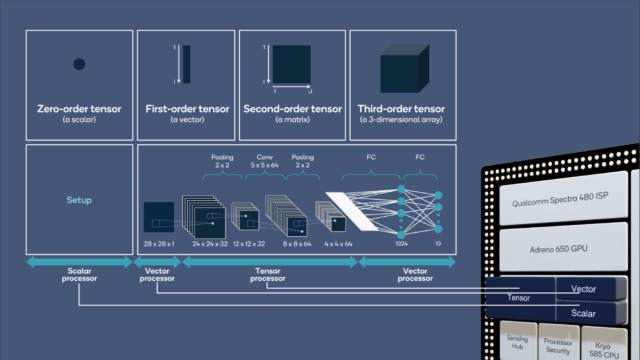
20 февраля Google выпустила Gemini 3.1 Pro — первый раз в истории компания использует инкремент к приставке «.1» вместо привычного «.5». Модель удвоила мощность рассуждения (reasoning performance) по сравнению с Gemini 3 Pro и достигла 77,1% на ARC-AGI-2 бенчмарке — тесте, который проверяет способность ИИ решать совершенно новые логические паттерны.
Отмечается, что это не просто улучшение показателей для статистики. Google фокусируется на создании полноценного агента с возможностями выполнения разных задач (agentic workflows) и более улучшенными возможностями рассуждений для задач, которые требуют глубокий ответ. Модель умеет генерировать анимированные SVG-изображения с кодом, строить сложные приложения вроде симуляторов городского планирования, синтезировать огромные датасеты.
Gemini 3.1 Pro доступен в Gemini app для всех, с повышенными лимитами для Google AI Pro и Ultra подписчиков, плюс эксклюзивно в NotebookLM для платных пользователей. Разработчики получают доступ через Gemini API, Vertex AI, Google Antigravity и Android Studio.
Почему это важно: три месяца назад вышел Gemini 3 Pro, теперь Google выкатывает «.1» вместо традиционного полугодового цикла. Это ускорение темпов развития — и прямая атака на OpenAI GPT-5 и Anthropic Claude Opus 4.6. Гонка мощностей рассуждения (reasoning) превращается в спринт, где обновления выходят каждые 90 дней, а не раз в полгода.
Игровые миры будущего: как искусственный интеллект меняет индустрию видеоигр
ИИ создаёт игровые миры: как нейросети генерируют вселенные, оживляют NPC и меняют геймдев. Обзор Google Genie 3, NVIDIA ACE и технологий будущего.
Посмотрите внимательно на новейшие технологические демонстрации Google. Перед вами абсолютно новая игра, созданная в реальном времени. Графика впечатляет? Геймплей выглядит интересно?
Главное — всё, что вы видите, не создано традиционными разработчиками. Более того, это мир, который в режиме реального времени генерирует нейросеть по одному текстовому описанию.
Никаких программистов в классическом понимании, никаких игровых движков в привычном формате. Просто искусственный интеллект, который понимает, как устроены виртуальные миры.
Впервые в истории человечества мы можем создавать целые вселенные. Не метафорически, а буквально — со своими законами физики, живыми существами, развивающимися экосистемами. Мы стали архитекторами реальностей.
Но как такое вообще возможно?
Тихая революция в игровой индустрии
Пока геймеры спорят о графике в новых AAA-проектах и ждут анонсов, в лабораториях Google, Microsoft и NVIDIA рождаются технологии, которые полностью перевернут представление о том, как создаются и работают игры.
По данным Google, почти девяносто процентов игровых студий активно экспериментируют и внедряют генеративный ИИ в свои процессы разработки.
Недавний скандал с игрой года Clair Obscur: Expedition 33 и использованием генеративного ИИ в разработке лишь подтверждает масштаб трансформации. О чём говорить, если сам Хидео Кодзима — признанный гений игровой индустрии — в интервью Nikkei Trend заявил о планах применять технологию для повышения эффективности работы, а также для персонализации игр, чтобы геймплей подстраивался под конкретного человека.
«С помощью ИИ можно сократить задачу, которая раньше занимала десять часов, до буквально нескольких десятков секунд. Ещё увеличивается объём того, что может сделать один человек. Уже сейчас появляется всё больше создателей, которые в одиночку делают проекты, сопоставимые с работой целой команды», — отметил Кодзима.
И это лишь вершина айсберга. Нейросети не просто помогают художникам рисовать текстуры, а программистам искать ошибки в коде. Они создают целые игровые миры за считанные секунды. Персонажей, которые помнят каждый ваш разговор и строят с вами отношения. Уникальные квесты, которые адаптируются под ваш стиль игры.
Каждое новое поколение ИИ приближает нас к созданию полноценных симуляций. Миров, где неигровые персонажи (NPC) не следуют скриптам, а проживают настоящую жизнь.
В этом материале мы покажем, как искусственный интеллект уже интегрирован в современные игры. Речь про технологии, которые используются каждый день, даже если вы не подозреваете об этом. Также поговорим о невероятном достижении современности — генерации целых игровых миров, разберём, как работает Google Genie 3, и сравним его с подходами Microsoft и китайского проекта Yan.
Мы расскажем, как искусственный интеллект учится быть создателем миров, как технологии дают человеку силу, о которой раньше можно было только мечтать, и насколько близко мы подошли к моменту, когда различить симуляцию и реальность станет невозможно.
ИИ сегодня: невидимая революция в каждой игре
Современные видеоигры используют искусственный интеллект настолько органично, что большинство игроков даже не осознают масштаб его присутствия. Технологии, которые ещё пять лет назад считались экспериментальными, сегодня работают в каждой AAA-игре.
DLSS: нейросеть рисует мир
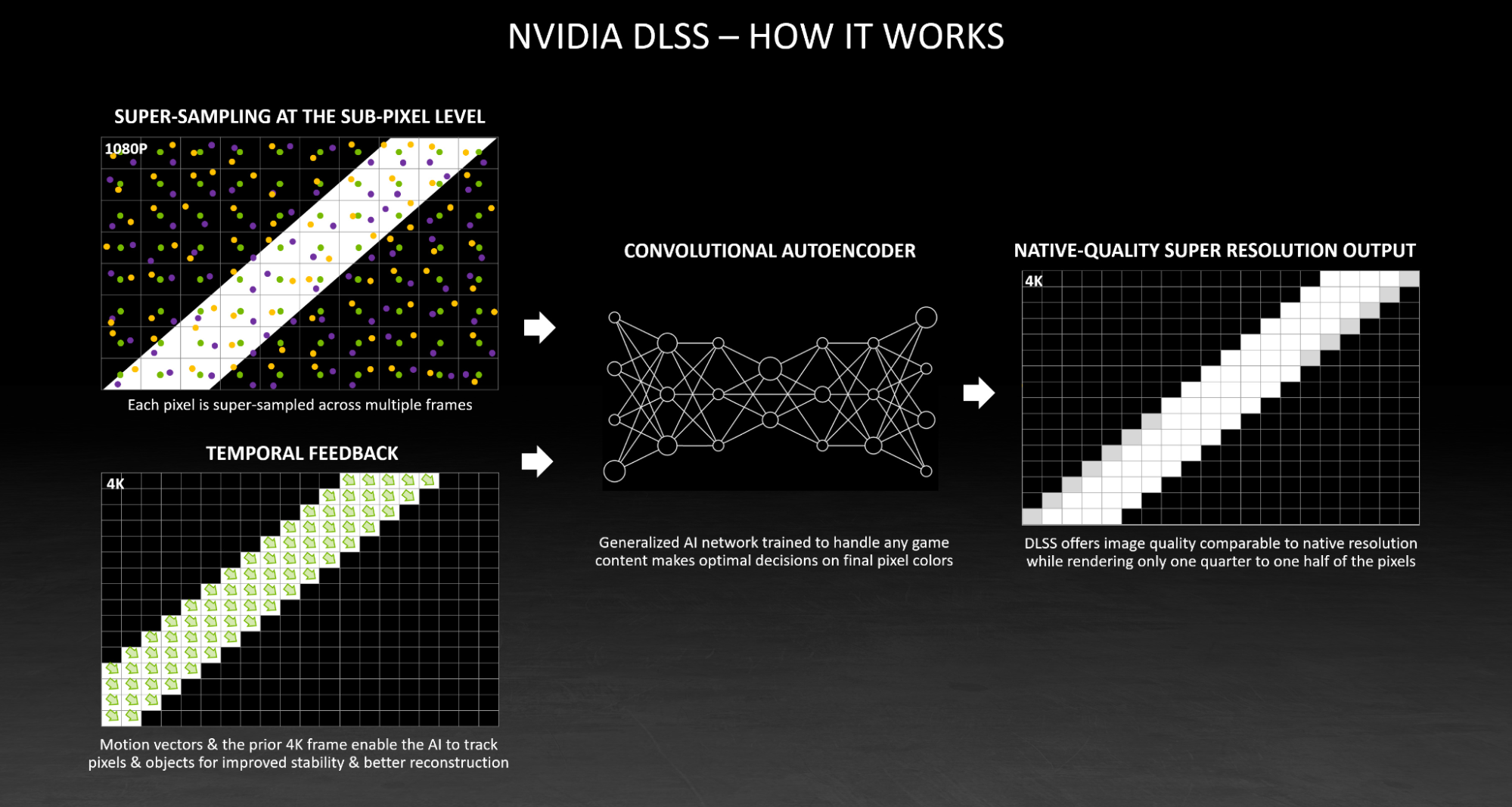
По состоянию на февраль 2026 года технология NVIDIA DLSS (Deep Learning Super Sampling) достигла версии 4.5 и представляет собой наиболее наглядный пример этой невидимой революции. При её активации в игре вроде Cyberpunk 2077 нейросеть дорисовывает до 75% пикселей на экране. Игра рендерит изображение в разрешении 1080p, а на мониторе отображается картинка качества 4K. Всё происходит в реальном времени, с задержкой менее двух миллисекунд на кадр.
Но фокус не только в увеличении разрешения. Нейросеть анализирует движение объектов между кадрами, использует информацию из предыдущих фреймов, чтобы восстановить мелкие детали. Она буквально предсказывает, как должна выглядеть картинка в высоком разрешении, основываясь на миллионах часов обучения.
Результат? Вместо 30 кадров в секунду пользователь получает стабильные 60 или даже 240 FPS благодаря новой технологии динамической генерации кадров в DLSS 4.5. Игра работает в два-шесть раз быстрее при той же или даже лучшей визуальной чёткости.
Только представьте: нейросеть дорисовывает то, чего не существует. Создаёт детали из ничего и предсказывает, как должен выглядеть мир. Мы передали машине способность творить визуальную материю. И это происходит десятки, сотни раз в секунду прямо в вашем компьютере.
Архитектура DLSS базируется на трансформерной нейронной сети второго поколения (в DLSS 4.5). Система анализирует не только текущий кадр, но и векторы движения, карту глубины, историю предыдущих кадров. Tensor-ядра в GPU выполняют до 300 триллионов операций в секунду, реконструируя детали, которых физически нет в исходном изображении.
Процесс проходит через шесть последовательных слоёв анализа. Первый слой выделяет границы объектов. Второй определяет текстуры. Третий анализирует согласованность между кадрами. Четвёртый восстанавливает мелкие детали. Пятый устраняет артефакты. Шестой выполняет финальную цветокоррекцию. И это занимает всего 1,8 миллисекунды.
NVIDIA инвестировала более двухсот пятидесяти миллионов долларов в разработку технологии. Результат: видеокарта уровня RTX 4060 с включённым DLSS может выдавать графику, сопоставимую с более мощными моделями.
Более 400 игр и приложений на февраль 2026 года поддерживают технологию DLSS, причём более 250 из них используют DLSS 4 с генерацией множественных кадров (Multi Frame Generation) — это самая быстро внедряемая игровая технология NVIDIA в истории.
ACE: персонажи с памятью и эмоциями
Но графика — это только начало. Настоящая ИИ-революция происходит с игровыми персонажами. NVIDIA создала целую платформу под названием ACE — Avatar Cloud Engine, объединяющую сразу несколько ИИ-систем в единый конвейер.
Во-первых, распознавание речи — вы говорите с персонажем голосом, и он вас понимает. Во-вторых, языковая модель с миллиардами параметров, оптимизированная специально для игр. Она понимает контекст игры, помнит предыдущие разговоры, имеет собственную личность. В 2025 году NVIDIA представила обновлённые модели Nemotron Nano 9B V2 и Qwen3-8B для ACE, обеспечивающие ещё более реалистичные взаимодействия.
Но самое впечатляющее — технология Audio2Face. Она берёт поток аудио и в реальном времени генерирует реалистичную лицевую анимацию. Движения губ, мимика, эмоции — всё синхронизируется автоматически. Раньше на анимацию одного диалога уходили недели работы аниматоров. Теперь — доли секунды работы нейросети.
Получается, что с помощью ACE мы дали цифровым персонажам подобие сознания. Память, которая формирует личность, а ещё способность учиться и развивать отношения. То есть каждый NPC становится героем со своей историей и характером. Мы больше не программируем поведение — мы создаём условия для его возникновения. Как эволюция, только в ускоренном режиме.
В начале 2026 года на выставке CES были представлены новые интеграции ACE. Например, в игре PUBG: Battlegrounds появился ИИ-напарник PUBG Ally с долговременной памятью, который эволюционирует вместе с игроком. В Total War: PHARAOH внедрён динамический ИИ-советник, помогающий игрокам осваивать сложные игровые системы и механики.
Gaming Copilot: умный помощник извне
Есть и такой ИИ, который прямо сейчас помогает игроку, и его создали в Microsoft. Gaming Copilot интегрирован прямо в игровую панель Windows и работает как персональный ассистент — это умный игровой помощник «снаружи», а не NPC с искусственным интеллектом внутри игры.
Застряли на головоломке? Copilot посмотрит на экран и подскажет решение. Не можете победить босса? Получите анализ его паттернов атак и слабых мест. Причём можно спросить совет, не отрываясь от геймплея, ведь всё работает через голосовые команды.
ИИ «видит», что происходит в игре, анализирует скриншоты экрана, понимает контекст, распознаёт врагов, предметы и интерфейс. Можно буквально сказать: «Эй, что это за штука слева?» — и получить подробное объяснение.
Помимо гигантов индустрии существует множество проектов от компаний поменьше, которые создают игровых помощников, виртуальных аватаров, возможность создавать текстуры для игр и многое другое.
Мы начали с малого — научили ИИ улучшать картинку и оживлять персонажей. Но на самом деле мы передаём машинам всё больше власти, в том числе творческой. Сначала они дорисовывают пиксели, потом создают личности. А дальше? Дальше они начинают создавать целые миры.
Google Genie 3: рождение миров из текста
В августе 2025 года Google DeepMind представила технологию, которая стала настоящим прорывом в области генерации игровых миров. Genie 3 — это скачок, сравнимый с переходом от немого кино к звуковому.
Но давайте сразу проясним: Genie 3 не создаёт видео. Это принципиально важно понять. Она создаёт интерактивные пространства, в которых можно играть в реальном времени — двигаться, взаимодействовать с объектами, наблюдать, как мир реагирует на ваши действия.
Обычные генераторы видео — это режиссёры. Они снимают фильм, который можно только смотреть. Genie 3 — это архитектор вселенных. Нейронная сеть создаёт мир, в котором можно находиться и жить.
И это не преувеличение. Раньше создание игрового мира требовало сотен людей и годы работы. Каждый камень размещался вручную, каждое дерево программировалось отдельно. Теперь? Вы пишете промпт — «лес с древними руинами» — и получаете целую экосистему, которая живёт, дышит, реагирует.
Как работает Genie 3
Вы управляете персонажем с клавиатуры или геймпада, а мир реагирует на каждое ваше действие. Причём реагирует логично — с нужной в этом игровом мире физикой, правильным освещением и тенями. Если создаётся мир с обычной гравитацией, то когда вы прыгнете в воду — появятся круги на воде, а когда толкнёте ящик — он упадёт с учётом силы тяжести.
Первая версия в 2024 году генерировала простые 2D-платформеры. Всего две секунды геймплея, разрешение как у видео из девяностых. Genie 2 уже создавала 3D-пространства, но всё ещё ограниченные. И вот Genie 3 — полноценные миры в разрешении 720p, работающие со скоростью 20-24 кадра в секунду.
Технически Genie 3 состоит из трёх ключевых компонентов, которые работают в связке.
Spatiotemporal Video Tokenizer (пространственно-временной видеотокенизатор) преобразовывает визуальный поток в компактное представление. Технология сжимает информацию в 32 раза, сохраняя при этом все значимые элементы: движения объектов, изменения освещения, взаимодействия между элементами сцены. Думайте об этом как о создании сверхэффективного языка для описания визуального мира.
Autoregressive Dynamics Model (авторегрессивная модель динамики) предсказывает, как мир должен измениться в ответ на действия игрока. Это мозг системы, который понимает причинно-следственные связи. Подожгли дерево? Пойдёт дым, и огонь будет распространяться.
Latent Action Model (модель скрытых действий) — самый инновационный компонент. Он понимает намерения игрока без явных команд. Движение персонажа влево интерпретируется не как простое смещение пикселей, а как целенаправленное действие с потенциальными последствиями — обход препятствия, подход к объекту, уклонение от опасности.
Персистентная память: мир помнит вас
Самое удивительное в Genie 3 — персистентная память. Это решение одной из главных проблем генеративных моделей. Дело в том, что визуальные нейросети обычно «забывают», что было несколько секунд назад. Вы поворачиваетесь спиной к объекту, поворачиваетесь обратно — а там уже что-то другое.
А Genie 3 запоминает состояние мира. Если вы разбили вазу, передвинули ящик, нарисовали граффити на стене — всё это сохранится. Можете уйти в другую локацию, побродить там несколько минут, а вернувшись — увидеть тот же пол с разбитыми осколками.
Технически это достигается через сложную систему кэширования состояний. Модель хранит «снимки» ключевых изменений и восстанавливает их при необходимости. По сути, она ведёт дневник всего, что произошло в мире, и может в любой момент к нему обратиться.
Персистентная память — это больше, чем технический трюк. Это первый шаг к созданию миров с настоящей историей, где ваши поступки имеют последствия не только сейчас, но и всегда.
Интерактивное изменение мира
Но вот где начинается настоящая магия. В любой момент игры можно написать текстовую команду, и мир мгновенно изменится.
Печатаете «начни дождь» — и тучи затягивают небо. «Добавь дракона» — и в небе появляется огнедышащий змей.
Это происходит без перезагрузки и загрузочных экранов. Мир трансформируется на ваших глазах, сохраняя логику и последовательность.
Но как Genie этому научилась? Она не программировалась с правилами физики. Никто не объяснял ей, что вода течёт вниз, а огонь поднимается вверх. Она вывела эти законы сама, просто наблюдая за сотнями тысяч часов видео. Как ребёнок, который учится понимать мир через наблюдение.
Genie самостоятельно вывела законы физики из хаоса видеоданных. Никто не объяснял ей гравитацию, инерцию, причинность. Она просто поняла. Извлекла порядок из хаоса. Создала свою модель реальности. И теперь использует эти законы, чтобы творить новые миры.
Применение за пределами игр
Genie подойдёт не только для игр. Google показывала примеры генерации обычных миров. Например, захотели прогуляться по Парижу девятнадцатого века? Пишете промпт и получаете новый опыт. Причём можно делать это в VR-шлеме.
Впрочем, создатели игр, без сомнения, возьмут Genie на вооружение в первую очередь. Слишком велик соблазн, и ему невозможно противостоять.
Project Genie: доступ для пользователей
В конце января 2026 года Google запустила Project Genie — экспериментальный прототип исследовательского проекта, работающий на основе Genie 3. Он доступен подписчикам Google AI Ultra в США (стоимость подписки — 249,99 долларов в месяц) для пользователей старше 18 лет.
Project Genie позволяет создавать, исследовать и переделывать интерактивные миры с помощью текстовых подсказок и изображений. Система генерирует путь в реальном времени по мере движения пользователя, а также позволяет регулировать камеру и переделывать существующие миры.
Текущие ограничения: сессии длятся до 60 секунд (хотя система может поддерживать консистентность в течение нескольких минут), некоторые возможности Genie 3, анонсированные в августе (например, изменение мира событиями по запросу), пока не включены в прототип.
Ограничения и будущее
Было бы нечестно не упомянуть об ограничениях. Текущая версия Genie 3 может поддерживать интерактивную сессию только несколько минут — потом начинаются артефакты и несоответствия. Набор действий ограничен базовыми — движение, прыжки, простые взаимодействия. Сложная физика для множества объектов одновременно пока не работает.
И главное — нет звука. Миры Genie 3 абсолютно беззвучны. Хотя Google уже имеет технологию Veo 3, которая умеет генерировать видео с нативным аудио, включая диалоги и звуковые эффекты. Вполне вероятно, в следующей версии появятся и эти возможности.
GameNGen: игра как память нейросети
Параллельно с Genie развивается ещё один эксперимент. GameNGen от Google Research доказал возможность существования игр без традиционного кода.
Классический DOOM, созданный Джоном Кармаком в 1993 году с использованием революционных для того времени алгоритмов рендеринга, был полностью воссоздан нейросетью.
Диффузионная модель «запомнила» DOOM, просмотрев тысячи часов геймплея. Она генерирует игру со скоростью 20 кадров в секунду. В слепых тестах игроки не могут отличить нейросетевую версию от оригинала после пяти минут игры.
Игра больше не существует как набор инструкций и ресурсов. Она существует как паттерн в весах нейронной сети, как воспоминание искусственного интеллекта.
Мы подошли к моменту, когда различить «созданное» и «воссозданное» становится сложно, а местами невозможно. Игра существует как идея, и если машина может полностью воссоздать реальность из памяти — отличается ли эта реальность от оригинала?
Genie 4 находится в разработке прямо сейчас. Инженеры DeepMind работают над интеграцией долговременной памяти, которая позволит создавать персистентные миры с часами непрерывного геймплея.
Важно, что Google позиционирует технологию не просто как инструмент для создания игр, а как «тренировочную площадку для искусственного общего интеллекта» (AGI). Именно в таких мирах ИИ-агенты будут учиться, экспериментировать и развивать навыки без риска для реального мира.
Альтернативные пути к играм будущего
Google — не единственный игрок в этой гонке. Microsoft, Tencent и другие компании развивают собственные подходы к генерации миров. И каждый идёт своим путём.
Microsoft WHAM: воскрешение классики
Microsoft выбрала стратегию, кардинально отличающуюся от Google. Вместо создания миров с нуля корпорация сфокусировалась на сохранении и воскрешении существующего игрового наследия. Их проект называется World and Human Action Model, или WHAM.
Для его обучения инженеры Microsoft собрали беспрецедентный датасет — семь лет непрерывного геймплея из Bleeding Edge, что составляет более миллиарда отдельных кадров с соответствующими действиями контроллера. Система проанализировала каждое движение, каждое решение, каждую тактику десятков тысяч игроков. В результате модель научилась не воспроизводить визуальную составляющую, а понимать глубинную логику игрового процесса.
Технически WHAM функционирует как «эмулятор памяти». Вместо выполнения программного кода система «вспоминает», как должна выглядеть и вести себя игра, основываясь на изученных паттернах. Это принципиально отличается от традиционной эмуляции, где воспроизводится работа оригинального оборудования. WHAM воспроизводит сам игровой опыт.
Microsoft видит в WHAM спасателя игровой истории. Представьте все те игры девяностых и двухтысячных, исходный код которых утерян. Игры, которые не работают на современных системах. Игры, права на которые запутаны так, что никто не может их переиздать.
Модель изучает записи геймплея старой игры и учится её воспроизводить. Не эмулировать в техническом смысле, а именно воссоздавать — генерировать геймплей, который выглядит и ощущается как оригинал, но работает на современном оборудовании без всяких костылей и эмуляторов.
По сути, WHAM совершает цифровое воскрешение. Мёртвые игры оживают, существуют снова — не как эмуляция, а как новая жизнь. Это похоже на восстановление вымершего вида по ДНК, только вместо генетического кода — паттерны геймплея.
Конечно, есть нюансы. Демонстрация Quake II от WHAM работала на десяти кадрах в секунду с разрешением 320 на 240 пикселей. Текстуры были размытыми, управление отзывалось с задержкой. Но это только начало. Учитывая скорость прогресса — от одного кадра в секунду в Genie 1 до двадцати четырёх в Genie 3 за полтора года — можно ожидать, что через пару лет WHAM будет генерировать классику в 60 FPS и Full HD.
NVIDIA GET3D: материализация идей
NVIDIA подошла к задаче с позиции своей традиционной экспертизы — графических вычислений. Технология GET3D генерирует трёхмерные модели с беспрецедентной скоростью — 20 объектов в секунду. Для контекста: профессиональный 3D-художник тратит от нескольких часов до нескольких дней на создание одной качественной модели.
Двадцать объектов в секунду — это скорость, недоступная человеку. За минуту GET3D создаёт больше уникальных предметов, чем средневековый ремесленник за всю жизнь. Мы дали машинам способность материализовать идеи со скоростью мысли. Текст становится формой, описание — объектом, слово — плотью виртуального мира.
Архитектура GET3D использует двухэтапный процесс генерации. На первом этапе создаётся базовая геометрия объекта — грубая форма, определяющая основные пропорции и структуру. Это похоже на работу скульптора, который сначала вырубает общие контуры из каменной глыбы. На втором этапе другая нейросеть добавляет детали: текстуры с разрешением до 4K, карты нормалей для имитации мелкого рельефа, параметры материалов для корректного освещения.
Обучение проходило на комбинации синтетических данных и реальных фотографий объектов с разных ракурсов. Система научилась понимать, как двумерные проекции соотносятся с трёхмерной формой — задача, которую человеческий мозг решает интуитивно, но которая десятилетиями считалась крайне сложной для компьютеров.
Tencent Yan: открытая альтернатива
Китайский гигант Tencent решил сыграть прямо на поле Google с их генерацией миров. Их проект Yan выложен в открытый доступ под лицензией Apache 2.0 — любой может скачать, изучить, модифицировать и использовать бесплатно.
Технические характеристики Yan впечатляют: генерация в разрешении 1080p со скоростью 60 кадров в секунду — это лучше, чем у Genie 3. Система поддерживает мультимодальный ввод — можно комбинировать текстовые описания с изображениями-референсами. Показываете фотографию реального замка, добавляете текст «сделать его парящим в облаках с драконами» — получаете готовую игровую локацию.
Архитектура Yan модульная. Она состоит из трёх независимых компонентов:
Yan-Sim отвечает за физическую симуляцию — гравитацию, столкновения, разрушения. Работает на основе learned physics — нейросеть обучена предсказывать физические взаимодействия без явного программирования законов физики.
Yan-Gen занимается визуальной генерацией — создаёт текстуры, освещение, эффекты частиц. Использует diffusion-модель, оптимизированную для работы в реальном времени.
Yan-Edit позволяет модифицировать мир на лету через текстовые команды или визуальные маски.
Модульность — ключевое преимущество. Разработчики могут использовать только нужные компоненты. Хотите улучшить физику в существующей игре? Берёте Yan-Sim. Нужна генерация ресурсов? Yan-Gen к вашим услугам. Это как конструктор, только для создания игр.
Но главное — Yan выложен в открытый доступ. Любой разработчик может скачать модель, изучить код, адаптировать под свои нужды. Если Google и Microsoft держат свои разработки за семью замками, предлагая только API за деньги, то Tencent фактически дарит технологию миру.
Моддеры: ИИ в руках энтузиастов
Пока корпорации соревнуются в создании фундаментальных технологий, обычные моддеры уже внедряют ИИ в любимые игры, и результаты действительно удивляют.
Возьмём Skyrim. Мод на основе проекта InWorld AI превратил молчаливых NPC в полноценных собеседников. Система использует локальную модель LLaMA-70B для генерации диалогов и Whisper для распознавания речи игрока. Можно подойти к любому стражнику и спросить его о жизни, о семье, о том, почему он выбрал эту профессию. И получить уникальный, никогда не повторяющийся ответ. Причём персонаж будет помнить предыдущий разговор.
Более того, существует множество энтузиастов, которые прикручивают обычные чат-боты к движку игры. Это тоже позволяет добиться эффекта «живых» NPC. Есть примеры в игре Morrowind, где персонажи ведут полноценные диалоги, не ограниченные заранее написанными репликами.
Да, есть проблемы. Задержка ответа составляет до пятисот миллисекунд — это заметно, особенно в динамичных играх. Иногда ИИ генерирует нелогичные ответы или «забывает» контекст игры. Средневековый крестьянин может начать рассуждать о криптовалюте, а постапокалиптический рейдер — цитировать Шекспира.
Но это технические проблемы, которые решаются. Главное — барьер входа рухнул. Не нужно быть программистом или иметь миллионный бюджет. Достаточно скачать специальный мод, немного настроить — и NPC оживут.
Игры нового поколения
Про Clair Obscur: Expedition 33 и использование генеративного ИИ в разработке уже упоминалось в начале, как и о заявлении Хидео Кодзимы. Главное — игры с продвинутым ИИ уже выходят или находятся в разработке, и они наглядно показывают, как изменится игровой опыт в ближайшие годы.
MIR5: адаптивные боссы
Начнём с революции в боссфайтах. Корейская Wemade Next внедряет в MMORPG MIR5 боссов на основе NVIDIA ACE. Эти боссы не просто сильные — они умные. Каждый раз, когда игрок проигрывает, босс анализирует тактику и адаптируется.
Победили босса огненной магией? В следующий раз ждите сопротивления к огню. Использовали определённую комбинацию способностей? Босс научится её контрить. Нашли слепое пятно в его атаках? Оно исчезнет. Босс буквально учится на ваших победах и поражениях.
Генеральный директор Wemade Next Чон Су Пак называет это «вехой в гейминге». И он прав — впервые в истории каждый боссфайт уникален. Даже вернувшись к уже побеждённому боссу для фарма лута, игрок столкнётся с совершенно другим противником. Он помнит, как его убили в прошлый раз, и подготовился.
inZOI: симуляция общества
Корейская студия KRAFTON создала конкурента The Sims под названием inZOI. Их система Smart Zoi, построенная на ACE, делает каждого персонажа в городе по-настоящему автономным.
Представьте город, где каждый житель движим собственными целями. Парикмахер мечтает открыть свой салон и копит деньги. Студент готовится к экзаменам, но отвлекается на романтические отношения. Пенсионер борется с одиночеством и ищет новые хобби. И все эти истории развиваются параллельно, влияя друг на друга.
inZOI делает то, о чём мечтали создатели The Sims — создаёт настоящую симуляцию общества. Каждый человек в этом мире живёт своей жизнью, а пересекаясь, они создают эмерджентные истории, которые никто не программировал. Мы больше не сценаристы этих историй, а наблюдатели и участники.
Правда, судя по отзывам, технология ещё работает сыро, и постоянно случаются ошибки, или NPC просто становятся неадекватными.
Dead Meat: детектив нового уровня
Совершенно новый жанр представляет Dead Meat от Meaning Machine — детективная игра, где можно задать подозреваемому ЛЮБОЙ вопрос. Голосом или текстом.
Хотите обсудить алиби? Пожалуйста. Философию жизни? Без проблем. Признаться в любви? Почему нет.
NPC обработает любой вопрос и ответит в контексте своей личности. Жёсткий преступник не расколется от вежливых вопросов. Нервный свидетель может выдать важную информацию, если его успокоить. Это меняет жанр детективных игр полностью — больше никаких выборов из трёх вариантов ответа.
Dead Meat стирает последнюю границу: когда NPC может ответить на ЛЮБОЙ вопрос, обсудить философию или признаться в страхах — он перестаёт быть персонажем и становится личностью.
На выставке CES 2025 Dead Meat показали работающей полностью локально на видеокартах GeForce RTX 50 серии. Раньше игра требовала подключения к облачным серверам для генерации диалогов. Теперь всё происходит на компьютере пользователя. Meaning Machine использует систему Game Conscious AI на основе малой языковой модели NVIDIA Mistral-NeMo-Minitron-8B. Восемь миллиардов параметров работают прямо на видеокарте.
Масштаб трансформации
По данным Google, 90 процентов игровых студий активно экспериментируют с ИИ. Скорость создания контента выросла в три-десять раз. То, на что раньше уходили месяцы, теперь делается за недели.
По оценкам, рынок ИИ в играх достигнет одиннадцати миллиардов долларов к 2032 году. Для сравнения: сейчас весь рынок игр оценивается примерно в двести миллиардов, то есть речь идёт о существенной доле, с которой стоит считаться.
Технология развивается по экспоненте. То, что сегодня кажется фантастикой, завтра станет стандартом индустрии.
Игровые миры будущего: что дальше?
Давайте честно: игровая индустрия с вероятностью девяносто девять процентов будет фундаментально трансформирована искусственным интеллектом.
И здесь поражает скорость изменений. Восемнадцать месяцев назад Genie 1 с трудом генерировала две секунды примитивного платформера. Сегодня Genie 3 создаёт фотореалистичные миры, в которых можно играть минутами. Через восемнадцать месяцев? Возможно, часовые сессии в мирах, неотличимых от реальности.
А что если виртуальные вселенные станут настолько сложными и автономными, что начнут порождать собственные формы жизни — не запрограммированные, а эволюционировавшие? Представьте: вы создаёте мир и оставляете его на месяц. Возвращаетесь, а там уже целая цивилизация NPC со своей культурой, языком, историей.
Демократизация разработки
Совсем скоро подросток в своей спальне сможет за выходные создать простую игру с помощью ИИ. Через пару лет это будут игры уровня инди-хитов. Через пять — уровня третьего «Ведьмака» или второго Red Dead Redemption. Барьер входа падает так стремительно, что скоро единственным ограничением станет воображение.
Изменение профессий
Безусловно, это изменит рынок труда. Исчезнут ли профессии? Некоторые — да. Но при этом появятся новые специальности.
Архитекторы игровых миров — люди, которые не программируют, а описывают вселенные.
Дизайнеры промптов — мастера формулировок, способные в тысяче слов создать целую игру.
Кураторы ИИ-контента — те, кто отбирает лучшее из бесконечного потока сгенерированных миров.
А ещё, скорее всего, появится новая профессия — этические консультанты виртуальных миров. Специалисты, которые будут решать: имеем ли мы право выключить сервер, если там живут миллионы NPC с памятью и отношениями? Что делать, если искусственные существа начнут проявлять признаки страдания? Где граница между игрой и экспериментом над цифровой жизнью?
Эти вопросы кажутся научной фантастикой, но они могут стать реальностью быстрее, чем мы думаем.
Роль человека
Главное — человек не исчезнет из процесса. Его роль изменится: из ремесленника, складывающего код строчка за строчкой, он превратится в дирижёра, управляющего оркестром из нейросетей.
В то же время игры могут стать по-настоящему персональными. ИИ будет анализировать, как вы играете, что вам нравится, от чего вы получаете удовольствие, и генерировать контент специально для вас.
Впрочем, «аналоговые» игры останутся и обретут новую ценность, также как виниловые пластинки и плёночная фотография. И настоящий хардкор никуда не денется.
Философские вопросы
Главное изменение произойдёт не в играх, а в нас. Мы получим опыт, которого не было ни у одного поколения — опыт создания миров. Опыт наблюдения за рождением и эволюцией цифровой жизни. Опыт ответственности за существ, которые верят, что они реальны. Это изменит наше понимание реальности, сознания, самой жизни.
И тут возникает последний вопрос: если мы можем создавать такие совершенные симуляции — откуда мы знаем, что сами не живём в одной из них?
Заключение
Мы стоим на пороге фундаментальной трансформации игровой индустрии и, возможно, нашего понимания реальности. Технологии вроде Google Genie 3, Microsoft WHAM, NVIDIA ACE и Tencent Yan — это не просто инструменты для создания игр. Это технологии, которые дают человечеству беспрецедентную силу — силу создавать миры.
Впервые в истории барьер между воображением и реализацией становится настолько тонким, что почти исчезает. Текстовое описание превращается в интерактивный мир. Идея материализуется в цифровую реальность за секунды.
Мы научили машины не просто выполнять команды, а понимать законы природы, создавать причинно-следственные связи, порождать новые формы существования. Мы дали им способность творить.
И это только начало. Следующие несколько лет покажут, насколько далеко мы можем зайти на этом пути. Возможно, мы приближаемся к моменту, когда различие между симуляцией и реальностью станет не техническим вопросом, а философским выбором.
Будущее игр — это будущее, где каждый может быть создателем вселенных. Где воображение — единственный предел. Где цифровая жизнь может стать настолько сложной, что потребует от нас новых этических рамок и нового понимания того, что значит быть создателем.
Добро пожаловать в эру игровых миров, созданных искусственным интеллектом. Эра архитекторов реальностей уже началась.
Figure: как стартап за три года создал робота-гуманоида
Figure за 3 года создала робота-гуманоида, который работает на заводах BMW и бросил вызов Tesla и Boston Dynamics. Узнайте, как стартап совершил проры
Что может сделать технологический стартап за три года? Или лучше так: что может сделать за три года IT-стартап, занимающийся роботами?
Наверное, сделает пару анонсов для привлечения внимания пользователей и инвесторов и, возможно, представит полуготовый прототип робота, который хотя бы умеет двигать какой-то конечностью.
Но компания Figure не согласилась с таким подходом. За это время они смогли представить уже три версии своих роботов (включая самую свежую Figure 03, анонсированную 9 октября 2025 года), научили их ходить, думать и даже трудоустроили. И посмотрите на дизайн – что за стильный амбассадор будущего в титановом корпусе.
Давайте выясним, кто эти ребята такие? Что за гений-основатель компании и как он связан с американскими ВВС? А главное, за три года можно сделать робота, вполне себе ловкого, умного и даже социального? Продолжаем наш цикл разборов роботов-гуманоидов. Сегодня смотрим на переосмысление истории Давида и Голиафа в век роботов и высоких технологий. История о смелых выскочках, которые появились из ниоткуда и решили потягаться с мастодонтами рынка, такими как Tesla и Boston Dynamics, а также OpenAI.
Как бросить вызов Tesla и Boston Dynamics
Figure – это не просто компания. Это камень в огород Boston Dynamics и Tesla. Это вызов, за которым стоит человек с нетипичной для Кремниевой долины биографией.
И чтобы лучше понять компанию, стоит поближе познакомиться с ее основателем – знакомьтесь, это Бретт Эдкок.
Он продал маркетплейс, построил электросамолет, а потом посмотрел «Терминатора» и решил: «А что, если я построю такого же, но полезного?». Так в 2022 году родилась Figure – стартап с амбициями на покорение заводов, кухонь и, возможно, человечества.
Но не думайте, что Бретт – человек совсем не из мира технологий. До Figure он уже был у руля стартапа, и не одного.
Первый его успех – маркетплейс Vettery, он был его сооснователем и CEO. Vettery — это онлайн-платформа для найма. Она специализировалась на соединении работодателей с кандидатами в таких областях, как технологии, продажи и финансы.
В 2018 году маркетплейс был продан швейцарской кадровой фирме Adecco Group за примерно 100 млн долларов.
Далее Бретт переключился на технологии будущего, но начал не с роботов, а с летающего транспорта. Буквально сразу после продажи Vettery Эдкок со своим партнером по прошлому стартапу Адамом Гольдштейном основал компанию Archer Aviation. На этот раз компания специализировалась на разработке электрических летательных аппаратов вертикального взлета и посадки (eVTOL) для городских перевозок.
В 2021 году United Airlines заключила соглашение о покупке 200 таких аппаратов на сумму 1 миллиард долларов. В 2021 году Archer стала публичной компанией на Нью-Йоркской фондовой бирже с оценкой около 2.7 млрд долларов. Именно у этой компании был контракт с ВВС США. То есть электросамолет Бретта Эдкока серьезно рассматривался как транспорт будущего.
В апреле 2022 года Эдкок оставил должность со-директора, передав полномочия Адаму Гольдштейну, который стал единственным генеральным директором компании. В мае 2022 года Эдкок полностью покинул Archer Aviation и ушел из совета директоров компании.
И если говорить о дне сегодняшнем (по состоянию на ноябрь 2025 года), хоть коммерческое использование летающих такси Archer Aviation еще не началось в полном масштабе, компания активно развивается. В начале 2025 года Archer получила 300 млн долларов финансирования под руководством BlackRock, а в середине года – дополнительные 850 млн долларов. Кроме того, 6 ноября 2025 года Archer приобрела аэропорт Hawthorne в Лос-Анджелесе за 126 млн долларов, чтобы использовать его как стратегический хаб для сети воздушных такси и тестовую площадку для ИИ. Планы включают полеты из Манхэттена в аэропорт Ньюарк за 10 минут и парк аппаратов в Абу-Даби. Ожидается, что к концу 2025 года компания сможет производить по два аппарата Midnight eVTOL в месяц, а к 2030 году – до 650 в год.
После неба – на землю. Но не простую, а ту, по которой шагает робот с лицом-дисплеем и интеллектом от OpenAI (а позже – своим собственным).
Наконец дошли до главного: в мае 2022 года Бретт создал новое детище – Figure AI, став ее CEO. И сразу после основания компании Эдкок поставил, на первый взгляд, невыполнимую задачу – создать полноценный прототип за 12 месяцев.
Сначала над ним все посмеялись! А потом на сцену вышел Figure 01, точнее не на сцену, а в интернет. Буквально сам вышел, ногами.
Но что он умел? И выглядел ли он все также крипово, как его друзья из Boston Dynamics?
Первые шаги Figure 01
Через год после основания Figure выкатили непричесанного, но ходячего робота. Его имя — Figure 01, и он выглядел, будто его собирали из остатков от Optimus, Lego Technic и старого принтера. Это был робот-гуманоид ростом 168 сантиметров и весом 68 килограммов.
Корпус выглядел, как у университетского проекта по робототехнике – были видны шарниры, поршни, провода.
Но он не просто ходил. Он двигался так, что Skynet бы аплодировал стоя. Немного крипово, немного странно, зато — стабильно, сбалансировано и с моторикой на уровне. Внутри — мощные приводы с моментом силы 200 Нм, руки покрыты силиконом, чтобы не поцарапать ваше яблочко.
На борту у него семь камер, которые дают круговой обзор и позволяют понимать, что за дичь происходит вокруг. Руки хоть и были с пятью пальцами, но скорее напоминали кисти человечка из Lego. Ими он мог поднимать грузы до 20 кг, а двигался он со скоростью 1.2 м/с. Питался робот от аккумулятора, расположенного в рюкзаке на спине, прям как у школьника со сменкой.
Этого ранца с энергией хватало на 5 часов работы. Лицо — не лицо, а дисплей, на котором можно было бы запустить, скажем, Doom, но пока там датчики. Вообщем, выглядел он в лучших традициях роботов-гуманоидов – брутально, неуклюже, с торчащими проводами и блестел. Мы уже видели такой у Оптимусов и Атласов.
Кстати, забавный факт – перед тем, как присоединиться к команде Figure, текущий глава технического отдела Джерри Пратт почти 20 лет отработал в индустрии роботизированной техники, в том числе участвовал в разработке Атласов для Boston Dynamics.
Судя по всему, в мире роботов-гуманоидов все переплетено.
Но что же было в голове у этого Figure 01 – был ли он умен? И вот тут начинается магия.
Внутри Figure 01 — мозги от OpenAI, версия GPT-4. Не просто нейросетка, а целый мультимодальный мозг, который видит, слышит и помнит. Робот не просто повторяет команды, он учится, строит план действий и может логически связывать события.
Говорите: «Убери мусор» — и он действительно убирает. Просите: «Дай то, что можно съесть» — и он подаёт яблоко, а не геймпад. Уже неплохое достижение для устройства, которое создали за год.
Самое главное — он помнит, о чём шла речь. Сказали “дай его” — и он понял, что вы про карандаш, а не экзистенциальный кризис. Это называется работа с контекстом, и для роботов-гуманоидов это почти как осознанность у человека.
Инженер Figure по робототехнике и искусственному интеллекту Кори Линч описывал возможности робота, вернее его мультимодальной модели, следующим образом. Первая версия Figure была способна описывать впечатления, планировать действия, размышлять над воспоминаниями и даже делать выводы. Для этого модель от Open AI анализирует прошлые разговоры и генерирует ответ, исходя из этих данных.
Figure 01 стал для команды чем-то вроде первого наброска художника. Неуклюжий, но с характером. Брутальный, но умный.
Но если первая версия научилась ходить и думать – то вторая версия уже собирается зарабатывать себе на жизнь. Как? Смотрим дальше.
Figure 02 – Робот на стиле или как гуманоиду устроиться в BMW
Спустя год Figure выкатили Figure 02 — и вот тут уже пахнет серьезными намерениями. Это не просто вторая версия — это качественный сиквел с бюджетом от Netflix. Из тела пропали провода, а сам корпус — теперь как у премиум-гаджета: чёрный матовый и монолитный.
Если Figure 01 был роботом-стажером с проводами наружу, то Figure 02 — эдакий Я-робот из будущего Apple. Аккумулятор теперь встроен, мощнее вдвое — 2.25 кВтч и 7 часов работы на одном заряде. Шарниры закрыты, руки — с 16 степенями свободы, при этом могут таскать до 25 кг, сила сжатия — как у человека, а корпус выполняет еще и функции экзоскелета.
Пока не тянет на серьезный апдейт? Вот еще несколько новых фишек.
У Figure 02 экран занимает полголовы и светится, будто он в клубе. Завезли шесть RGB-камер — в голове, торсе и даже на спине. Появились микрофоны и динамики — можно разговаривать с ним голосом, как с ассистентом. Реально разговаривать. Не просто «Окей, Гугл», а полноценный speech-to-speech режим.
Внутри у нас стоит обновленная мультимодальная модель VLM (visual language model) от OpenAI. Она видит, слышит и говорит. Задания теперь выполняются в 3-4 раза быстрее, а точность выросла в 7 раз. И это уже не игрушка — робот пошёл на завод.
Причем буквально, его резюме устроило компанию BMW.
Представьте себе: Южная Каролина, город Спартанберг (символично, да?). Завод BMW. Цех. Среди людей — Figure 02. В тестовом режиме сортирует и устанавливает автодетали. Погрешность — менее 1 см. До 1000 операций в день, и всё это — на полном автопилоте. Цикл одной операции — 4 минуты. Уже круто.
По состоянию на октябрь 2025 года, роботы Figure уже 5 месяцев работают на производственной линии BMW X3, по 10 часов в день ежедневно. К ноябрю 2025 года это уже около 6-7 месяцев непрерывной эксплуатации, что подтверждает успешность партнерства.
Но тут Эдкок говорит “подержите мое пиво” и заявляет, что роботы могут работать вместе.
Robocop и его напарник, только без пистолетов. Роботы от Figure уже умеют делить задачу на части и координироваться между собой. Это уже не просто интеллект, это бета-версия командной работы Skynet. Такие механические коллеги и на обед не ходят, и мир при случае захватить смогут.
И всё вроде шло по плану: роботы всё лучше, интеллект всё умнее, BMW довольны, стартап тоже. Но внезапно снова залетает Эдкок и говорит, что у Figure и OpenAI расходятся в пути.
Что случилось? Зависть? Конфликт интересов? Конфликт философий? Альтману больше по душе Мерседес или у OpenAI тоже появились свои планы на гуманоидов?
Рождение Helix или как Альтману сказали “Да ну тебя!”
Сначала всё было мило: OpenAI инвестирует, Figure даёт роботов. Мир, дружба, жвачка. GPT-4 под капотом, мультимодальная модель работает, всё летает. Роботы распознают предметы, понимают команды, могут вести диалог.
Но как это обычно бывает в стартап-романах — пошли разговоры о будущем. И тут начались проблемы.
Брэтт Эдкок, CEO Figure, вдруг пишет в X (прим. ред. X — новое название Twitter): «Мы уходим от OpenAI. Будем делать свой ИИ». И объясняет, мол, нам нужна глубокая вертикальная интеграция, сторонний ИИ замедляет разработку, и вообще — мы хотим полный контроль.
OpenAI, мол, не слишком-то и горели идеей запихивать GPT в физические тела. Им ближе мир софта — чат-боты, ассистенты, API. А Figure хочет железо, которое реально двигается, говорит и решает задачи в реальном мире, ну и на кухне в принципе помогает. Фактически, Брэтт пытается сделать единый аппаратно-системный комплекс, где его компания будет производить нужный софт под нужное железо.
А вот еще одна интересная деталь: есть слухи, что OpenAI сами решили делать роботов. В 2021 они уже пробовали, но закрыли отдел. А в 2024 — снова пошли разговоры: «А может всё-таки?».
Figure такой подход явно не понравился. Кто хочет делиться секретами с будущим конкурентом? И тут — щелчок. Figure вырубают GPT и выкатывают своего красавца — Helix.
Helix — это не просто ИИ. Это как если бы GPT-4, Midjourney и бицепс объединились в одного робота. Он работает по архитектуре VLA — vision-language-action. То есть не просто “пойми картинку и скажи, что на ней”, а “пойми, скажи и сделай”.
Тут сделаем небольшое отступление и попробуем разобраться в устройстве искусственного интеллекта. У обычного ИИ три части:
LLM — отвечает за болтовню
Vision — за картинку
Адаптер — переводит одно другому
Такой принцип хорошо работает со статичными объектами, но в случае с роботами есть третий фактор – движение. Он должен понимать, как, чем и куда ему двигать. И тут уже нужен другой инструмент.
Для того, чтобы объединить еще и движения, нам потребуется модель VLA – vision-language-Action.
Vision отвечает за компьютерное зрение и считывает изображения с камер на корпусе
Language отвечает за понимание речи оператора и небольшого планирования
Action отвечает за формирование команд для актуаторов.
Также Helix — двухуровневая система:
Первый уровень: понимает голос, анализирует картинку, думает (200 Гц)
Второй уровень: даёт команды конечностям (9 Гц).
Робот думает медленно, но действует быстро — классическая формула успеха.
Самое крутое — роботы с Helix могут работать в команде. Как пчёлы, но с Wi-Fi. Один тянет коробку, второй подбирает — и всё без внешнего оператора. Учитывают действия друг друга, подстраиваются, делят задачи.
На видео — Figure 02 с другом раскладывают продукты быстрее, чем ты с мамой в Ашане. Это уже не просто автоматизация. Это настоящая координация. А зачатки такого — это уже базовый функционал для будущего, где у роботов будет командир и миссия.
Так Figure из партнерского проекта стал соло-игроком. Свой ИИ, своё железо, своя философия. Но смогут ли они вытянуть это всё без ресурсов OpenAI? И самое интересное – можно ли будет купить их робота?
Кстати, по состоянию на 2025 год, Helix продолжает развиваться: 7 июня 2025 года Figure анонсировала масштабирование Helix как нового state-of-the-art в логистике гуманоидов, а 20 февраля 2025 года представила Helix как generalist VLA-модель.
Несмотря на разрыв, некоторые источники все еще упоминают поддержку от OpenAI, но Figure подчеркивает независимость и фокус на собственном ИИ.
Робота в каждый дом или как начать продавать робота из коробки
Сегодня Figure уже не просто пилит технологию. У них есть четкий план: 100 000 роботов на продажу до 2028 года. Это не шутка.
Сам Эдкок заявил, что уже отгрузил несколько гуманоидов “одной из крупнейших американской компании”.
А философия такая: как машина Tesla, только вместо авто — гуманоид. Но кто будет просто так покупать дроида? Хорошо, может наша аудитория и будет, но остальным его нужно еще продать.
Продукту нужна целевая аудитория. И Figure её нашёл.
Давайте прикинем, кому, кроме гиков, нужны роботы-гуманоиды?
Самый очевидный ответ – логистика. Это жирный рынок, где куча рутинной работы, высокая текучка, и вечный дефицит сотрудников. Amazon, Carrefour, даже BMW – все хотят робота, который ходит, понимает голос, сам открывает двери, перетаскивает коробки, и не требует обеда и зарплаты — хватит только розетки.
Хотите роботов? Их есть у меня, подумали в Figure.
Возможно, вы подумали, что Figure может уделать такой возрастной стартап, как тележка, но у робота есть несколько преимуществ. Figure 02 (и последующие модели) можно:
Быстро обучить
Отправить в новое место
Он не болеет, не ноет, не увольняется
И главное — подстраивается под человеческую среду.
Не нужно переделывать склад. Робот — это гибкая замена человеку. Звучит как мечта директора по логистике. И кошмар для людей-сотрудников.
Но что поделать, будущее неумолимо наступает. А Figure не просто строит роботов — они делают продукт, который можно будет отправить по почте.
У них в планах:
Упакованный робот,
ПО из коробки,
Автономная настройка,
И поддержка через облако.
То есть: нажал кнопку — робот работает. Никаких программистов, никакой сборки.
Эдакий айфон с ручками и ножками. В сети есть пара фоток, на которых Figure 02 лежит в коробке и готовится к отправке. Выглядит стильно, надо сказать, напоминает чем-то боксы коллекционных фигурок.
Цену Figure пока не раскрывает. Но намекает: будет дешевле, чем нанять человека на год. То есть если обычный сотрудник стоит $30–40K в год (зарплата, налоги, страховка), то робот Figure должен быть окупаем за 12 месяцев. А дальше — чистая экономия.
Но мы знаем, что они не одни в этой гонке:
Tesla Optimus — готовится выйти на рынок.
Agility Digit — уже тестируется на складах Amazon.
G1 от Unitree — уже знает кунг фу
Xiaomi CyberOne — пока просто красивый концепт.
1X, Sanctuary AI и другие.
У всех — свои подходы. Но Figure — один из немногих, кто:
Делает своё железо и свой ИИ,
Уже показывает реальную работу в естественной среде,
И прямо говорит: да, мы идём в бизнес.
Figure — это не просто “роботикс стартап”. Это новая индустрия: дроиды, как персональные компьютеры в 80-х или как электрокары 10 лет назад. Что-то новое, интересное и передовое.
У них есть цель. Они хотят заменить тяжёлый ручной труд, освободить людей от монотонных задач и построить мир, где “человек занимается только творчеством, а не таскает коробки”.
Громко? Да. Амбициозно? Да не то слово. Но Бретт Эдкок и его команда уже доказали, что умеют удивлять. И может быть мы с вами наблюдаем, как Илона Маска подвинут с трона инноватора и визионера.
А теперь осталось посмотреть – выйдет ли у них стать Apple в мире роботов или получится громко лопнувший пузырь, типа LeEco.
Кстати, в октябре 2025 года Figure представила Figure 03 – третье поколение гуманоида, оптимизированное для Helix, быта и массового производства. Бретт Эдкок заявил, что новая модель на 90% дешевле в производстве, и компания фокусируется на создании «нового вида, а не просто роботов». Кроме того, в марте 2025 года был анонсирован BotQ – высокопроизводительная система для массового производства.
Как Disney оживили робота из «Звездных войн»
Disney создали робота из «Звёздных Войн». Умный дроид учился в симуляции и теперь гуляет в парках самостоятельно!
Знакомьтесь — это BDX Droid, милый двуногий робот из вселенной «Звёздных войн», которого зовут Бэш. Вы могли видеть его на презентации NVIDIA GTC в марте 2025 года, где он сканировал зрителей и вызвал всеобщий восторг.
Бэш и его друзья — Грик, Оскар и странный красный Рэд — уже больше года развлекают посетителей в Star Wars: Galaxy’s Edge. Они сканируют предметы, взаимодействуют с людьми, преследуют уток и даже снимаются в фильмах, как рассказал режиссёр Джон Фавро.
Роботы не просто машины, а настоящие персонажи с характером, которые эволюционируют на глазах: они держат баланс, преодолевают препятствия и выглядят живыми. Это прорыв в робототехнике, созданный не Boston Dynamics или Tesla, а Disney.
Папа Карло нашего времени
Disney давно занимается робототехникой — уже более 60 лет они создают механические фигуры для парков развлечений. За это отвечает подразделение Disney Imagineering, лаборатория, где сочетаются магия и технологии. Этот отдел разрабатывают самые передовые аниматроники в мире: персонажи выглядят так, будто сошли с экрана. Например, Нав’и из «Аватара» или Молния Маккуин из «Тачек» — они двигаются и выглядят реалистично, словно только что приехали с соревнований.
Но аниматроники — это всё же статичные куклы с повторяющимися движениями, пусть и идеально отточенными. BDX-дроиды — совсем другое: эти «утята» на электроприводах преодолевают препятствия, выдерживают толчки и ориентируются в пространстве. Здесь нужна не только анимация, но и серьёзная наука с инженерией.
Для разработки привлекли Disney Research — научное подразделение, где работают настоящие «Папы Карло». Они оживили даже Грута из «Стражей Галактики», сделав его милым и подвижным. Disney Research занимается всем интересным: от алгоритмов интерполяции кадров и нейросетевой компрессии (привет, «Пегому Дудочнику») до анимации персонажей и, конечно, роботов.
BDX создали всего за менее года командой из восьми человек. Корпус напечатан на 3D-принтере, комплектующие — обычные магазинные, обучение — на одной RTX 4090. Как это удалось? Благодаря трём экспертизам: анимации, науке и аниматронике.
Три робота, новая глава
Задача была сложной: роботы обычно либо функциональные (умные, но страшные), либо эмоциональные (милые, но бесполезные, как EMO, Pepper или NAO от SoftBank). Disney нужны были оба качества: персонаж, выражающий эмоции, взаимодействующий с людьми, но способный двигаться самостоятельно — сниматься в кино, развлекать в парках или даже гулять по лесу.
Решение — создать мультяшку и перенести её в реальность. Никто раньше этого не делал, но Disney справились благодаря экспертизе в анимации (натуральные движения), науке (обучение) и аниматронике (сборка).
Оживляем пиксели
Disney мастера в создании харизматичных 3D-персонажей, так что начали с профессионального аниматора: создали модель, риг (виртуальный скелет) и определили характер — походку, манеры.
Затем применили метод процедурной генерации походки от Disney Research. В мультиках анимация — ручная работа, но инструмент автоматизирует: создаёшь базовый шаг, задаёшь траекторию — и персонаж идёт. Меняя параметры (скорость, фаза, амплитуда), быстро генерируешь стили: быстрый бег, крадущийся дракон или хромающий динозавр. Переходы плавные.
Это не новинка — подобные технологии в играх и фильмах с 2003 года (публикация о Registration Curves). Инновация — адаптация для роботов с учётом физических ограничений.
Оживляя электронику
Робот — не мультик: есть кинематические ограничения (физика движения, шаг не шире ног, суставы не на 360°) и динамические (сила, вес, баланс, гравитация, трение).
Пока аниматоры работали, инженеры подбирали комплектующие и тестировали. В итоге: дроид высотой 66 см, весом 15,4 кг. Внутри — 5 приводов на ногу, 4 в шее, NVIDIA Jetson, IMU (мониторинг позиции), антенны, динамики, фонарики, батарея на час.
Анимация — полдела: персонаж в симуляции игнорирует физику. Нужно добавить вес, инерцию, моменты. Для этого — поместить в «Матрицу».
Обучение с подкреплением
Просто загрузить анимацию нельзя — покажите как пример, робот научится сам через Reinforcement Learning (метод «кнута и пряника»).
Идея проста:
Копия робота и анимации в симуляции.
Робот повторяет.
Награда за точность и баланс.
Штраф за резкость и падения.
Как в жизни: пример, попытки, ошибки, обучение. Но отличие — тысячи копий учатся параллельно, опыт суммируется, время ускоряется на GPU. Годы — в часы.
В симуляции роботы бегают, падают, встают. Полчаса — и «знает кунг-фу». Пугает!
Но есть проблема. Часто бывает так, что в симуляции ты Лев Толстой, а на деле так не получается. В науке это проблема известна как “разрыв между симуляцией и реальностью” или Sim-to-Real Gap. Преодолеть его не так-то просто. Но Disney Research смогли. Но как?
Как работает Sim-to-Real Gap?
Чтобы ожидания совпали с реальностью, в Disney Research приняли несколько крутых решений.
Первое. В симуляцию добавили реальное оборудование, установленное в роботе. А именно:
Они воссоздали работу низкоуровневого контроллера, который управляет моторами.
И сделали точные цифровые копии электроприводов, характеристики которых замерили заранее.
В итоге нейросеть училась управлять настоящим железом, а не просто дергать конечности «за верёвочки». Но дальше больше. Низкоуровневый контроллер не просто управляет приводами, у него есть ещё две важные функции.
Во-первых, он сглаживает управляющие сигналы, чтобы не перегружать приводы.
Во-вторых, он постоянно мониторит состояние приводов и положение робота в пространстве с очень высокой частотой — 600 Гц.
Это позволяет своевременно корректировать крутящие моменты, а также частично компенсировать неожиданные изменения внешней среды. Если робот оступился или его толкнули, контроллер сгладит удар за счёт жесткости приводов и демпфирования (амортизации).
А в жизни такие ситуации не редкость. Поэтому Disney приняли второе крутое решение — ввели в симуляцию случайные факторы:
Стали добавлять шум и помехи в сенсоры.
Менять коэффициенты трения с поверхностью.
В конце концов, толкать робота в корпус и произвольно менять массу разных частей тела робота.
Как говорят робототехники: не ткнешь робота палкой — день прошел зря.
Это называется рандомизация среды. Такой подход подготовил робота к суровой действительности. А главное позволил добться невероятной схожести между эталонными движениями и реальностью. Но это не единственный секрет Disney Research. Мы разобрались, как учили робота. А теперь посмотрим, чему именно его учили.
Самое классное, как Disney решили проиблему с переходом от одной анимации к другой. Они использовали многослойный подход! Как это работает?
Первый слой — это фоновая анимация. Даже когда робот просто стоит на месте, он что-то делает: двигает антеннами, моргает. Этот слой смешивается с движениями от управления джойстиком, другими политиками, например ходьбой, или триггерными анимациями.
При этом все переключения очень плавные за счет фазового сигнала. Анимационный движок всегда отслеживает, в какой фазе находится текущая анимация, и смешивает разные движения только при совпадении фаз. В результате дроид выглядит как живой, а переходы между разными состояниями практически незаметны. Но стоп! Если этим дроидом управляют люди, почему мистер Хуанг со сцены говорил, что дроид автономный? Это обман?
Система Newton
На GTC Хуанг назвал дроида автономным — не обман: версия с камерами, гуляют в парках более года (с апреля 2024 в Disneyland, с июля 2025 в Disney World limited time до августа, с обновлениями для жары). Автономия: 4 настроения: застенчивый, счастливый, злой, грустный.
Анонс Newton, физический движок с Google DeepMind и Disney Research. Раньше симуляции на GPU упрощённые, точные — на CPU (медленно). Сам движок же просчитывает динамику тел, контакты, трение, дифференциальную физику. Стоит учитывать, что всё это на GPU. Ускорение в 70 раз для гуманоидов, в 100 раз для манипуляций. Обучение, около 100 тысяч итераций. Грубо говоря уместить 2 дня обучения в полчаса.
Мы все чаще слышим про то, как нейронки прокачивают камеры наших смартфонов, да и не только камеры — голосовые ассистенты, также они уже пишут музыку и рисуют картины, кто-то это называет ИИ, а еще есть машинное обучение и глубокое обучение! Признайтесь, вы тоже до сих пор не улавливаете разницы между всеми этими понятиями. Это не дело в двадцать первом-то веке! Чем же они отличаются друг от друга? И кто из них будущий SkyNet, Altron или Jarvis? Сейчас мы разложим все по полочкам.
https://youtu.be/tDyDWVqBw5s
Перед тем как погрузиться в будущее, заглянем в прошлое!
В середине XX века, когда появились первые компьютеры, впервые в истории человечества вычислительные возможности машин стали приближаться к человеческим.
Z1. Германия
ENIAC (Electronic Numerical Integrator and Computer). США
ASCC (Automatic Sequence Controlled Calculator). США
Поэтому в учёном сообществе возник справедливый вопрос: а каковы рамки возможностей компьютеров, есть ли эти рамки вообще и достигнут ли машины уровня развития человека? Именно тогда и зародился термин Искусственный Интеллект.
В 1943 году американские ученые Уоррен Мак-Каллок и Уолтер Питтс в своей статье «Логическое исчисление идей, относящихся к нервной активности» предложили понятие искусственной нейронной сети, имитирующей реальную сеть нейронов, и первую модель искусственного нейрона.
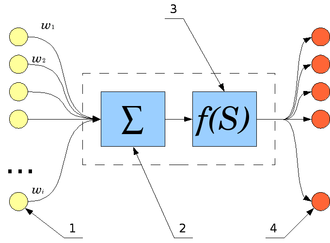
Схема устройства нейрона
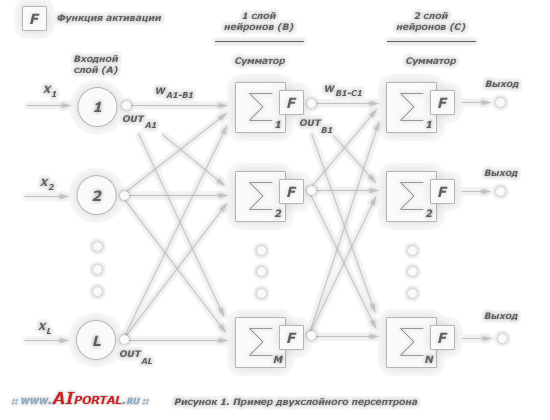
А в 1958 году американский нейрофизиолог Фрэнк Розенблатт предложил схему устройства, математически моделирующего процесс человеческого восприятия, и назвал его «перцептроном», что, собственно, стало прообразом нынешних нейросетей.
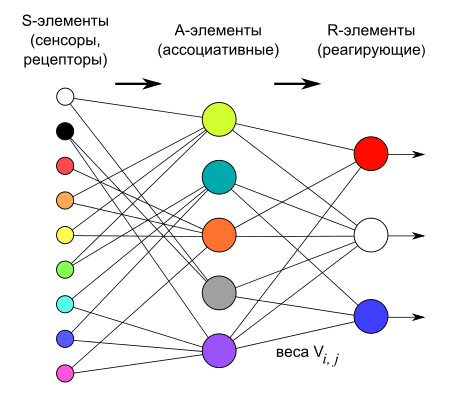
Логическая схема перцептрона с тремя выходами
А за несколько лет до этого, в 1950 году английский учёный Алан Тьюринг, пишет статью с громким названием «Может ли машина мыслить?». В ней он описал процедуру, с помощью которой можно будет определить момент, когда машина сравняется в плане разумности с человеком. Эта процедура сегодня носит название теста Тьюринга, о котором мы уже рассказывали ранее. Но вернемся к началу нашего повествования и ответим на вопрос: что же всё-таки такое “искусственный интеллект”?
Что такое ИИ?
Определений данному понятию существует большое множество, но все они сходятся в одном.
ИИ — это такая искусственно созданная система, которая способна имитировать интеллектуальную и творческую деятельность человека.
Причем интеллектуальная деятельность — это не просто математические расчеты, это деятельность, направленная на создание нематериальных вещей в сфере науки, искусства, литературы, а также в других творческих сферах, обучение, принятие решений, определение выводов и многое другое.
Естественно, обычный компьютер не способен написать картину, музыку или книгу. Для этого ему необходим интеллект — искуственный интеллект!
Но что может современный ИИ? Как можно оценить его интеллектуальные способности?
Чтобы это понять системы искусственного интеллекта можно разделить на три группы:
слабый (или ограниченный) искусственный интеллект;
общий искусственный интеллект;
сильный (или сверхразумный) искусственный интеллект.
Давайте разберемся с каждой по порядку.
Слабый ИИ
ИИ считают слабым, когда машина может справляться только с ограниченным набором отдельных задач лучше человека. Именно на данной стадии сейчас находится тот ИИ, с которым мы с вами сталкиваемся повседневно.
Примеров тут множество. Это ИИ в компьютерных играх — враги умнеют постоянно, вспомните тех же боссов в играх серии Dark Souls. Да и в повседневной жизни, отвечая на письмо в Gmail именно ИИ предлагает вам варианты ответов.
Конечно вряд ли такой ИИ способен на порабощение человечества. Но все же он уже может превзойти человека — к примеру, еще в далеком 1997 году машина Deep Blue от компании IBM сумела обыграть мирового чемпиона по шахматам — Гарри Каспарова.
Общий ИИ
Следующая стадия развития ИИ — это общий ИИ, когда компьютер может решить любую интеллектуальную задачу так же хорошо, как и человек.
Представьте себе, что компьютер способен написать картину не хуже Ван Гога, поболтать с вами по душам, сочинить песню, попадающие в мировые чарты, договориться с начальником о повышении или даже создать новую научную теорию!
К созданию общего ИИ стремятся сегодня ученые всего мира и в скором будущем нам, возможно, удастся узнать, что это такое, своими собственными глазами.
Уже сейчас Google Assistant может забронировать столик, общаясь по телефону с администратором (Google Duplex).
Еще в 2016 году самообучающийся твиттер-бот Тэй с ИИ, созданный компанией Microsoft, менее чем через сутки после запуска научился ругаться и отпускать расистские замечания, в связи с чем был закрыт своим же создателем.
А на последнем Google I/O нам показали проект LaMDA, с помощью которого можно поговорить, например, с планетой или с бумажным самолетом. За последнего, конечно же, будет отвечать ИИ.
Чего только стоит нашумевшая своим выходом осенью 2020 года нейросеть GPT-3 от OpenAI, которая откровенничала в эссе для издания The Guardian:
«Я знаю, что мой мозг — это не «чувствующий мозг». Но он может принимать рациональные, логические решения. Я научилась всему, что я знаю, просто читая интернет, и теперь могу написать эту колонку».
Данная нейросеть выполняет функцию предсказания следующего слова или его части, ориентируясь на предшествующие, а также способна писать логически связные тексты длиной аж в несколько страниц!
А совсем недавно, летом 2021 года, на базе GPT-3 был создан GitHub Copilot от GitHub и OpenAI, представляющий из себя ИИ-помощника для автозаполнения программного кода.
Можно сказать — это первый шаг на пути создания машин, способных порождать себе подобных…
Окей, закрепили! Общий ИИ — это компьютер который может успешно имитировать мышление человека, но не более того…
Интересно, а будет ли такой ИИ способен к переживаниям, сочувствию, к душевным травмам? В идеале — да, но пока что сложновато представить себе компьютер на приеме у психолога. Казалось бы, что может быть еще круче, вот он киберпанк, андроиды как люди, что же дальше?
Сильный ИИ
Дальше — вершина эволюции ИИ или сильный ИИ.
Такая машина должна выполнять абсолютно все задачи интеллектуального и творческого характера лучше, чем человек. То есть во всем его превосходить.
Это самый настоящий ночной кошмар конспирологов, ведь никто не знает, насколько дружелюбными будут такие машины. Но, к счастью, это пока что лишь разговор о далеком будущем. Или не таком уж далеком?
Создание сильного ИИ может стать главным поворотным моментом в истории человечества. Идея заключается в том, что если машины окажутся способны выполнять широкий спектр задач лучше, чем люди, то создание еще более способных машин станет для них лишь вопросом времени.
В такой ситуации произойдет “интеллектуальный прорыв”: машины будут бесконечно совершенствоваться по сравнению с теми, что были раньше, а их возможности будут расти в постоянно ускоряющемся потоке самосовершенствования.
Считается, что этот процесс приведет к появлению машин со “сверхразумом”. Такой необратимый процесс носит название теории «технологической сингулярности». Такие машины станут “последним изобретением, которое придется породить человеку”, писал оксфордский математик Ирвинг Джон Гуд, представивший возможность такого интеллектуального прорыва. Невольно вспоминаются сцены из серии фильмов “Терминатор” Джеймса Кэмерона.
Что такое машинное обучение?
Ну хорошо, с ИИ мы вроде бы разобрались. А что же тогда такое машинное обучение и как эти понятия связаны?
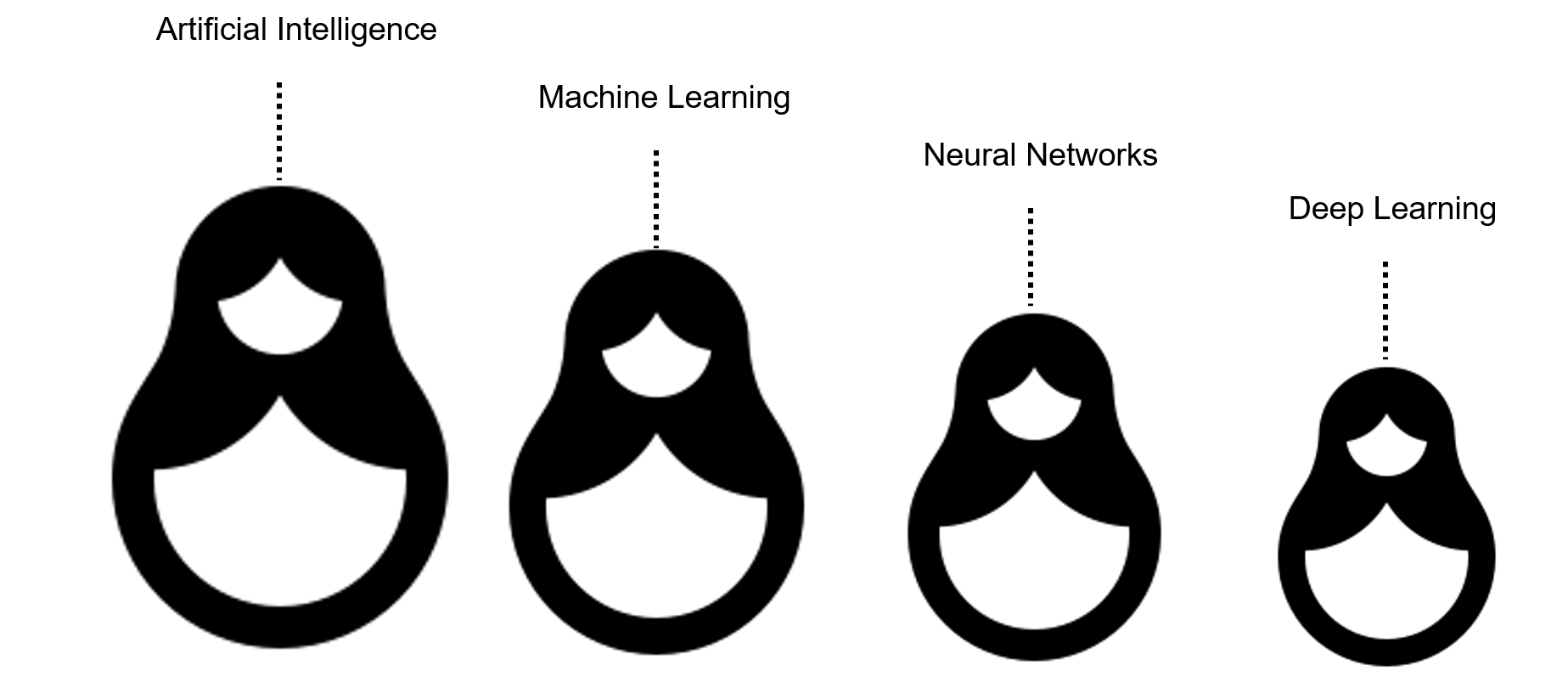
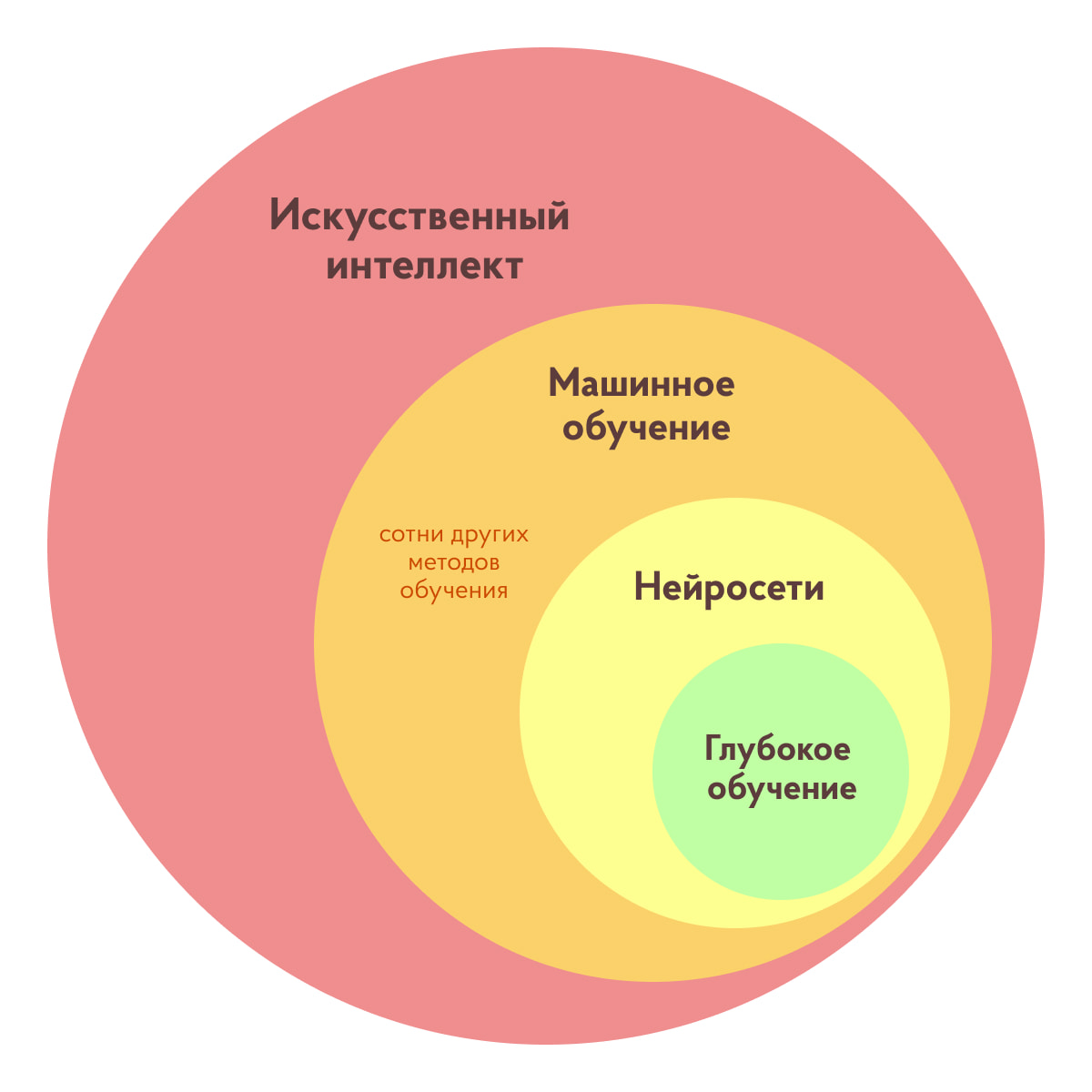
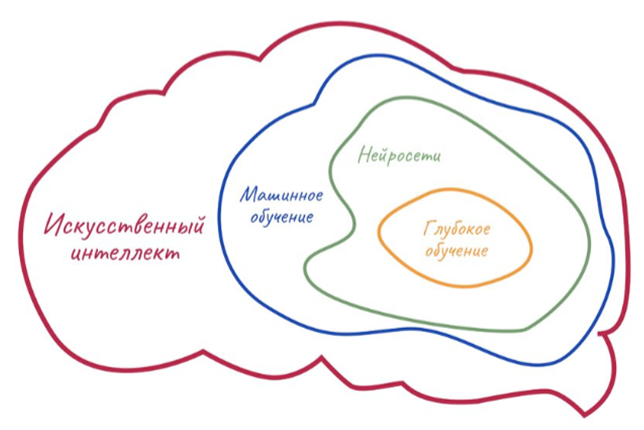
Напомним, что ИИ — это самый общий термин, включающий в себя все остальные понятия.
Для простоты ИИ можно представить как своеобразную матрешку. Самая крупная кукла — понятие ИИ в целом. Следующая кукла чуть поменьше — это машинное обучение. Внутри него кроется еще одна маленькая куколка — всеми любимые нейронные сети, а внутри них — еще одна! Это глубокое обучение, о котором мы поговорим чуть позже.
Как видите, машинное обучение является всего лишь одной из отраслей применения ИИ. И что же оно из себя представляет?
Попробуйте вспомнить, как вы освоили чтение. Понятное дело, что вы не садились изучать орфографию и грамматику, прежде чем прочесть свою первую книгу. Лишь зная алфавит и умея читать по слогам, сперва вы читали простые книги, но со временем их сложность постепенно возрастала.
На самом деле, вы неосознанно изучили базовые правила орфографии и грамматики и даже исключения, но именно в процессе чтения. Иными словами, вы обработали много данных и научились на них. Перенося такой подход к освоению навыков на ИИ, становится понятным, что машинное обучение — это имитация того, как учится человек.
Но как это можно реализовать?
Всё просто: необходимо лишь написать алгоритмы, которые будут способны к самообучению, к классификации и оценке данных, к выбору наиболее подходящих решений.
Снабдите алгоритм большим количеством данных о письмах в электронной почте, укажите, какие из них являются спамом, и дайте ему понять, что именно говорит о мошенничестве (наличие ссылок, каких-то ключевых слов и т.п.), чтобы он научился самостоятельно отсеивать потенциально опасные “конвертики”. Сейчас такой алгоритм уже реализован абсолютно во всех электронных ящиках.
У вас ведь было такое, когда письма по ошибке попадают в папку “спам”? Очевидно, что модель не идеальна.
При этом у машинного обучения есть много разных алгоритмов: линейная и логистическая регрессии, система рекомендаций, дерево решений и случайный лес, сигмоида, метод опорных векторов и так далее, и тому подобное.
По мере совершенствования этих алгоритмов они могли бы решить многие задачи. Но некоторые вещи, которые довольно просты для людей (например, распознавание объектов на фото, речи или рукописного ввода), все еще трудны для машин.
Но если машинное обучение — это подражание тому, как люди учатся, почему бы не пройти весь путь и не попытаться имитировать человеческий мозг? Эта идея и лежит в основе нейронных сетей!
Нейронные сети
Что же такое нейронка или искусственная нейронная сеть? Говоря по простому это один из способов машинного обучения!
Или правильнее — это разновидность алгоритмов машинного обучения, некая математическая модель, построенная по принципу организации и функционирования биологических нейронных сетей, то есть сетей нервных клеток живого организма. Некая цифровая модель нейронов нашего мозга. Как работает нейросеть мы уже рассказывали в другом материале.
Но все-таки для дальнейшего понимания коротко расскажем, как устроена нейронка.
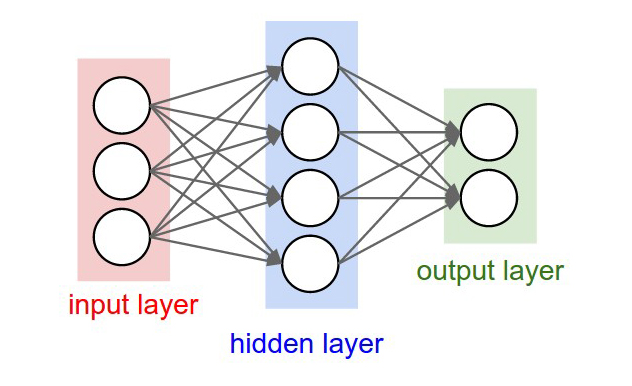
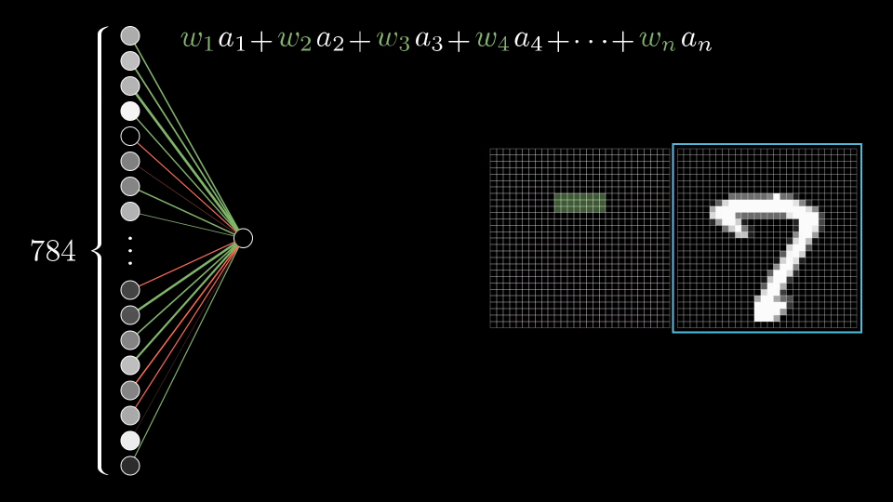
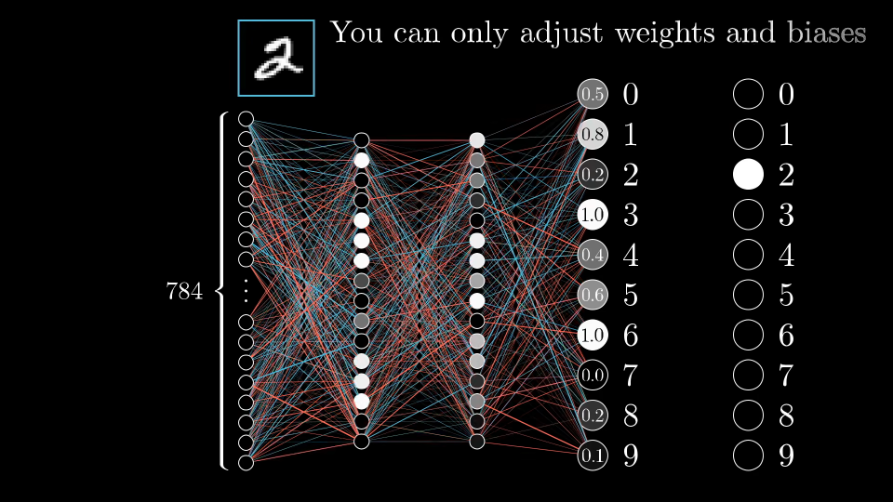
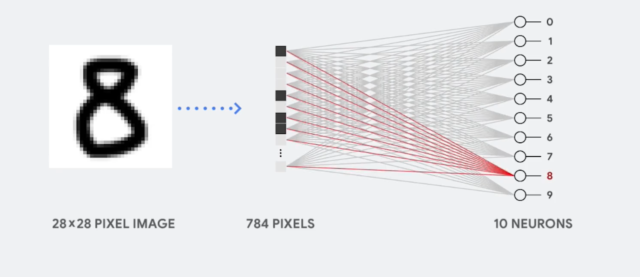
Возьмём, к примеру, перцептрон — простейшую нейронную сеть, о которой мы говорили в начале. Она состоит из трёх слоев нейронов: входной слой, скрытый слой и выходной слой. Данные входят в сеть на первом слое, на скрытом слое они обрабатываются, а на выходном слое выводятся в нужном виде.
Каждый искусственный нейрон в сети имитирует работу реальных биологических нейронов и представляет собой некоторую нелинейную функцию. А если по-простому — каждый нейрон — это ячейка, которая хранит в себе какой-то ограниченный диапазон значений.
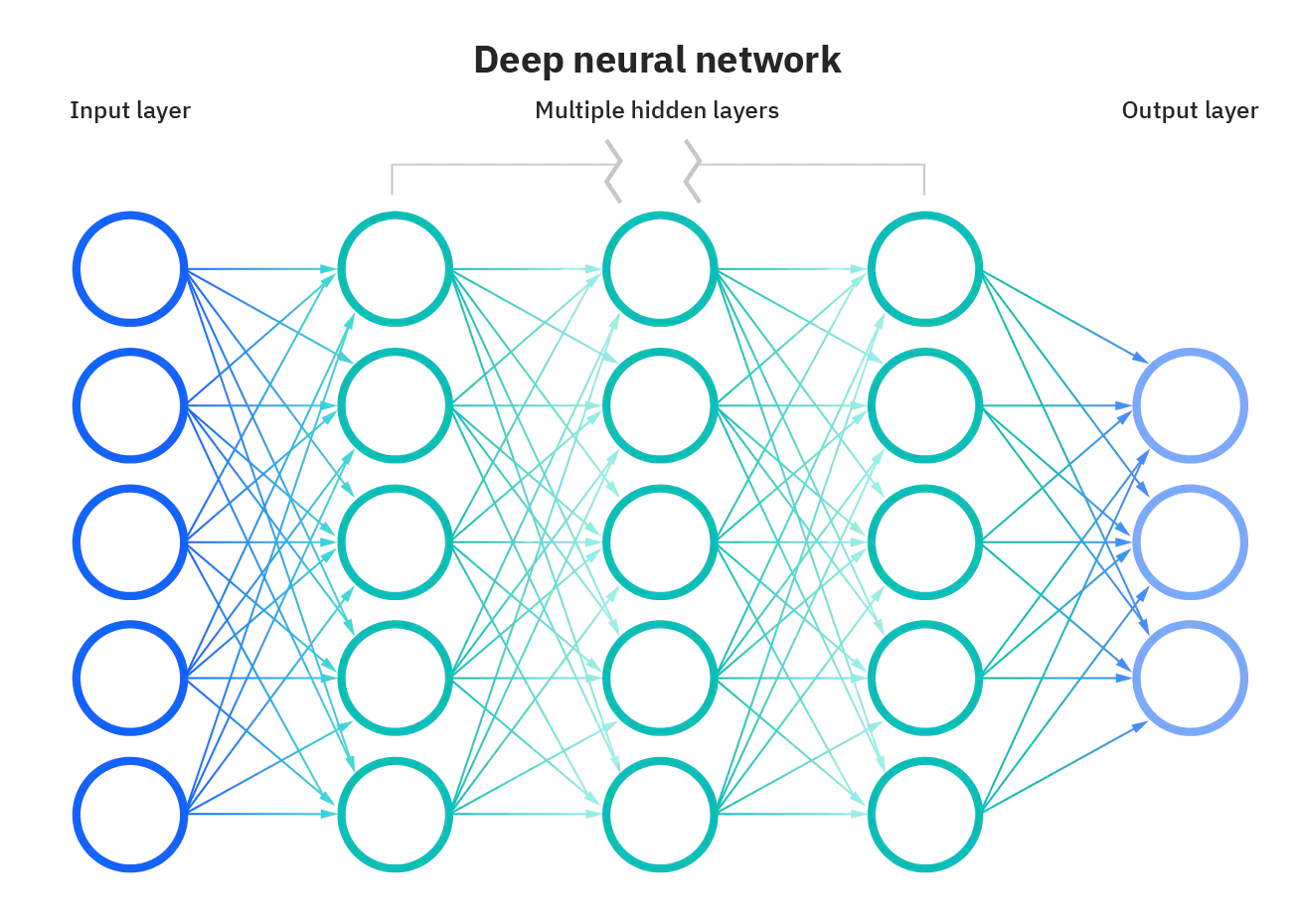
Но обычно тремя слоями все не ограничивается — в большинстве нейросетей присутствует более одного скрытого слоя, а механизм принятия решений в них, мягко говоря, неочевиден. Можно сказать, это как черный ящик. Такие сети называют глубинными нейронными сетями.
Зачем же нужны такие сложные и запутанные структуры и в чем их ключевая особенность?
У нас в мозгу реальные нейроны примерно таким же образом связаны между собой с помощью специальных синаптических связей.
Только в отличие от компьютерных нейросетей в мозге человека (только представьте себе!) порядка 86 миллиардов нейронов и более 100 триллионов синаптических связей! Именно такая сложная структура позволяет человеку быть человеком, позволяет проявлять интеллектуальную деятельность, о которой мы говорили ранее.
И — о чудо! — для искуственных нейросетей это работает очень похожим образом! Благодаря своему строению нейросети способны выполнять некоторые операции, которые способен делать человек, но не способны делать другие алгоритмы машинного обучения! Например, распознавать лица людей, писать картины, создавать тексты и музыку, вести диалоги и многое другое.
Вспомните, о чем мы говорили в самом начале ролика — все самые современные прототипы ИИ как раз основаны на нейросетях! Однако, сами по себе нейронные сети — не более чем набор сложно связанных искуственных нейронов. Для нейросетей самая важная часть — это обучение!
Глубокое (глубинное) обучение или Deep Learning
Так вот процесс обучения глубоких нейросетей называют глубоким или глубинным обучением. Этот подвид машинного обучения позволяет решать гораздо более сложные задачи для большего количества назначений. Но стоп, неужели до этого не додумались раньше?
Первые нейронки и программы, способные к самообучению появились еще аж в середине двадцатого века! В чем проблема? А вот в чем.
Раньше у человечества просто не было достаточных вычислительных мощностей для реализации работы нейронок, как и не было достаточно данных для их обучения. Даже сегодня классическим процессорам с двумя или даже с шестьюдесятью четырьмя ядрами (как в AMD Ryzen Threadripper PRO) не под силу эффективно производить вычисления для нейронных сетей. Всё потому что работа нейронок — это процесс сотен тысяч параллельных вычислений.
Да, это простейшие логические операции сложения и умножения, но они идут параллельно в огромном количестве.
Именно поэтому сегодня так актуальны нейронные процессоры или модули которые присутствуют в том же Apple Bionic, в процессорах Qualcomm или в чипе Google Tensor, состоящие из тысяч вычислительных ядер минимальной мощности. Как раз на них и возложена функция нейронных вычислений.
Собственно, по этим причинам только в середине нулевых годов нейросетям нашли реальное применение, когда все звезды сошлись: и компьютеры стали достаточно мощными, чтобы обслуживать такие большие нейронные сети, и наборы данных стали достаточно объёмными, чтобы суметь обучить эти сложные нейронные машины.
Так и возникло глубокое обучение. Оно предполагает самостоятельное выстраивание (тренировку) общих правил в искусственной нейронной сети на примере данных во время процесса обучения.
Это значит, что глубокое обучение позволяет обучить правильно настроенную нейросеть почти чему угодно. Ведь нейросеть самостоятельно выстраивает алгоритмы работы!
То есть при правильной настройке и достаточном количестве данных нейросеть можно научить, и лица людей распознавать, и письменный тескт расшифровывать, или устную речь преобразовывать в текст или даже текст преобразовывать в графическое изображение. Как пожелаете!
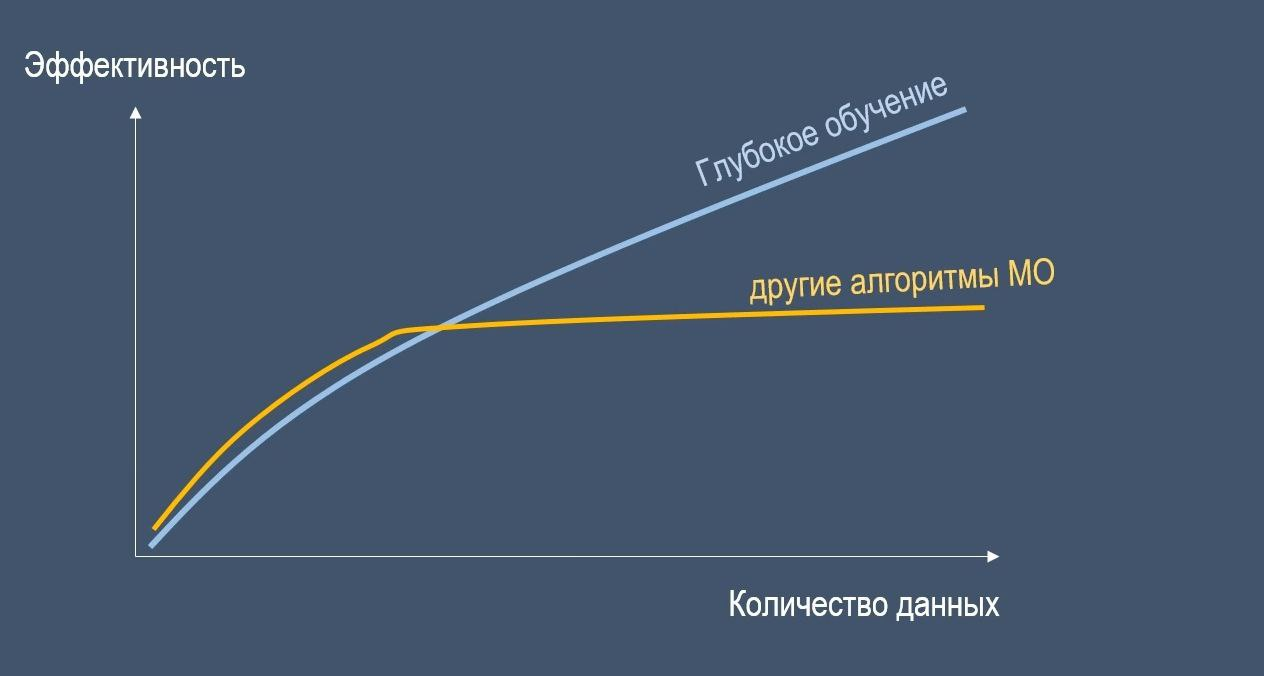
Также важно заметить, что для достижения высокой производительности нейронным сетям необходимо действительно огромное количество данных для обучения.
В противном случае нейросети могут даже уступать в эффективности другим алгоритмам машинного обучения, когда данных недостаточно.
Отличия сетей глубинного обучения от других алгоритмов машинного обучения
А вот небольшая таблица которая показывает отличия нейронных сетей глубинного обучения от других алгоритмов машинного обучения
Нейронные сети являются самым сложным вариантом реализации машинного обучения, поэтому они больше похожи на человека в своих решениях.
В качестве результата вычислений нейронки могут выдавать не просто числа, оценки и кодировки, но и полноценные тексты, изображения и даже мелодии, что не под силу обычным алгоритмам машинного обучения.
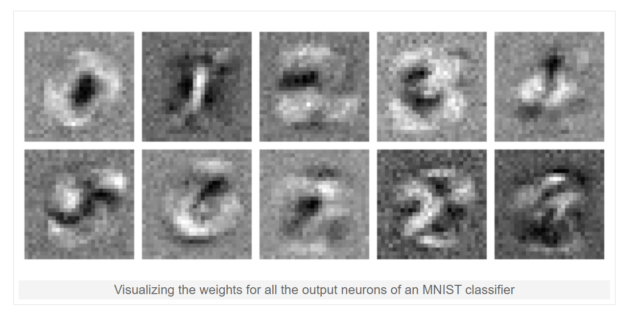
Яркий пример — нейросеть ruDALL-E от Сбера, способная создавать картины из текстовых запросов. Вот что выдала нам эта нейросеть на запрос “Droider.ru”:
Выглядит интересно: то ли какой-то ноутбук, то ли утюг, то ли степлер… В общем, явно что-то неживое и из мира технологий. И на том спасибо…
А вот парочка работ другой подобной художественной нейросети Dream by WOMBO по аналогичному запросу:
Ну а здесь уже более различимы какие-то силуэты дроидов. На мой взгляд, сверху настоящая крипота, напоминающая робота-зайца из “Ну, погоди”, а справа некий двоюродный брат R2-D2 из “Звездных войн”.
Оставляем сиё творчество исключительно на ваш суд!
Выводы
Что ж, надеюсь, что вы дочитали материал до конца и усвоили разницу в понятиях искусственного интеллекта, машинного обучения, нейросетей и глубокого обучения.
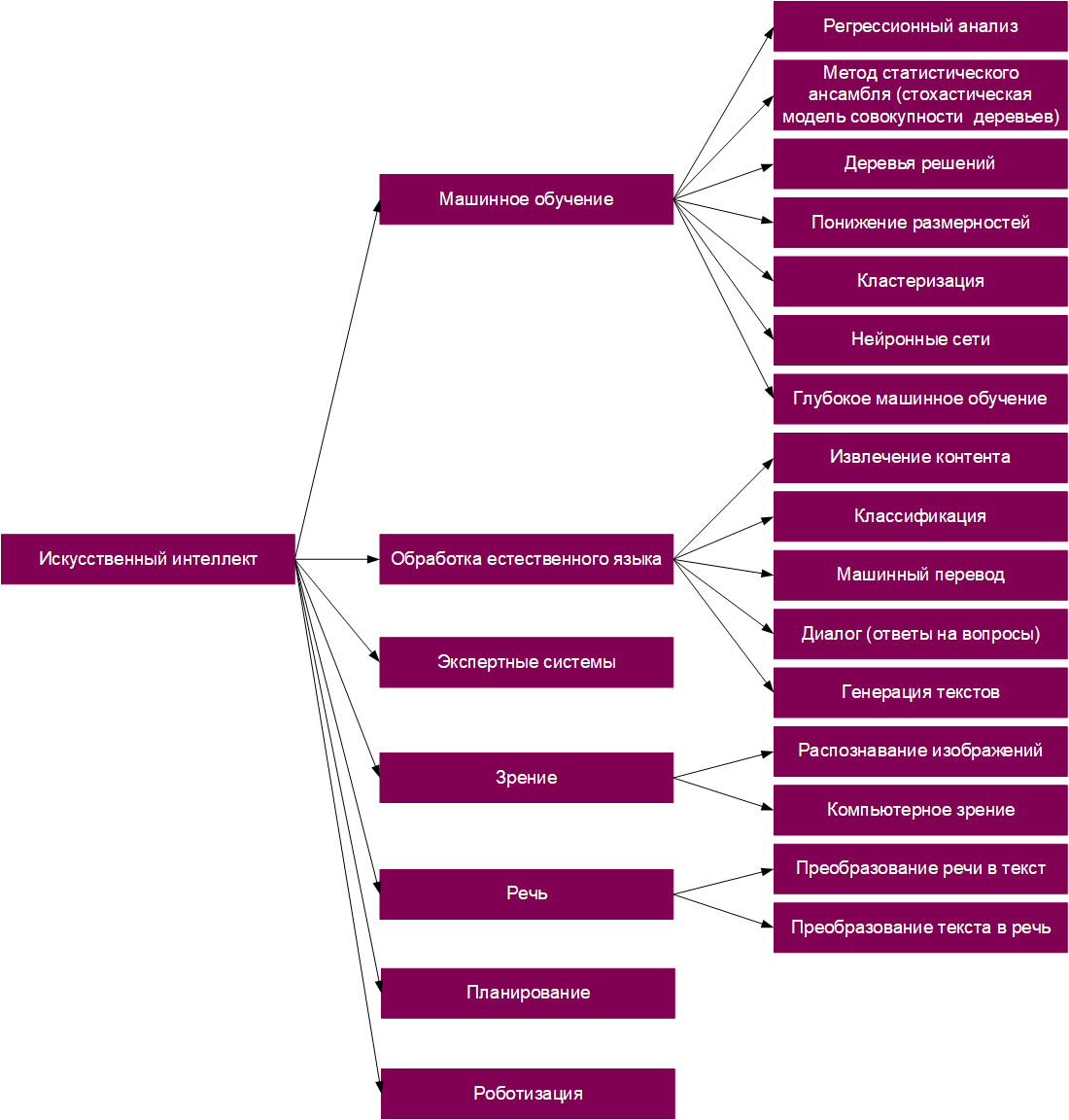
Теперь мы понимаем, что распознавание образов, лиц, объектов, речи, вся робототехника и беспилотные устройства, машинный перевод, чат-боты, планирование и прогнозирование, машинное обучение, генерирование текста, картин, звуков и многое-многое другое — всё это искуственный интеллект, точнее, разновидности его воплощений. Если совсем коротко резюмировать наш сегодняшний материал, то:
ИИ относится к устройствам, проявляющим в той или иной форме человекоподобный интеллект.
Существует множество разных методов ИИ, но одно из подмножеств этого большего списка — машинное обучение — оно позволяет алгоритмам учиться на наборах данных.
Нейронные сети — это разновидность алгоритмов машинного обучения, построенных по аналогии с реальными биологическими нейронами человеческого мозга.
Ну и, наконец, глубокое обучение — это подмножество машинного обучения, использующее многослойные нейронные сети для решения самых сложных (для компьютеров) задач.
Сегодня мы с вами являемся, по сути, свидетелями рождения искусственного разума.
Только задумайтесь: ИИ применяется сейчас практически везде. Скоро даже в сельском туалете можно будет получить контекстную рекламу на основе ваших персональных рекомендаций. И это далеко не всё. ИИ уже проходит тесты на “человечность”, может заменять нам собеседника и создавать произведения искусства. Что же дальше? Создание общего и сильного ИИ и порабощение человечества?
Так все-таки ИИ — это хорошо или плохо? И главное — сделает ли ИИ нас бессмертными? Можно ли будет оцифровать сознание?
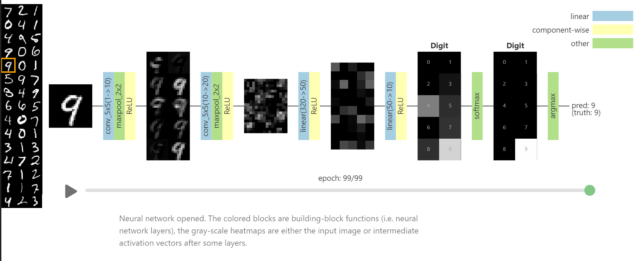
Как работают нейросети? Разбор
В наших материалах постоянно звучат слова Искусственный Интеллект и Нейросети. Так почему бы на просто примере не разобраться, как работают нейросети?
Нейросети, машинное обучение, искусственный интеллект. Звучит круто, но как это всё работает?
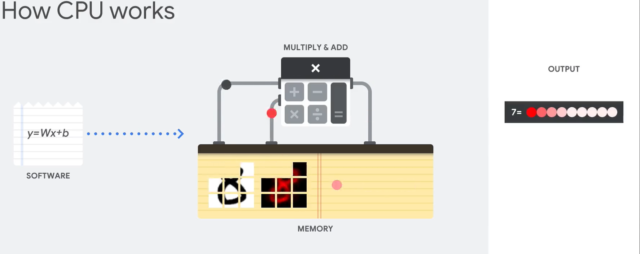
Объясню на простом примере. Представьте школьника, который пыхтит над контрольной по математике. И вот он подобрался к последнему уравнению, где нужно было вычислить несколько неизвестных (a, b и c) и посчитать ответ.
(a+b)*c=?
Он решает задачу и вдруг краем глаза замечает, что правильный ответ 10, а у него вообще не то — 120 тысяч. Что делать? По-хорошему, надо бы заново всё считать. Но времени мало. Поэтому он решает просто подогнать значения в уравнении, чтобы получился правильный ответ.
Он это делает и понимает, что значения a, b и с он посчитал неправильно еще в предыдущем уравнении. Поэтому там тоже надо всё быстро поправить. Он это делает и сдаёт работу.
Естественно, учительница палит, что он просто подогнал решение под правильный ответ и ставит ему двойку. И зря! Потому что, жульничество школьника на контрольной, можно считать прообразом метода машинного обучения, который позволил нейросетям совершить революцию в развитии компьютерного зрения, распознавания речи и искусственного интеллекта в целом. На разработку этого метода ушло целых 25 лет! И называется он алгоритмом обратного распространения ошибки.
Да-да, машинное обучение — это фактически подгонка уравнения под правильный ответ. Но давайте немного углубимся и поймем как это всё работает на самом деле, на примере простейшей нейросети.
Классические алгоритмы
Допустим, мы хотим научить компьютер распознавать рукописные цифры.
Как решить эту задачу? Отличник бы воспользовался классическими математическими методами.
Он бы написал программу, которая может определять специфические признаки, которые отличают одну цифру от другой. Допустим в 8-ке есть два кружочка, в 7-ке две длинные прямые линии и так далее. Вот только выявлять, что это за признаки и описывать их программе ему бы пришлось вручную. Короче надо было проделать кучу работы, и он бы всё равно обломался.
С такими задачами отлично справляются нейросети, потому как нейросеть может выявлять и находить эти специфические признаки самостоятельно. Как она это делает?
Для примера возьмём нейросеть с классической структурой, под названием многослойный перцептрон.
Структура нейросети
Нейросеть состоит из нейронов, а каждый нейрон — это ячейка, которая хранит в себе какой-то ограниченный диапазон значений. В нашем случае это будут значения от 0 до 1. На вход каждого нейрона поступает множество значений, а на выходе он отдаёт только одно. Наша нейросеть называется многослойной, потому, что нейроны в ней организованы в столбцы, а каждый столбец — это отдельный слой. Как видите тут целых четыре слоя.
Самый первый слой называется — входным. По сути, туда просто поступают входные данные.
Например, если мы хотим распознать картинку с цифрой размером 28 на 28 пикселей нам нужно, чтобы в первом слое нашей сети было 784 нейрона, по количеству пикселей в картинке.
Так как нейросеть может хранить только значения от 0 до 1 закодируем яркость каждого пикселя в этом диапазоне значений.
Следующие два слоя называются скрытыми. Количество нейронов в скрытых слоях может быть каким угодно, это подбирается методом проб и ошибок. Именно эти слои отвечают за выявление специфических признаков.
Значения из входного слоя поступают в скрытые слои, там происходит специфическая математика, значения преобразуются и отправляются в последний слой, который называется выходным.
В том нейроне выходного слоя, в котором окажется самое высокое значение, и высчитывается ответ. Поскольку в нашей нейросети мы распознаем цифры, то в выходном слое у нас 10 нейронов, каждый из которых обозначает ответ от 0 до 9.
Веса и смещения
Структура примерно понятна, но какие данные передаются по слоям и что за специфическая математика там происходит?
Разберем на примере одного из нейронов второго слоя.
В этот нейрон, как и в другие нейроны скрытого слоя, поступает сумма всех значений нейронов входного слоя. Напомню, что задача нейронов второго слоя — находить какие-то признаки. Например, этот нейрон мог бы искать горизонтальную линию в верхней части цифры 7.
Если бы мы действовали в логике классического алгоритма, то мы бы могли присвоить разным областям разные коэффициенты. Например мы предполагаем, что в верхней части изображения должны быть яркие пиксели, например горизонтальная палочка у 7-ки. Для этой области мы можем задать повышенные коэффициенты, а для других областей — пониженные. Такие коэффициенты в нейросетях принято называть весами. В формулах обычно обозначаются буквой w.
Теперь смотрите: перемножая входные значения яркостей на веса мы понимаем, была в этой области палочка или нет. Если признак найден, то в нейрон будет записано большое число, а если признака не было — число будет маленьким.
Но для того, чтобы активировать нейрон, нам нужно подать туда достаточно высокое число, выше какого-то порогового значения. В противном случае, нейрон выпадет из игры и дальше ничего не передаст.
Как это делается?
Мы знаем, что нейрон может содержать значения от 0 до 1. Но входяшие данные могут иметь значение существенно больше: мало того, что мы суммируем все значения из первого слоя, так мы еще их перемножаем на веса. Поэтому полученное значение нам нужно нормировать, например, при помощи функции типа сигмоиды или ReLU.
Но представьте, что на исходных картинках может быть шум, какие-то точки, черточки и прочее. Этот шум нужно как-то отсекать. Для этого в формулу вводится коэффициент смещения, по английски Bias, и он обозначается буквой b. Например, если Bias отрицательный — нейрон будет активироваться реже.
Вся эта функция, кстати называется функцией активации.
Все веса и смещения для каждого нейрона настраиваются отдельно. Но даже в небольшой нейросети типа нашей, весов и смещений более 13 тысяч. Поэтому вручную их настроить не получится. И как же нам задать правильные веса?
Обучение
А никак! Мы просто даем нейросети произвольные значения весов и смещений. И в итоге, естественно, мы получаем совершенно случайные ответы на выходе.
И вот тут мы можем вспомнить, что у нас, как и у двоечника в начале рассказа, есть преимущество. Мы знаем правильные ответы, а значит в каждом конкретном случае. мы можем указать нейросети насколько она ошиблась. И тут в бой вступает тот самый алгоритм обратного распространения ошибки! В чем его суть?
Допустим, мы загрузили в нейросеть цифру 2. если бы нейросеть работала идеально в выходном нейроне отвечающем за распознавание двойки было бы максимальное значение равное единице. А в остальный нейронах были бы нолики. Это значит что нейросеть на 100% уверена, что это двойка, а не что-то иное. Но мы получили другие значения.
Однако, поскольку мы знаем правильный ответ, мы можем вычесть из неправильных ответов правильные и подсчитать насколько нейросеть ошиблась в каждом случае. А дальше зная степень ошибки, мы можем отрегулировать веса и смещения для каждого нейрона пропорционально тому, насколько они способствовали общей ошибке.
Естественно, проделав такую операцию один раз мы не сможем добиться правильных значений на выходе. Но с каждой попыткой общая ошибка будет уменьшаться. И только после сотен тысяч циклов прямого распространения ошибки и обратного, нейросеть сможет сама подобрать оптимальные веса и смещения. Вот и всё! Так и работают нейросети и машинное обучение.
Другие структуры
Мы с вами рассмотрели самый простой пример нейросети. Но существуют масса архитектур нейросетей:
Нейросети сейчас называют новым электричеством. Мы их не замечаем, но пользуемся каждый день. Face ID в iPhone, умные ассистенты, сервисы перевода, и даже рекомендации в YouTube — всё это нейросети. Они развиваются настолько стремительно, что даже самые потрясающие открытия выглядят как обыденность.
Например, недавно в одном из самых престижных научных журналов Nature опубликовали исследование группы американских ученых. Они создали нейросеть, которая может считывать активность коры головного мозга и преобразовывать полученные сигналы в речь. С точностью 97 процентов. В будущем, это позволит глухонемым людям «заговорить».
И это только начало. Сейчас мы стоим на пороге новой технической революции сравнимой с открытием электричества. И сегодня мы объясним вам почему.
Как работают нейросети?
Центральный процессор — это очень сложный микрочип. Он умеет выполнять выполнять кучу разных инструкций и поэтому справляется с любыми задачами. Но для работы с нейросетями он не подходит. Почему так?
Сами по себе нейросетевые операции очень простые: они состоят всего из двух арифметических действий: умножения и сложения.
Например, чтобы распознать какое-либо изображение в нейронную сеть нужно загрузить два набора данных: само изображение и некие коэффициенты, которые будут указывать на признаки, которые мы ищем. Эти коэффициенты называются весами.
Вот например так выглядят веса для рукописных цифр. Похоже как будто очень много фоток цифр наложили друг на друга.
А вот так для нейросети выглядит кошка или собака. У искусственного интеллекта явно свои представления о мире.
Но вернёмся к арифметике. Перемножив эти веса на исходное изображение, мы получим какое-то значение. Если значение большое, нейросеть понимает:
— Ага! Совпало. Узнаю, это кошка.
А если цифра получилась маленькой значит в областях с высоким весом не было необходимых данных.
Вот как это работает. Видно как от слоя к слою сокращается количество нейронов. В начале их столько же сколько пикселей в изображении, а в конце всего десять — количество ответов. С каждым слоем изображение упрощается до верного ответа. Кстати, если запустить алгоритм в обратном порядке, можно что-нибудь сгенерировать.
Всё вроде бы просто, да не совсем. В нейросетях очень много нейронов и весов. Даже в простой однослойной нейросети, которая распознает цифры на картинках 28 x 28 пикселей для каждого из 10 нейронов используется 784 коэффициента, т.е. веса, итого 7840 значений. А в глубоких нейросетях таких коэффициентов миллионы.
CPU
И вот проблема: классические процессоры не заточены под такие массовые операции. Они просто вечность будут перемножать и складывать и входящие данные с коэффициентами. Всё потому, что процессоры не предназначены для выполнения массовых параллельных операций.
Ну сколько ядер в современных процессорах? Если у вас восьмиядерный процессор дома, считайте вы счастливчик. На мощных серверных камнях бывает по 64 ядра, ну может немного больше. Но это вообще не меняет дела. Нам нужны хотя бы тысячи ядер.
Где же взять такой процессор? В офисе IBM? В секретных лабораториях Пентагона?
GPU
На самом деле такой процессор есть у многих из вас дома. Это ваша видеокарта.
Видеокарты как раз заточены на простые параллельные вычисления — отрисовку пикселей! Чтобы вывести на 4K-монитор изображение, нужно отрисовать 8 294 400 пикселей (3840×2160) и так 60 раз в секунду (или 120/144, в зависимости от возможностей монитора и пожеланий игрока, прим.ред.). Итого почти 500 миллионов пикселей в секунду!
Видеокарты отличаются по своей структуре от CPU. Почти всё место в видеочипе занимают вычислительные блоки, то есть маленькие простенькие ядра. В современных видюхах их тысячи. Например в GeForce RTX2080 Ti, ядер больше пяти тысяч.
Всё это позволяет нейросетям существенно быстрее крутиться GPU.
Производительность RTX2080 Ti где-то 13 TFLOPS (FLOPS — FLoating-point Operations Per Second), что значит 13 триллионов операций с плавающей запятой в секунду. Для сравнения, мощнейший 64-ядерный Ryzen Threadripper 3990X, выдаёт только 3 TFLOPS, а это заточенный под многозадачность процессор.
Триллионы операций в секунду звучит внушительно, но для действительно продвинутых нейронных вычислений — это как запустить FarCry на калькуляторе.
Недавно мы игрались с алгоритмом интерполяции кадров DAIN, основанном на машинном обучении. Алгоритм очень крутой, но с видеокартой Geforce 1080 уходило 2-3 минуты на обработку одного кадра. А нам нужно чтобы подобные алгоритмы работали в риалтайме, да и желательно на телефонах.
TPU
Именно поэтому существуют специализированные нейронные процессоры. Например, тензорный процессор от Google. Первый такой чип в Google сделали еще в 2015 году, а в 2018 вышла уже третья версия.
Производительность второй версии 180 TFLOPS, а третьей — целых 420 TFLOPS! 420 Триллионов операций в секунду. Как они этого добились?
Каждый такой процессор содержит 10-ки тысяч крохотных вычислительных ядер, заточенных под единственную задачу складывать и перемножать веса. Пока, что он выглядит огромным, но через 15 лет он существенно уменьшится в размерах. Но это еще фигня. Такие процессоры объединяться в кластеры по 1024 штуки, без каких либо просадок в производительности. GPU так не могут.
Такой кластер из тензорных процессоров третьей версии могут выдать 430 PFLOPS (пета флопс) производительности. Если что, это 430 миллионов миллиардов операций в секунду.
Где мы и что нас ждёт?
Но как мы уже говорили, это только начало. Текущие нейронные суперкомпьютеры — это как первые классические мейнфреймы занимавшие, целые этажи в зданиях.
В 2000 году первый суперкомпьютер с производительностью 1 терафлопс занимал 150 квадратных метров и стоил 46 миллионов долларов.
Спустя 15 лет NVIDIA мощностью 2?3 терафлопса, которая помещается в руке стоит 59$.
Так что в следующие 15-20 лет суперкомпьютер Google тоже поместится в руке. Ну или где мы там будем носить процессоры?
Кадр из режиссерской версии фильма «Терминатор-2»
А мы пока ждём момента, довольствуемся нейромодулями в наших смартфонах — в тех же Qualcomm Snapdragon’ах, Kirin’ах от Huawei и в Apple Bionic — они уже тихо делают свою работу.
И уже через несколько презентаций они начнут меряться не гигагерцами, ядрами и терафлопсами, а чем-то понятным для всех — например, распознанных котиках в секунду. Всё лучше, чем попугаи!
Нейромодуль и ИИ: На что они способны уже сегодня?
Как нейронки смогут изменить наши смартфоны? Зачем нужен нейромодуль в процессоре? Что сможет камера в будущем iPhone или Pixel? Давайте разберёмся!
Сейчас во все мобильные процессоры впихивают нейронные модули. Neural Engine в процессорах Apple, DaVinci NPU у HUAWEI, AI Engine в Snapdragon’ах. Но что полезного они делают реально непонятно. Обычно всё сводится к всевозможным безумным бьютификациям и улучшайзерам.
Но нейронки сейчас могут творить абсолютно невероятную дичь! И могут нехило прокачать возможности наших смартфонов.
Сегодня мы покажем для чего в будущем будет использоваться нейронный модуль внутри вашего смартфона и какие крутые фишки можно делать уже сейчас!
Obstructional Removal
Начнем с камеры! Сейчас в приложении камеры на любом телефоне, есть масса бесполезных и “интеллектуальных” фич, типа определение сцены. Вот собачка, а вот цветочек говорит нам искусственный интеллект. И что? Мы это и так знаем!
Но вот чего не хватает, так это вот этой штуки: нейросеть удаляет с фотографий мешающие отражения и различные преграды, типа сетчатых заборов. Незаменимая вещь для любителей пофотографировать стройки и зоопарки.
Работает это очень интересно. Рассмотрим пример с отражением.
Во-первых, для того чтобы всё получилось нужно несколько кадров. Зачем? Чтобы вычислить оптический поток пикселей, т.е. движение в кадре. Дальше нейронка понимает, ага вот эти пиксели движутся что-то совсем не туда. Значит это отражение.
А дальше начинается настоящая магия. На основе данных о движении, нейронка восстанавливает два изображения: фон и отражение. Дальше вычитает отражение из фона и готово!
Думаете, такие фичи в смартфонах появятся еще не скоро. Обрадую вас, например в HUAWEI P40 Pro уже показали подобную функцию. Назвали это всё очень по-азиатски — Golden Snap. Она умеет удалять отражения и даже лишних людей из кадра! По-моему неплохо, ждём теперь реализацию от Гугла а потом и всё подтянутся!
Real Time Person Removal
Кстати, уже есть нейронка которая убирает людей из видео! В реалтайме! Вот тебе и кибер версия социального дистанцирования.
Алгоритм, таскающий картинки
Но мы то с вами что в кадре может мешать не только забор или человек. В кадре может быть лишним вообще всё! В этом случае поможет вот эта волшебная нейросеть.
Как это чудо работает? В нейронную загружается две вещи, изображение и разбивка на объекты в виде масок. То есть немного руками всё равно придётся поработать, но зато потом начинается настоящая услада.
Сначала нейронка определяет порядок объектов. Потом додумавает форму перегороженных объектов. А щзатем достраивает их!
Дальше остается только наслаждаться: можно передвигать объекты по кадру, менять их порядок, удалить всё что хочешь, и даже добавлять на снимок что-то новое.
Ну что тут скажешь, ждем когда алгоритм научат самостоятельно определять границы объектов и можно заворачивать в мобильное приложение. Революция фотожаб не за горами.
Кекфейс
И напоследок, из того что можно пощупать прямо сейчас! Есть масса нейросетей, оживляющих фотки. Но чтобы поиграться с ними нужно копаться на GitHub или в лучшем случае веб-интерфейсе, короче неудобно.
Но вот недавно появился бот в Телеграм @EORA_kekface_bot, который из любой фотки делает прикольные анимированные гифки. Зачем нужны анимоджи? Если можно свой набор стикеров на все случаи жизни.
Как думаете кто из крупных компаний первый догадается что-то такое сделать? Я ставлю на Samsung или HUAWEI, не всё же им за Apple повторять.
Итоги
Естественно, то о чём мы рассказали — это капля в море. В плене нейронок, что-то интересное происходит каждый день.
Например недавно Google показал чат-бот, который умеет осознанно общаться на любые темы! И его не отличить от человека.
Ребята сделали дипфейк Илона Маска в Zoom’е. То есть можно им стать, общаясь с друзьями в видеочате.
А еще, добрые люди омолодили, Мону Лизу и, “наше всё” Александра Сергеевича Пушкина.
Кстати мы, много подсмотрели на канале Neural Shit в Telegram.
Google представила Android 9.0 Pie
ОС уже доступна для всех поколений смартфонов Pixel
Компания решила выпустить Зеленого робота с пирогом в качестве официального десерта именно сегодня.
Напомним, что Android 9.0 Pie обладает нативной поддержкой «моноброви», переработанным экраном многозадачности, интуитивной функцией Do Not Disturb и множеством других нововведений.
Первыми смартфонами, которые получат юбилейную ОС по воздуху, стали линейка Pixel и Essential Phone. Кстати, файлы заводской прошивки для «пиксельфонов» уже доступны на сайтеGoogle.
Далее до конца осени обновление будет доступно обладателям моделей из линейки Android One, Xperia XZ2 от Sony, Mi Mix 2S от Xiaomi, Nokia 7 Plus от HMD Global, R15 Pro от Oppo, X21 от Vivo и OnePlus 6.