В последние годы интернет стал для нас чем-то вроде водопровода — вещью, которая всегда есть и просто работает. Однако за кажущейся простотой скрывается сложная инфраструктура, создававшаяся десятилетиями.
Технологии, обеспечивающие качественную и быструю работу глобальной сети, достойны нашего внимания. И главная из них — это HTTP, протокол, на котором буквально стоит весь современный интернет.
Когда HTTP был невидим
Если открыть браузер и ввести адрес YouTube, слева от названия сайта можно увидеть аббревиатуру HTTP. Правда, сейчас большинство браузеров её даже не отображают, но на самом деле это именно та база, на которой строится вся работа интернета. Стоит разобраться, что означает эта аббревиатура и почему она так важна.
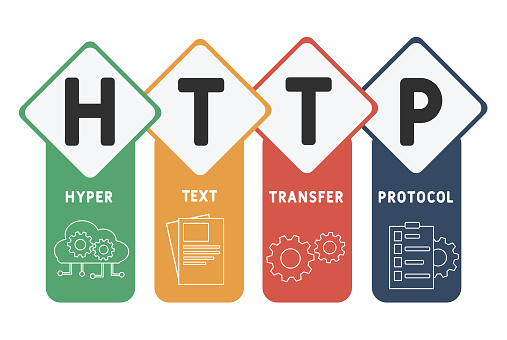
HTTP расшифровывается как HyperText Transfer Protocol — протокол передачи гипертекста. Таким образом, этот протокол решает две задачи: он работает с гипертекстом и обеспечивает его передачу между компьютерами.
Рождение Всемирной паутины
История разработки HTTP уходит корнями в конец 1980-х годов, когда в швейцарском научном учреждении ЦЕРН работал исследователь Тим Бернс-Ли. Именно он придумал то, что мы сейчас называем интернетом — точнее, Всемирную паутину, глобальную гипертекстовую сеть.

Однако идея соединить два компьютера и передавать между ними текст уже существовала. Например, была развита сеть FIDOnet, позволявшая обмениваться информацией между отдельными машинами. Революционность идеи Тима Бернс-Ли заключалась совсем в другом.
Во-первых, его протокол передавал не просто текст, а именно гипертекст — материал со встроенными ссылками.
Во-вторых, архитектура Всемирной паутины принципиально отличалась от FIDOnet. Вместо прямого соединения «клиент-клиент» (или «точка-точка») Бернс-Ли предложил использовать модель «клиент-сервер». Именно в этом заключалась главная инновация.
Что такое гипертекст и почему это революция
Гипертекст — это система страниц, которые имеют ссылки друг на друга. Проще говоря, с одной страницы можно перейти на другую, не вводя адрес, а просто нажав на ссылку. Это кажется очевидной вещью в 2026 году, но в реальности всё было совсем иначе.
В традиционных книгах гипертекста просто не существовало. Чтобы узнать определение какого-то понятия, читателю приходилось искать другую книгу, рыться в оглавлении или алфавитном указателе. Это значительно замедляло обработку информации, так как требовало одновременной работы с несколькими источниками.

Идея о том, что тексты, связанные общими понятиями, можно соединить через некие гиперссылки, появилась ещё раньше. В 1965 году американский социолог и философ Тед Нельсон в своём докладе определил гипертекст как материал, взаимосвязанный таким образом, что его невозможно представить на бумаге. Он может содержать карты взаимосвязей, аннотации, дополнения, сноски и многое другое.
После этого начались первые исследования и демо-проекты того, как гипертекст может быть реализован. Однако настоящим прорывом стало появление интернета — только тогда гипертекст превратился из теоретической идеи в массовое явление.
Как выглядит ссылка в интернете
Как же устроена ссылка в Сети? У неё есть собственный стандарт, называемый URL — Universal Resource Locator (универсальный указатель ресурса). URL есть у каждого видео на YouTube, статьи на сайте и даже у сообщения в Telegram.
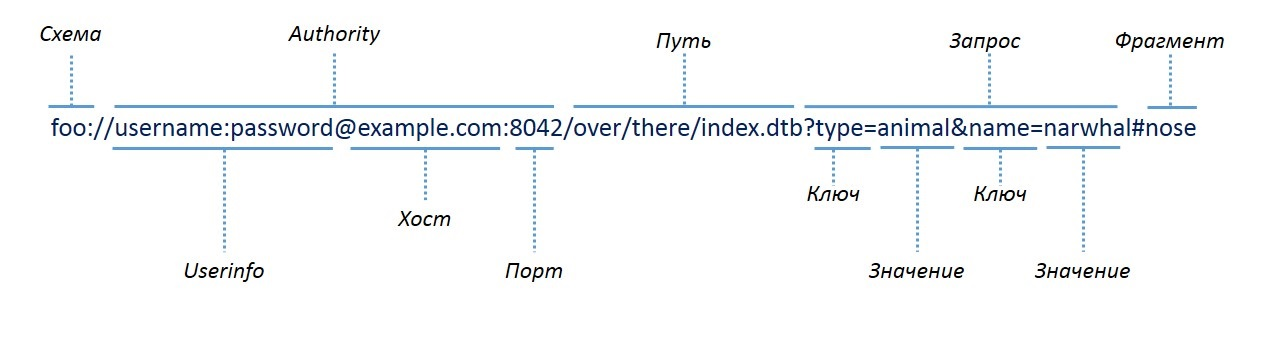
Рассмотрим конкретный пример ссылки на статью о iPhone 15 на нашем сайте:
https://droider.ru/post/iphone-15-specs/
Разберём этот адрес по частям:
- https — протокол (о том, чем https отличается от HTTP, поговорим позже)
- Двоеточие и две косые черты (://) — разделитель протокола и адреса
- droider.ru — имя сайта (хост)
- Всё остальное (/post/iphone-15-specs/) — путь к нужной странице на сервере
Раньше, когда интернет состоял исключительно из текстовых HTML-документов, лежащих в разных папках на серверах, любая ссылка оканчивалась расширением .html. Это было потому, что по такому пути находился один конкретный файл. Сейчас веб-сайты стали гораздо сложнее — они состоят из анимаций, переходов, скриптов и многого другого. Более того, современная страница обычно генерируется по запросу пользователя, а не берётся из готового файла на диске. Но в самом начале это была именно файловая система, подобная той, что вы видите на своём компьютере.
Гипертекст позволил всем быстро и удобно перемещаться по страницам без необходимости обращаться к адресной строке. Это может показаться мелочью, но это был ключевой аспект, который сделал интернет удобным и доступным. Благодаря гипертекстовым ссылкам вы можете вечером начать читать статью на Википедии, а к утру вдруг обнаружить, что погружены в биографию совершенно незнакомого вам человека.
Архитектура клиент-сервер: масштабируемость в действии
Теперь поговорим о второй революционной идее Тима Бернс-Ли — архитектуре клиент-сервер. Формально всё здесь довольно просто:
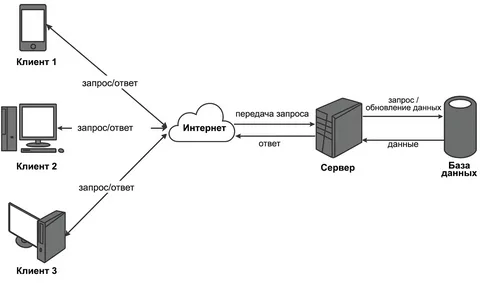
Клиент — это компьютер пользователя, на котором установлен браузер или другая программа, отправляющая запросы. Браузер запрашивает страницу у сервера.
Сервер — тоже компьютер, но специальный, со своим ПО. Он обрабатывает поступающие запросы и отправляет ответ: страницу, файл для скачивания или другие данные.
Но почему было решено передавать всё именно по схеме клиент-сервер, а не между клиентами, как в любительских компьютерных сетях?
В сетях типа FIDOnet не было понятия сервера. Иметь отдельный компьютер только для того, чтобы отправлять и получать данные, казалось неэкономично и просто не приходило никому в голову. К тому же постоянная передача и получение данных не требовались — для этого выделялись специальные временные отрезки, например один час в день.

Во Всемирной паутине требования были совершенно иные. Нужна была бесперебойная передача данных, чтобы клиент мог в любой момент загрузить страницу, почту, файлы или любой другой контент. При этом речь идёт не об одном клиенте, а о сотнях, тысячах, миллионах, миллиардах устройств одновременно.
Именно эта необходимость привела к появлению отдельного сервера как самостоятельного компьютера. И это дало HTTP и другим протоколам будущего интернета главное свойство — масштабируемость.
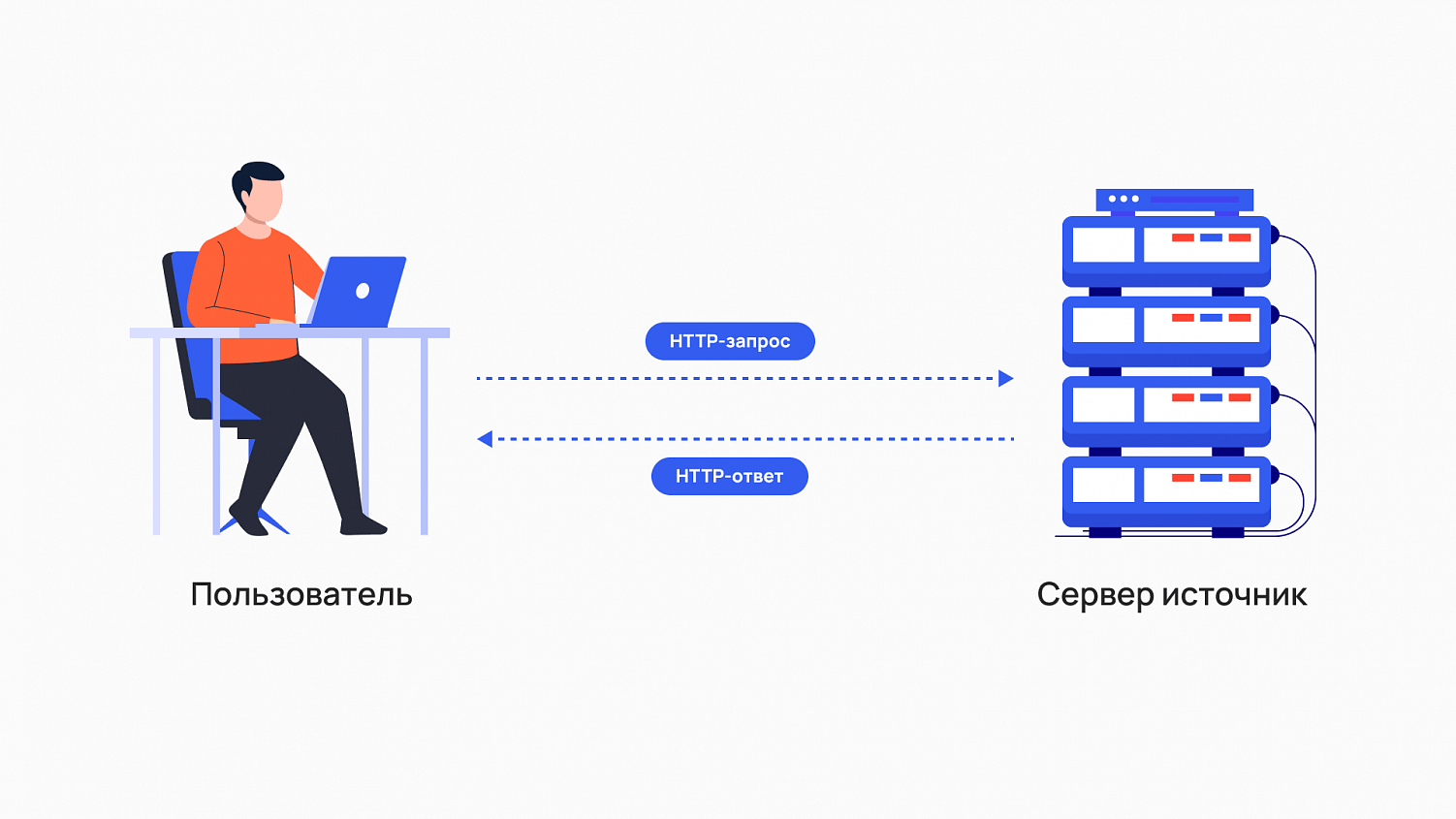
Масштабируемость означает следующее: если один сервер перестаёт справляться с нагрузкой, то она распределяется между несколькими серверами. Это обеспечивает бесперебойный доступ к критически важным ресурсам и сервисам. Именно благодаря этому свойству интернет смог вырасти до нынешних размеров.
Компьютер Steve Jobs, который запустил первый веб-сервер
Первый веб-сервер появился в 1990 году. Им стал компьютер Next Cube от компании Next, основанной Стивом Джобсом. Именно на этом компьютере был разработан самый первый веб-браузер под названием World Wide Web.

Операционная система Next Step была лучшей в своём роде на тот момент времени благодаря самым продвинутым средствам разработки. Забавно, что в 1996 году Apple приобрела компанию Next, и таким образом интернет начался с компанией, о которой сейчас далеко не все знают. Если вы хотели бы увидеть отдельный материал про Next и Стива Джобса этого периода, дайте нам знать в комментариях.
Как клиент и сервер общаются: HTTP-запросы
Итак, теперь у нас есть сервер и клиент, между ними установлено соединение. Но как именно они обмениваются информацией?
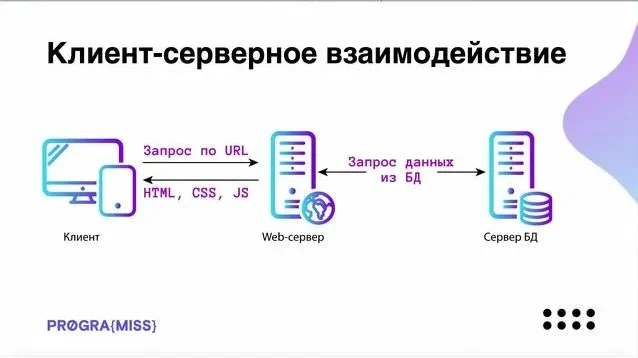
Разберёмся с каждой строкой:
GET — это метод, команда, которая указывает серверу, что конкретно нужно сделать. Всего таких команд девять, но наиболее часто используются три: GET, HEAD и POST.
Адрес ресурса — показывает, какую страницу или файл запрашивает клиент (в сокращённом виде, без адреса сайта).
HTTP версия — указывает, какой версией протокола пользуется клиент.
Host — адрес хоста, то есть сайта, к которому направлен запрос. Почему это нужно? Потому что на одном IP-адресе могут находиться сразу несколько сайтов, и запрос должен попасть в нужное место.
HTTP-методы
Что делает каждый метод?
GET — запрашивает сведения о странице и её содержимое по указанной ссылке. В нашем случае это страница с дайджестом материалов за последнюю неделю.
HEAD — почти идентичен GET, но возвращает только информацию о странице, без самого содержимого.
POST — предназначен для отправки данных на сервер. Например, когда вы пишете комментарий к статье и нажимаете кнопку отправки, на сервер уходит запрос с методом POST, содержащий текст комментария и другие необходимые данные.

Остальные методы используются крайне редко, поэтому мы не будем на них останавливаться.
Заголовки ответа: что нужно браузеру
Когда сервер получает запрос, он отправляет ответ. Этот ответ содержит разные элементы, в том числе заголовки (headers) — информацию, необходимую браузеру для корректной обработки и отображения страницы.
Content-Type
Один из самых важных заголовков — Content-Type. Он даёт знать браузеру, какие именно данные отправляет сервер. Это необходимо, чтобы браузер правильно отличил страницу от ссылки на скачивание файла.
Expires
Другой значимый элемент — Expires. С ним связана интересная история.
Когда браузер получает ответ от сервера при использовании определённых методов HTTP, он сохраняет этот ответ в памяти — в так называемый кэш. При следующем идентичном запросе браузер не обращается на сервер заново, а использует сохранённые данные, экономя трафик.
Вы, вероятно, слышали фразу: «Почисти кэш браузера». Когда-то это было действительно необходимо, потому что страницы менялись редко. Однако в 2024 году большинство страниц динамические — они изменяются с течением времени. Заголовок Expires сообщает браузеру дату, по наступлении которой страница помечается как устаревшая и её кэш нужно очистить.
Set-Cookie
Последний важный элемент — Set-Cookie. Да, вы угадали, он отвечает за передачу cookies (печенья) в браузер.
Почему это нужно? Сайту требуется запомнить много информации о вас: вошли ли вы в аккаунт, содержимое корзины в интернет-магазине, статистику для отслеживания активности. Все эти данные сохраняются в небольших файлах в памяти вашего устройства. Это удобно, но представляет угрозу безопасности — именно поэтому сайты теперь спрашивают вашего согласия на использование cookies.
От HTTP к HTTPS: вопрос безопасности
Метод передачи информации через HTTP очень эффективный и удобный, но у него есть критический недостаток: вся информация совершенно не защищена. Любой может открыть и прочитать содержимое. И это опасно.
Проблема: MITM-атака
В HTTP изначально не было запланировано никакого шифрования. Это означает, что все заголовки, содержимое страниц и любая другая информация передаётся простым текстом, без защиты.
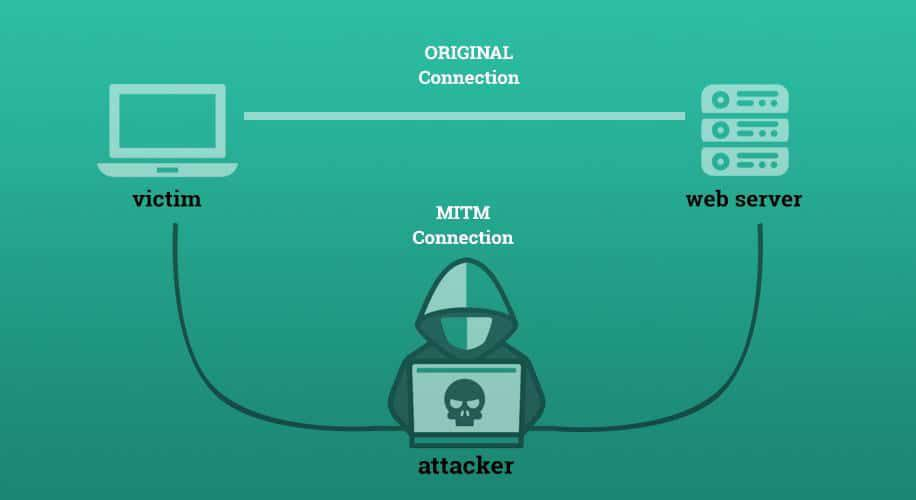
Если между клиентом и сервером появляется кто-то третий, он может просматривать и изменять любую информацию. При этом ни сервер, ни клиент не узнают о таком вмешательстве. А такое «звено» есть практически всегда — это может быть промежуточный сервер провайдера, другой клиент той же Wi-Fi сети или сама точка доступа.
Хакерские атаки такого типа получили название MITM (Man in the Middle — человек посередине).
Решение: HTTPS
Поскольку интернет быстро стал использоваться не только для чтения текстов, но и для передачи критически важных данных, потребовался способ защиты соединения.

HTTPS (HyperText Transfer Protocol Secure) — это безопасная версия HTTP. Он возник в 1994 году, хотя официально был утверждён только в 2000 году.
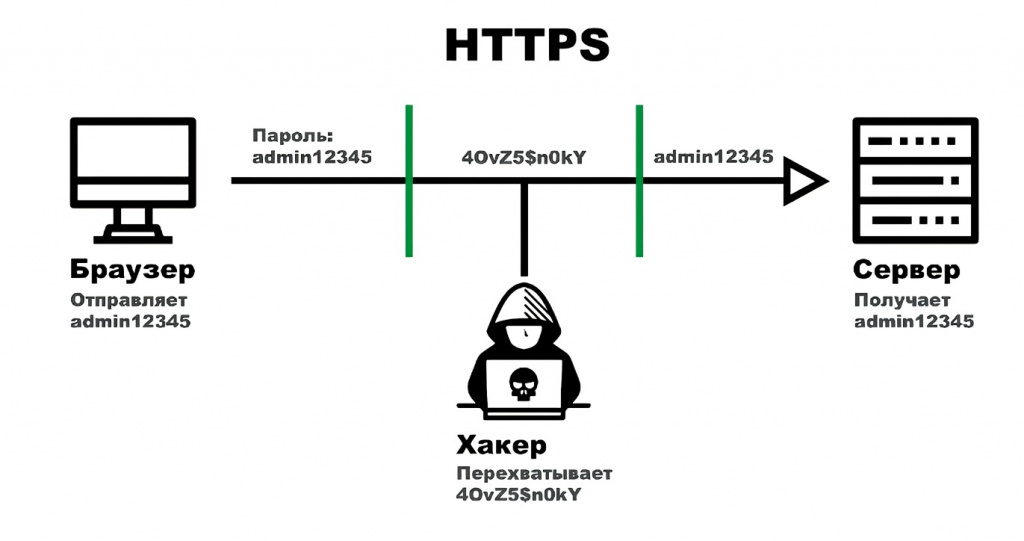
При использовании HTTPS все передаваемые данные шифруются. Это серьёзно усложняет задачу для потенциального злоумышленника. Технически MITM-атаки остаются возможны, но для их проведения требуется установка поддельного сертификата безопасности, что обнаруживается гораздо легче.
Угроза безопасности: Cookies
Однако у cookies остаётся одна проблема: они просто хранятся как файлы в памяти и не шифруются, не привязываются к устройству. Если передать cookies с одного устройства на другое, можно перехватить управление аккаунтом.
Именно так в марте 2023 года был взломан канал Linus Tech Tips (15 млн подписчиков). Один из сотрудников открыл программу, замаскированную под документ. Эта программа украла файлы cookies и отправила их злоумышленникам. Те загрузили cookies в браузер и получили полный доступ к каналу — без перехвата паролей, без хитрых социальных инженерных атак. Просто и эффективно.
Поэтому стоит быть осторожнее при открывании неизвестных файлов из интернета.
Эволюция HTTP: от 0.9 к 3
Интересно, что HTTP как технология, представленная на рубеже 1980-х и 1990-х годов, остаётся актуальной и в 2024 году. Но это не значит, что протокол застыл в развитии — он постоянно совершенствуется.
HTTP 0.9: начало
В первой версии HTTP (0.9) был только один метод — GET. Браузер мог запросить только HTML-страницы, никаких кодов ответа, никаких заголовков, никакой возможности отправить файл. Это была функционально ограниченная версия.
HTTP 1.0: появление методов и заголовков
HTTP появился в его современном виде только в ноябре 1996 года с версией 1.0. Именно тогда появились новые методы (GET, HEAD, POST), коды ответа, заголовки и возможность передавать не только HTML-страницы, но и любые другие данные.
HTTP 1.1: долгое доминирование
Буквально через несколько месяцев вышла версия 1.1. Она добавила механизмы, о которых мы уже говорили: управление кэшированием, указание кодировки страницы, загрузка страницы по кускам и многое другое.
И вот что любопытно: версия 1.1 оставалась самой свежей на протяжении почти 20 лет! HTTP2 вышел только в 2015 году. За этот период интернет прошёл огромный путь — появились видео, игры, веб-приложения, то есть появилась интерактивность. А значит, требовалась обработка гораздо большего количества запросов, и делать это нужно было быстрее.
HTTP 1.1 не был приспособлен к таким нагрузкам.
HTTP 2: ускорение
В версии 2.0 все изменения были направлены на ускорение загрузки страниц. За основу был взят экспериментальный протокол SPDY, созданный инженерами Google. Его использование позволило ускорить загрузку примерно в два раза.
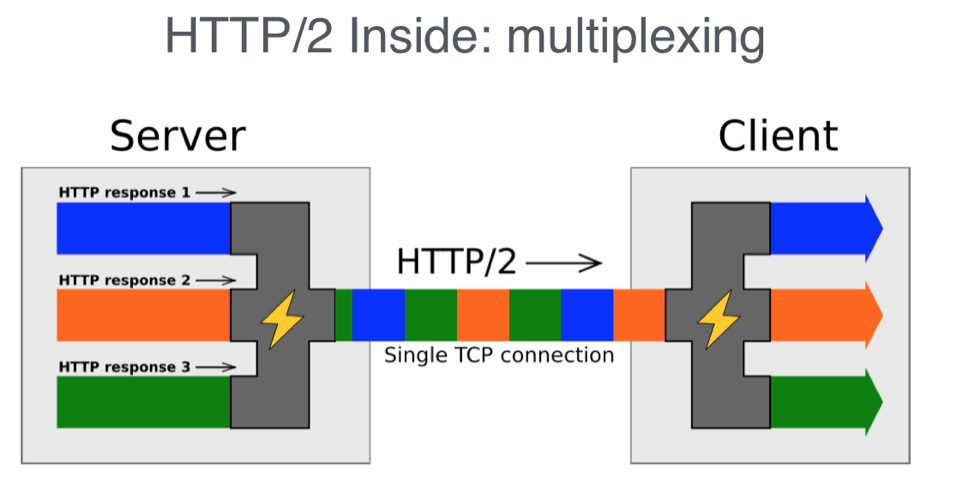
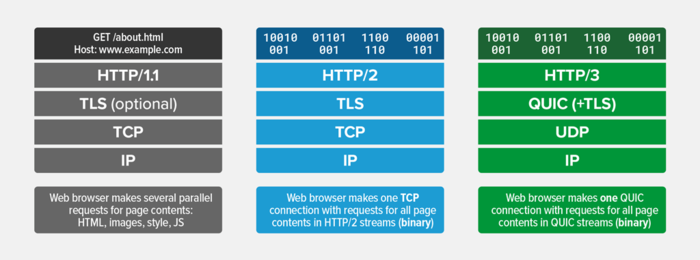
HTTP 3: текущий стандарт
Разработка HTTP 3 ещё формально не завершена, но с 2021 года её начали поддерживать все современные браузеры. Как и в случае с версией 2, основу составила разработка Google — на этот раз это транспортный протокол QUIC. Он тоже нацелен на ускорение загрузки страниц.
Почему не все переходят на новые версии?
Самое любопытное: HTTP 2 и 3 используются только на половине веб-сайтов мира. Остальные до сих пор используют версию 1.1. Но почему?
Переход на новую версию может быть довольно затратным на всех уровнях — от движка сайта до провайдера и серверов. Могут потребоваться новые инструменты для обработки запросов, множество изменений в конфигурации сервера и многое другое.
При этом все изменения протокола нацелены исключительно на ускорение загрузки — никаких новых функций, никаких инновационных возможностей не появляется. Далеко не всем сайтам нужна максимально возможная скорость.
Однако социальным сетям, видеохостингам и веб-приложениям эти изменения очень нужны. Поэтому новые версии используются в них более активно. Например, веб-версия YouTube уже использует HTTP 3, в то время как подавляющее большинство остальных веб-разработчиков придерживаются принципа: «Если работает — лучше не трогать».
Итоговая мысль

Ровно благодаря этому принципу HTTP уже 30 лет находится в строю. Это отличный пример технологии, которой мы пользуемся буквально по несколько раз в день, но при этом не знаем, как она устроена. Надеемся, этот разбор помог вам получить лучшее представление о том, как работает основа современного интернета.
