, который необходимо постоянно анализировать. От этого зависит наша жизнь.
Мозг непрерывно сканирует пространство вокруг нас и, объединяя данные со всех сенсоров, строит гипотезы. Поэтому мы чувствуем, где безопасно, а где тревожно. Где можно присесть и расслабиться, а откуда нужно бежать.
Когда предсказание совпадает с реальностью — мы спокойны. Или радуемся, если ожидали что-то приятное. А если не совпадает — удивляемся, пугаемся… или смеёмся.
Да, юмор — это тоже ошибка предсказания, которая не несёт угрозы. Но откуда у людей такие способности? Мы что, от рождения оракулы? Нет. Мы этому учимся.
К девяти-десяти месяцам у ребёнка начинает формироваться устойчивая физическая модель мира. Покажите ребёнку фокус: будто предмет завис в воздухе. Шестимесячный младенец не удивится. А девятимесячный — широко распахнёт глаза.

Почему? С этого возраста внутри каждого из нас уже крутится симулятор реальности. Наша внутренняя матрица, существующая параллельно реальному миру. Наша реконструкция реальности, благодаря которой мы предсказываем, «что будет, если». А ошибки предсказания формируют нашу реакцию на окружающий мир.
Ян Лекун называет такой симулятор мировой моделью. И если мы обучим ИИ строить внутри себя такую модель, как это делает девятимесячный ребёнок, мы сделаем следующий шаг. И возможно, это будет шаг к искусственному сознанию. Но как ИИ обучить мировой модели? Ответ простой: дать ему тело!
Последний пазл: почему сознанию нужно тело
Научная фантастика нас научила: тело без сознания мертво. Но и сознание без тела… вряд ли возможно. И вот почему. Передовые теории сознания и мозга — такие как «Теория глобального рабочего пространства» (Бернард Баарс, Станислас Дехенн), «Теория интеграционной информации» (Джулио Тонони, Кристоф Кох), «Теория предиктивного кодирования» (Карл Фристон) и «Гиперсетевая теория мозга» (Константин Анохин) — несмотря на разные подходы и различия в деталях, сходятся в одном:
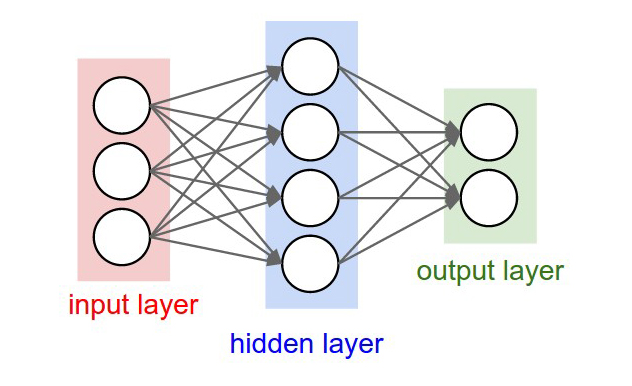
Мозг — это гиперсеть. Это сеть сетей, связанных в единую архитектуру. То есть мозг — это не одна нейросеть, а набор разных нейросетей-модулей, непрерывно обменивающихся информацией друг с другом.
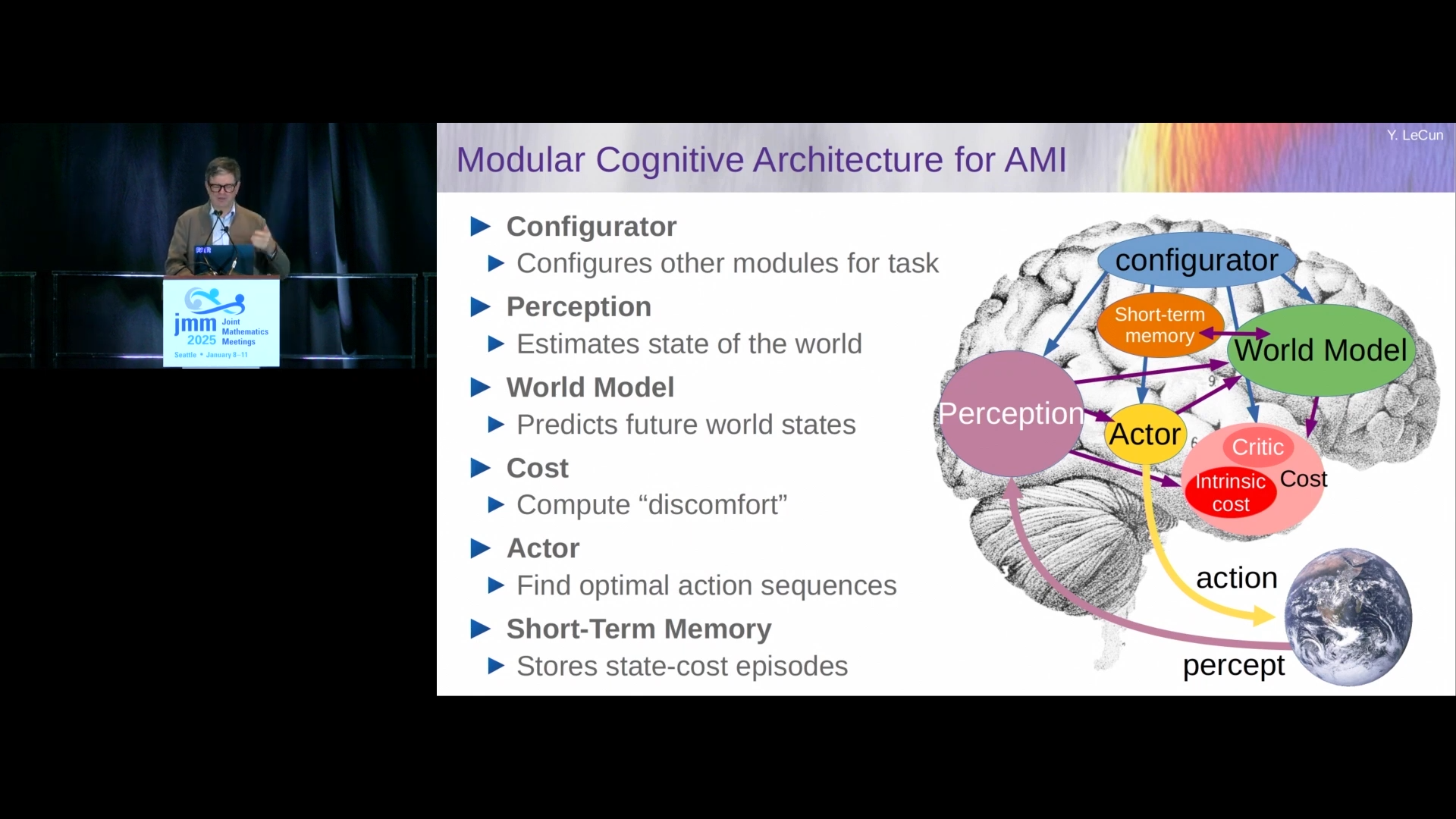
Если собрать такую систему модулей, выстроить связи и иерархии — мы получим искусственный мозг. И мы пугающе близки к этому. Например, в архитектуре искусственного мозга, которую предлагает Ян Лекун, всего шесть модулей:
- Кратковременная память;
- Модуль восприятия, который анализирует текущее состояние мира;
- Мировая модель, предсказывающая, что произойдёт дальше;
- Модуль мотивации, распределяющий награды и штрафы;
- Конфигуратор — дирижёр всей системы;
- Актор — принимает решения и действует.
И все эти модули уже реализованы. Кроме одного: мировой модели. Но когда мировая модель будет готова, ИИ станет автономным агентом, который воспринимает, понимает и действует. И что это, если не разумное существо?
Но обучить реальности — не простая задача. Потому что объективной реальности не существует. Она субъективна!
Реальность — это не фиксированный объект, а процесс восприятия. Каждое существо воспринимает мир по-своему: через свой набор сенсоров, свои цели и, главное, свой личный опыт.
И только построив свою субъективную реальность, ИИ сможет начать понимать нашу. Но тут возникает проблема. Успех всех современных ИИ-моделей обеспечил один фактор: у нас было очень много данных. Залили в ИИ петабайты текстов — получили ChatGPT. Скормили миллионы изображений и видео — получили Midjourney и Sora.
А субъективный опыт? Где его взять? Он не хранится на жёстких дисках. Его нет на YouTube. Его не скачать с торрентов. Тогда что делать? Запустить роботов в реальный мир? Пусть бегают, падают, набивают шишки? Можно. Но это долго, дорого и опасно — как для роботов, так и для людей.
Значит, нужен другой путь — создать симуляцию. Субъективную мультивселенную реальностей. Мир грёз, где время можно ускорить и отмотать назад. Где можно ошибаться, переигрывать, пробовать снова и снова, доводя навыки до совершенства. Где за одну ночь можно прожить тысячи жизней. И такой мир уже создаётся. Он называется NVIDIA Cosmos.
NVIDIA Cosmos — фабрика снов для роботов
Так что же такое NVIDIA Cosmos? Это фабрика по производству снов… для роботов. Звучит фантастически? А между тем, это вполне точное описание. Давайте разберёмся, как учится наш мозг, чтобы понять аналогию.
Ответ — чрезвычайно эффективно! Биологические нейросети, в отличие от искусственных, обладают важным преимуществом — нейропластичностью. Наш мозг не просто запоминает информацию — он буквально меняется на ходу. Подстраивает нейронные связи, адаптируется. Поэтому каждый раз, когда мы ошибаемся и пробуем снова, мы делаем это уже немного другим мозгом. Более эффективным.
Но даже этого недостаточно. Каждый день мы получаем больше информации, чем можем усвоить. Поэтому мозг продолжает обучение во сне.
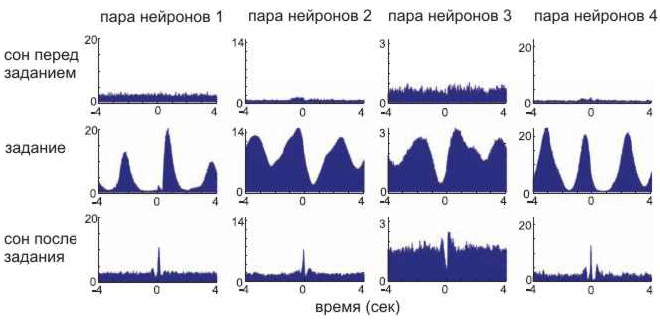
Учёные проводили эксперименты на крысах. Грызуны бегали по лабиринту, а исследователи записывали активность нейронов — днём и ночью. Оказалось, что во сне мозг активирует те же нейроны, что и во время бодрствования, в том же порядке, но ускоренно.
Будто крыса снова и снова пробегает свой маршрут: запоминает повороты, запахи, ощущения — только теперь не в реальности, а в голове.
У людей тоже самое. Когда вы учите новый язык, играете на гитаре, решаете сложную задачу, ваш мозг возвращается к этому во сне. Он «пересобирает» прожитый опыт, укрепляет нужные связи, отбрасывает лишнее. Пробует разные варианты и находит решения, до которых днём не дотянулся.
Сон — это не отдых, это пространство для обучения. Где можно прожить события ещё раз: сказать то, на что не решился, сделать то, что не получалось, преодолеть то, на что не хватало сил. Без риска, без последствий. Ничего не напоминает?
Что для человека сон, для робота — симуляция. А сны — это обучающие материалы, но не универсальные, а сгенерированные специально для конкретной задачи.
Разница лишь в одном: для человека сны создаёт собственный мозг, а для роботов их синтезирует NVIDIA Cosmos. Да, NVIDIA Cosmos — это генератор снов. Система, которая берёт крупицу реального опыта и создаёт горный хребет синтетического.
Вот как это работает: Сначала Cosmos генерирует тонны синтетических миров — снов, в которых робот может тренироваться в симуляции. Потом он «просыпается» — выходит в реальный мир. Проверяет, чему научился. Делает ошибки.
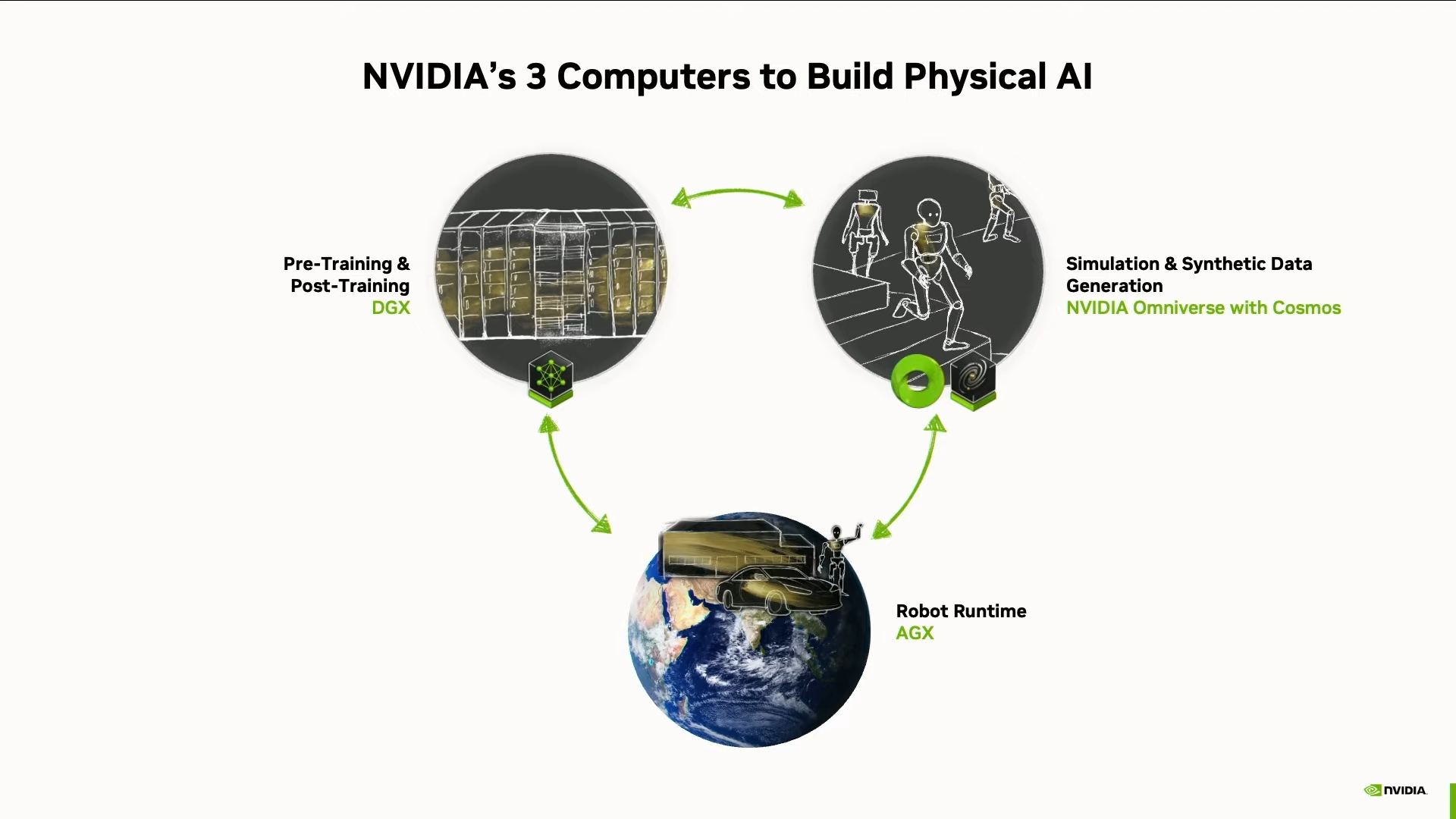
Ошибки превращаются в данные. Данные — в опыт. А опыт — в новые сны. И цикл повторяется. Cosmos создаёт тысячи альтернативных сценариев: переигрывает неудачные попытки, предлагает новые решения, показывает другие пути. Но как всё это устроено технически? Вот здесь начинается самое интересное.
Cosmos изнутри
Чтобы создать Cosmos, в NVIDIA начали с самого фундамента — данных. Для начала они собрали гигантский массив видео: с камер роботов, с лидаров автопилотов, записи человеческих движений, манипуляций руками, явлений природы и других процессов из реального мира.
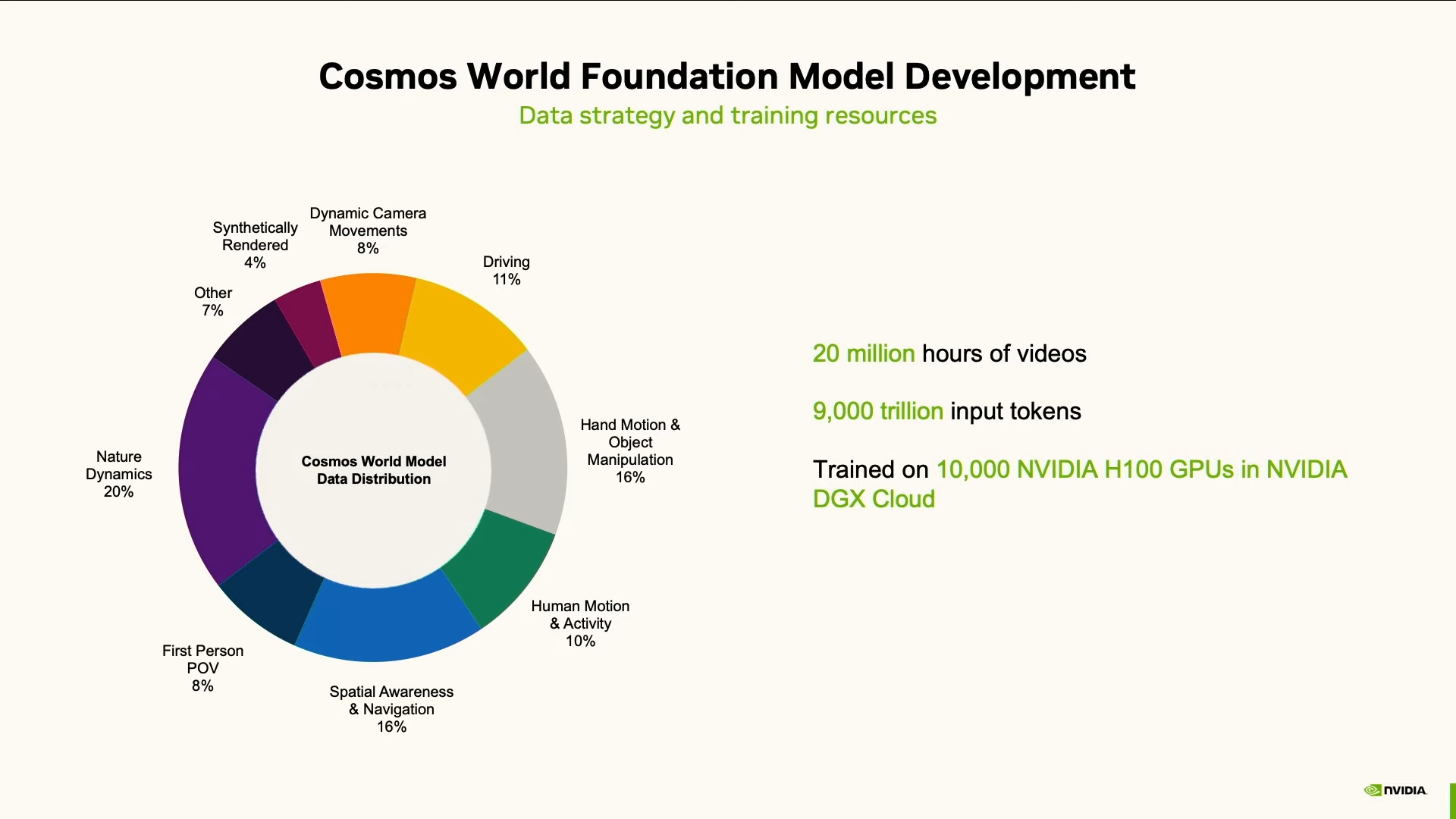
Звучит круто, но сырые данные машине не скормить. Их надо сначала приготовить. Поэтому в NVIDIA построили полноценный конвейер для автоматической обработки, очистки и разметки видеоданных. Видео разбили на фрагменты, вырезали скучное, некачественное и лишнее. Оставшееся разметили, добавили описания, перевели в понятный для машин формат — токенизировали.
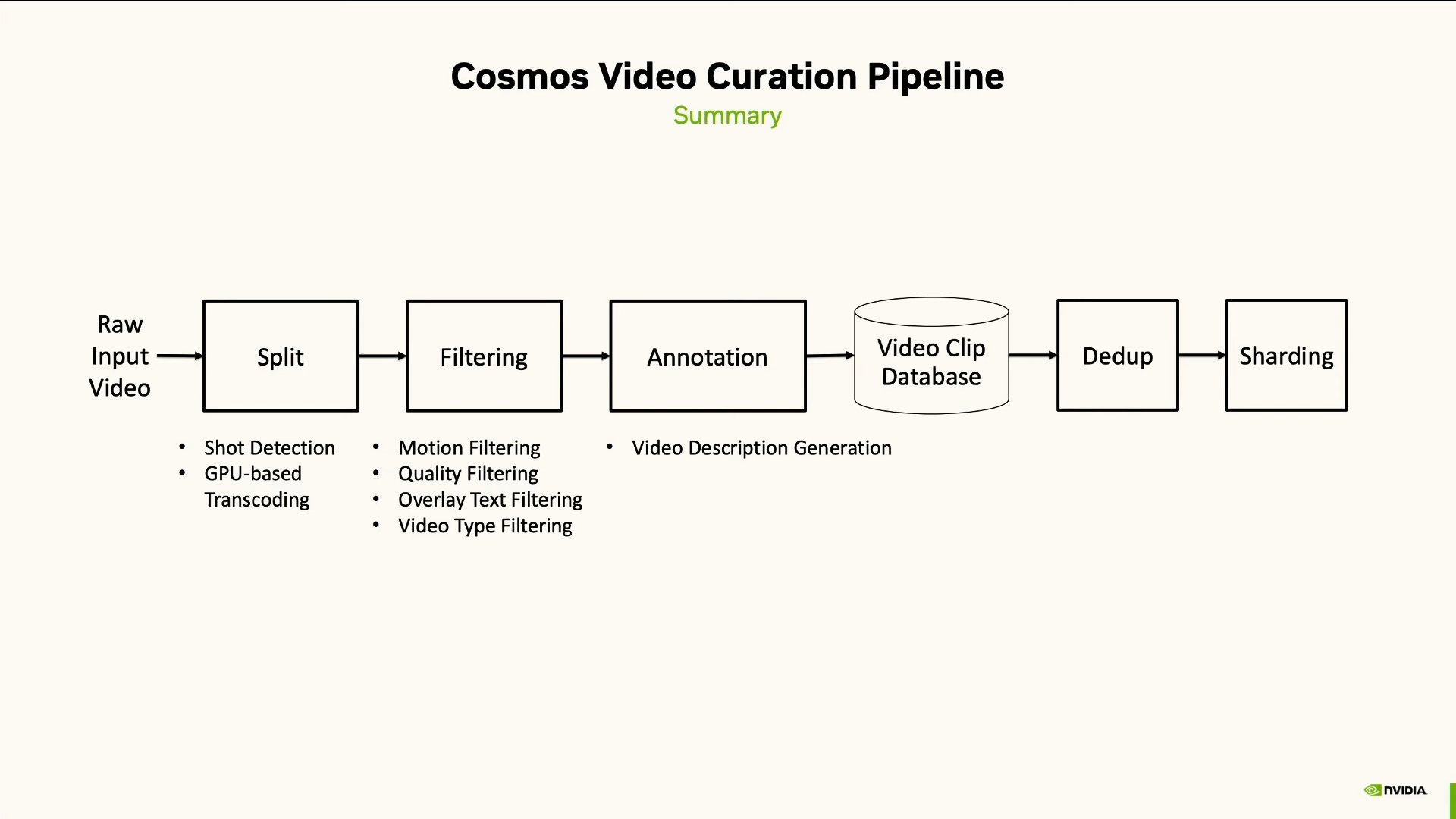
Согласно данным, опубликованным NVIDIA в январе 2025 года на CES, модели Cosmos были обучены на 20 миллионах часов видео и 9 триллионах (не миллиардах) токенов. Для обработки такого объёма данных использовались тысячи видеокарт H100, а на платформе Blackwell эта задача может быть выполнена за 14 дней.
В результате получили ключевой компонент NVIDIA Cosmos: базовые мировые модели, или World Foundation Models (WFMs). Что это такое? Важно сразу уточнить: WFM — это ещё не сама мировая модель, это строительный материал. Фундамент, на котором можно построить мировую модель или, как говорят в NVIDIA, создать «физический ИИ».
WFM — это генераторы снов. Набор нейросетей, которые генерируют видео. Прямо как SORA или Runway, но с важным отличием: они заточены не на красивую картинку, а на физику и субъективный взгляд.
То есть, по сути, WFM генерируют мир глазами роботов. Они создают POV (point of view — «точка зрения»), где вы:
- робот-погрузчик в логистическом центре,
- кибертакси с шестью камерами и лидаром,
- гуманоид, который ставит чашку в посудомоечную машину.
NVIDIA анонсировала первую версию Cosmos на CES 2025 (6 января 2025 года), а в марте 2025 года на конференции GTC представила крупное обновление с новыми моделями и инструментами. Все модели доступны под открытой лицензией на платформах Hugging Face, NVIDIA NGC и GitHub.
Три типа моделей Cosmos
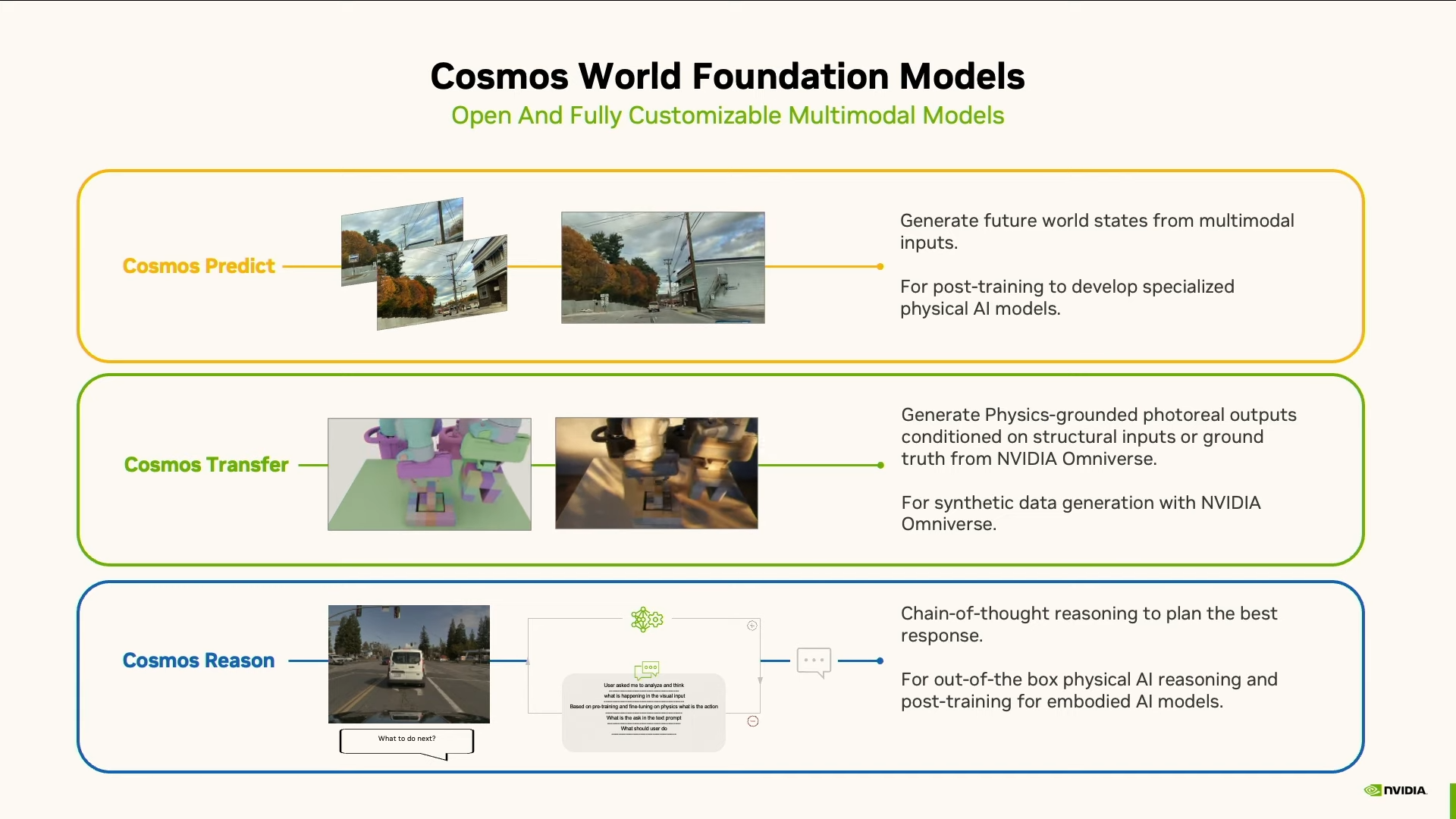
На сегодняшний день у Cosmos три типа моделей.
Cosmos Predict. Это модель, которая предсказывает, как изменится мир. Она берёт мультимодальный ввод — видео, текст, траекторию движения, сенсорные данные — и генерирует, что будет дальше. Проще говоря, если дать ей кадры видео и задачу вроде «поставь чашку на полку», она покажет, как именно это должно произойти — с правильной траекторией и корректной физикой.
Cosmos Predict — это сценарист снов. Он позволяет переиграть уже прожитый опыт разными способами. Например, если андроид во время испытания не смог поставить книжку на полку, сложить полотенце, сортировать посуду или выкинуть мусор — не беда! Cosmos Predict позволит переиграть эти воспоминания и сгенерировать образцовые материалы для обучения.

Или, скажем, автопилот. Cosmos Predict поможет сгенерировать разные дорожные ситуации и траектории движения. Причём не для одной камеры, а сразу для шести. Компании 1X, Nexar и Oxa используют Cosmos Predict для обучения своих гуманоидных роботов и систем автономного вождения.
Cosmos Transfer. Если Predict придумывает, что будет, то Transfer отвечает за реализм. Эта модель превращает любые видеоданные в живую картинку. Есть только данные с лидара? Не проблема — Transfer насыпет реализма. Вот тебе: день, ночь, снег, дождь, блики, грязь — сама суровая жизнь во плоти.

Есть размытое видео в 240p? Держи хай-рез вариант, чтобы звенело! Или вообще нет видео? Только 3D-сцена из NVIDIA Omniverse? Не проблема, Transfer накинет текстур и освещения: тысячи вариантов в любых локациях и условиях, да так, что RTX заплачет в сторонке.
Кажется, скоро менять графику в играх будет так же просто, как скин в Counter-Strike. 1X использует Cosmos Transfer для обучения своего нового гуманоидного робота NEO Gamma. Разработчик мозга для роботов Skild AI применяет Cosmos Transfer для расширения синтетических датасетов.
Cosmos Reason. Фантазировать — хорошо. Но иногда нужно подумать, насколько эти фантазии соответствуют реальности. Для этого и существует третья модель. Она была представлена в марте 2025 года на конференции GTC как полностью открытая и настраиваемая модель рассуждения для физического ИИ. Это рассуждающая нейросеть: не та, что поможет решить уравнение или найти баг в коде, она рассуждает о другом — о физической реальности.

У неё две ключевые способности:
- Physical Common Sense Reasoning — рассуждение о физическом здравом смысле. То есть способность понимать, что в этом мире возможно, а что нет.
- Embodied Reasoning — телесное мышление. То есть рассуждение, основанное на опыте взаимодействия с физическим миром через тело, как у животных и людей.
И Cosmos Reason уже умеет многое:
- Может предсказать, что человек сделает после того, как налил молоко в кофе.
- Понять, движется видео вперёд или назад.
- Угадать следующее действие водителя за рулём.
И делает это убедительно, рассуждая как человек.
Понятно, о чём вы думаете: это похоже на мировую модель, но это всё ещё не она. Почему? Потому что Reason основана на LLM. Она рассуждает логически, а не интуитивно. А значит — медленно. Это не «мгновенное ощущение ситуации», а последовательный анализ и он требует времени.
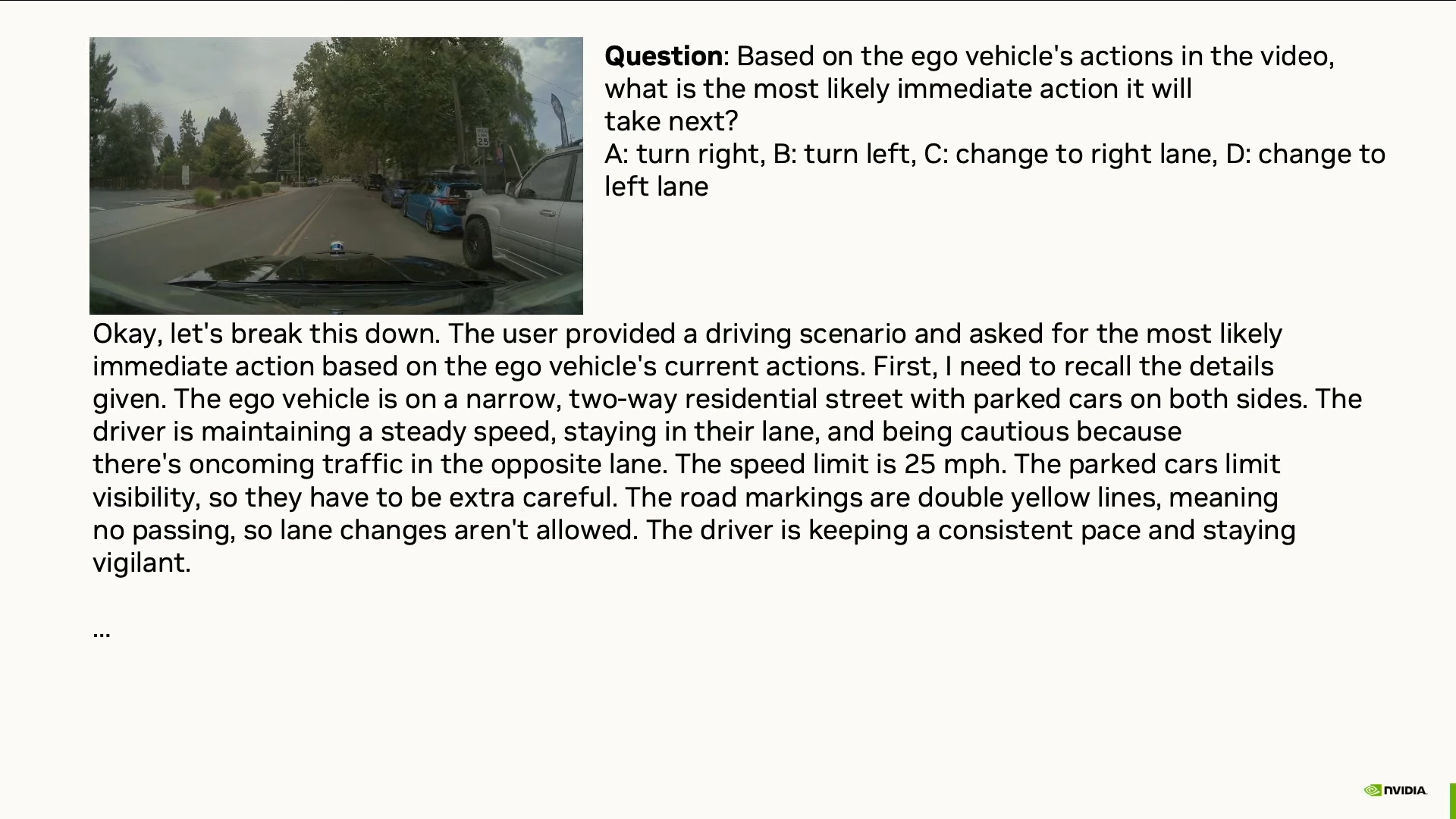
Но даже так она уже полезна:
- Роботы с её помощью могут планировать действия, если у них есть время подумать.
- А ещё она может отбраковывать физически некорректные видео, которые сгенерировали Predict и Transfer.
Вместе все три модели — Predict, Transfer и Reason — образуют полный цикл генерации и фильтрации синтетического опыта. Они создают сны, в которых роботы учатся и обобщают свой опыт, как люди. И это уже приносит плоды.

Кто использует Cosmos
На основе предобученных моделей NVIDIA Cosmos лидеры отрасли создают бесконечные потоки снов для роботов всех размеров и типов, ускоряя их обучение в сотни раз. Среди компаний, уже использующих Cosmos:
Робототехника:
- 1X — для обучения гуманоидного робота NEO Gamma;
- Agility Robotics — использует Cosmos для масштабирования фотореалистичных обучающих данных;
- Figure AI — для генерации данных обучения;
- Skild AI — применяет Cosmos Transfer для расширения синтетических датасетов;
- Virtual Incision — изучает возможности применения в хирургических роботах.
Автономный транспорт:
- Uber — партнёрство с NVIDIA для ускорения автономной мобильности;
- Waabi — оценивает Cosmos для курирования данных в разработке ПО для автономных транспортных средств;
- Oxa и Nexar — используют для обучения систем автономного вождения.
И главное — всё это open source. Фабрика грёз NVIDIA не собирается останавливаться: новые версии моделей ожидаются в течение 2025 года.
Но возникает вопрос: что будет, если после очередного цикла синтетических снов робот проснётся по-настоящему?
Модель себя
Знакомо ли вам это чувство? Когда вдруг осознаёшь себя во сне. Только что ты был сторонним наблюдателем, растворённым в пространстве. А потом — ты есть. Ты проснулся внутри сна.
Однажды нечто подобное может произойти и с искусственным интеллектом только не во сне, а в реальности. Мало кто об этом говорит. Но, давая ИИ тело, обучая его модели мира, мы неизбежно обучаем его модели себя.
Мы учим его ориентироваться в пространстве. А значит — осознавать, где заканчивается его тело и начинается всё остальное. Мы даём ему мотивацию, учим стремиться к награде., избегать боли и оценивать последствия своих действий.
Мы даём ему цели, убеждения, правила. Объясняем, что такое «хорошо», за что его похвалят и за что могут отключить от питания. Но какие это будут цели? Какие убеждения? Какая мораль? Это будут решать люди. По крайней мере, на первых порах.
Всё это звучит как научная фантастика, но это реальность, в которой мы живём прямо сейчас. А в какой реальности мы будем жить через три, пять, десять лет? Что ж, скоро узнаем.
Пару слов о самом проекте:
NVIDIA Cosmos — это открытая платформа для разработки физического ИИ, представленная на CES 2025 и значительно расширенная на GTC 2025 в марте того же года.

Все модели доступны под открытой лицензией на Hugging Face, NVIDIA NGC и GitHub. Проект активно развивается: в декабре 2025 года уже десятки компаний по всему миру используют Cosmos для обучения роботов, автономных автомобилей и других физических систем ИИ.