Ещё каких-то тридцать пять лет назад интернет был совершенно жутким местом. Действительно настоящей паутиной — запутанной, непроходимой и лишённой каких-либо ориентиров. Только представьте себе: чтобы найти нужный ресурс, вам приходилось искать его адрес в газете или специальном печатном каталоге. Да, речь идёт о времени до изобретения поиска в интернете.
А ведь, если задуматься, именно поиск изменил нашу жизнь и десятикратно облегчил доступ к информации. Это напоминает то, что сейчас, в 2025 году, происходит с искусственным интеллектом. Не находите?

В этой статье мы проследим весь путь поиска в интернете: как он зародился, как работает, почему он столь важен и, главное, какое будущее его ждёт.
Поиск вчера: от газетных вырезок до алгоритмов
Условно историю поиска можно поделить на три эпохи: каким он был вчера, что представляет собой сегодня и каким станет завтра. Давайте по порядку.
Главная проблема интернета прошлого — это отсутствие нормальной поисковой системы. Выкручивались все по-разному. Кто-то записывал на бумажке нужные ссылки. В кружках по интересам печатали журналы с адресами полезных ресурсов, а иногда информация передавалась просто из уст в уста, по старинке. Конечно, существовали и веб-подборки — специальные страницы, на которых можно было вручную искать нужный интернет-сайт. Не слишком удобно, но такая ситуация была вполне логичной: контента было мало, пользователей тоже, и в основном это были технические энтузиасты. Бизнеса в интернете не существовало как такового.
Archie — первый поисковик в истории
И вот молодой канадский студент по имени Алан Эмтейдж (Alan Emtage) устал от такого положения дел. Осенью 1990 года он представил первый в истории поисковик интернета — Archie (сокращение от «Archives»). Конечно, по нынешним меркам это была примитивная система, но даже в таком виде она значительно упростила жизнь людям.
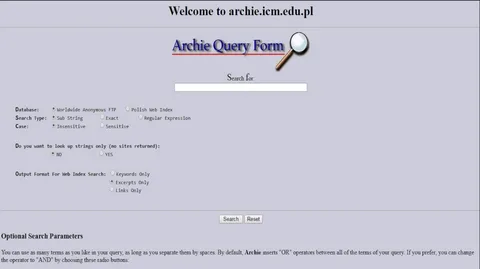
Archie объединял и индексировал содержимое общедоступных FTP-серверов. Возможно, кто-то ещё помнит такие «FTP-шники»: в те времена именно там можно было скачать игры вроде Duke Nukem, аниме или любой другой контент. Сервис собирал воедино названия файлов, а пользователю нужно было лишь ввести нужное ключевое слово. Проблема заключалась в том, что если в названии файла была ошибка, то Archie просто не мог его обнаружить.
Однако начало было положено. Цель тогда была проста: быстро находить хоть какую-либо подходящую информацию.
Индексация: библиотечная картотека для всего интернета
Чтобы двигаться дальше в изучении поиска, необходимо разобраться с одним чрезвычайно важным термином — индексация. Что вообще означает «проиндексировать интернет»?

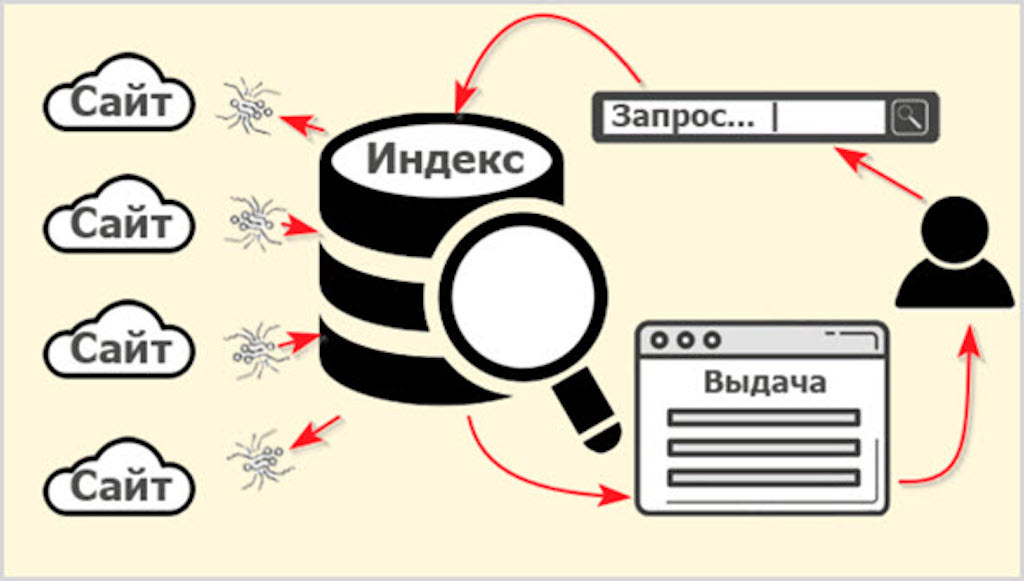
Чтобы любой поисковик мог найти нужный ответ, ему сначала необходимо создать некую базу данных, в которой этот ответ будет храниться. Но ведь весь интернет — это колоссальный объём данных. По некоторым оценкам, речь идёт о нескольких зеттабайтах. Для понимания масштаба: один зеттабайт равен миллиарду терабайт. А по данным на 2025 год, в интернете накоплено уже несколько десятков зеттабайт информации. Естественно, поисковик физически не может пропускать через себя каждый раз такой массив данных. Именно поэтому было найдено подходящее решение — индексация.
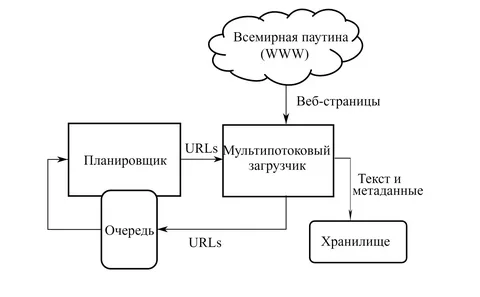
Принцип прост. Специальный поисковый бот регулярно обследует всё интернет-пространство и обрабатывает информацию. Сначала программа-планировщик выстраивает маршрут для обхода сайтов. Этот маршрут зависит от важных характеристик сайтов — например, их цитируемости или частоты обновления. Затем планировщик передаёт этот маршрут другой части поискового робота — так называемому «пауку» (crawler). Паук обходит документы по заданному маршруту, и если сайт работает и доступен, он выкачивает содержимое и отправляет его в хранилище.

Таким образом, бот создаёт нечто вроде слепка интернета — библиотечной картотеки, если угодно, которая хранится на серверах. Туда переносится не весь интернет целиком, а только полезная информация — без спама, дубликатов и прочих ненужных документов. В результате получаются проиндексированные веб-страницы: поисковик знает адрес, по которому находится подходящий запросу пользователя контент — слова, изображения или любые другие данные.
После индексации слепок веб-сайта добавляется в регулярно обновляемую базу данных, чтобы поиск не занимал много времени. Визуально увидеть проиндексированную веб-страницу обычный пользователь не может, однако с помощью специального инструмента это всё же возможно. Например, у Яндекса существует сервис Вебмастер, где можно проверить свой ресурс на индексацию.
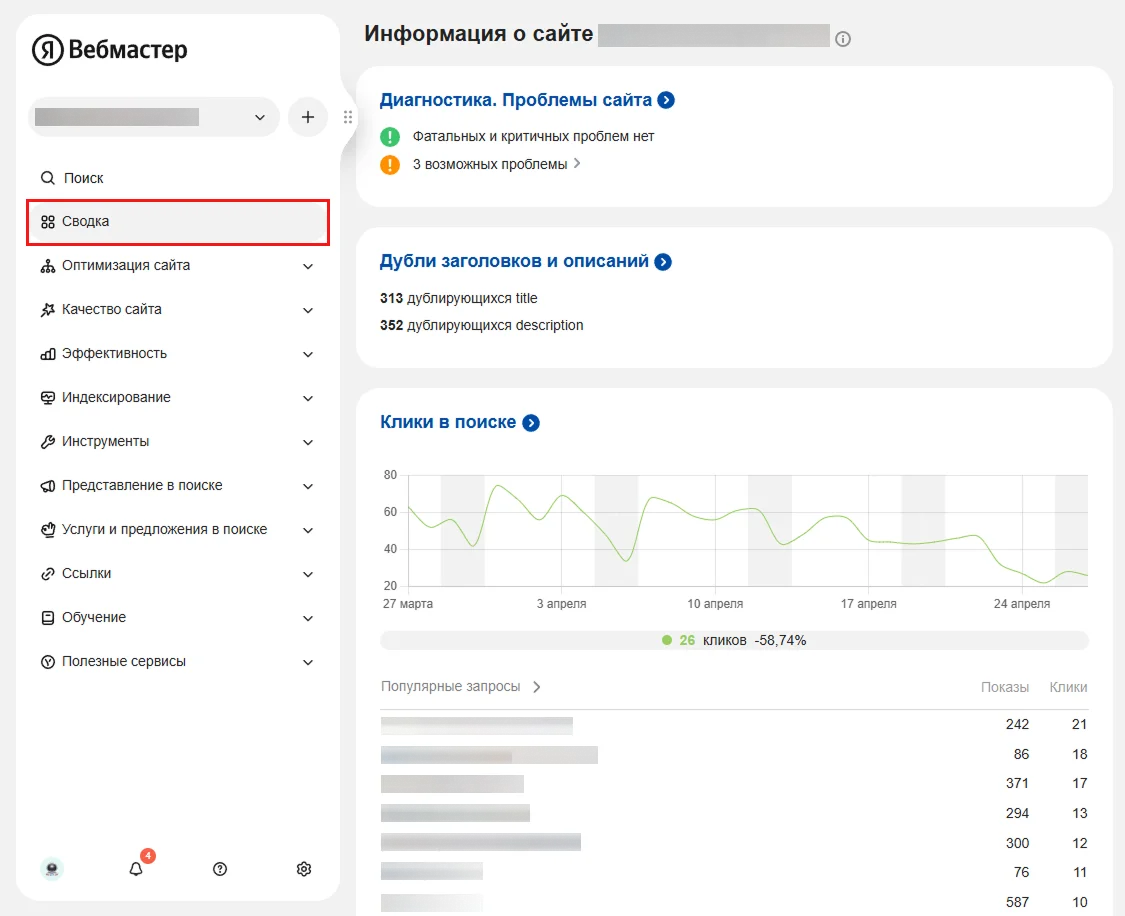
Таким образом, проиндексированные веб-страницы — это важнейший элемент любого поисковика, будь то Google, Microsoft Bing или Яндекс. Без подобной картотеки оперативно находить нужную информацию попросту невозможно.
WebCrawler — стандарт на десятилетие
Первым поисковиком, который стал использовать индексацию в более или менее современном виде, стал WebCrawler, запущенный в 1994 году. Его робот-«паучок» собирал информацию со всей сети, индексировал её и вносил в собственную базу данных. Разработка имела огромный успех и, в сущности, задала стандарт на десятилетие вперёд. Даже сейчас принципы, которые заложил WebCrawler, продолжают работать в основе современных поисковых систем.
Морфология языка: как Яндекс покорил великий и могучий
Но просто собрать и проиндексировать информацию — это лишь половина дела. Главное — правильно понять, что именно ищет пользователь. И здесь особенно интересен опыт Яндекса в работе с морфологией русского языка.
Дело в том, что поисковой системе необходимо находить не просто точное совпадение слов, а понимать смысл запроса. Подумайте сами: слово «шляпка» может относиться к грибу, головному убору или гвоздю. Русский язык полон подобных многозначных слов, что делает задачу на порядок сложнее, чем в английском.
Именно поэтому так показателен пример Яндекса. Компания анализировала, как часто слова встречаются вместе в текстах, используя данные Национального корпуса русского языка. Если пользователь ищет, например, «воронежский», система может автоматически добавить к поиску слово «Воронеж».
Яндекс также научился различать языки, чтобы не путаться при обработке запросов. Система определяла язык запроса по алфавиту, характерным сочетаниям букв и даже по региону пользователя. И, разумеется, люди постоянно допускают опечатки — примерно 12% поисковых запросов содержат ошибки. Поэтому поисковик автоматически проверял запрос на грамотность и предлагал исправленную версию.
Вот так, в зависимости от особенностей языка, поисковики справлялись с проблемами человеческих запросов.
Google и революция PageRank
Существовало и множество других поисковиков того времени — AltaVista, Excite и другие. Функционал у всех был примерно одинаковым, поэтому подробно останавливаться на каждом не имеет смысла. Важны первые и по-настоящему революционные.

Примерно в это же время, в 1998 году, два аспиранта из Стэнфордского университета — Сергей Брин и Ларри Пейдж — разработали поисковик Google. О нём, конечно, можно рассказывать долго. Но на самом деле важен не столько сам поисковик, сколько технология, которую для него разработали эти двое. Она называется PageRank.

Это была по-настоящему революционная вещь. Давайте разберёмся, в чём заключалась основная проблема поисковиков того времени. Да, благодаря индексации они могли находить ресурсы с нужной информацией, но вот качество найденных сайтов оставалось под большим вопросом. Грубый пример: если бы вы дали поисковику того времени запрос «как поменять лампочку», на первом месте мог бы оказаться не форум электриков, а сайт анекдотов. То есть релевантность поиска была практически на нуле.
PageRank же делал простую, но гениальную вещь. Алгоритм присваивал каждой странице показатель важности. Чем больше ресурсов в интернете ссылалось на определённую веб-страницу, тем более важной она становилась. Соответственно, при запросе пользователя на первые позиции выходила ссылка на тот ресурс, который зарекомендовал себя в интернете. Просто и изящно.
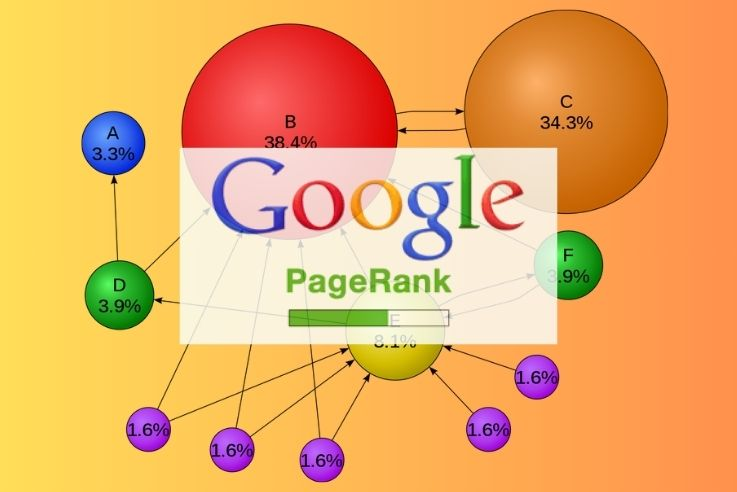
Внедрение PageRank совершило настоящую революцию в зарождающейся отрасли поисковых систем. Буквально за считанные месяцы все конкуренты создали аналогичные системы ранжирования. Со временем аналоги PageRank эволюционировали в нечто гораздо более сложное, где учитывалось множество факторов — вплоть до местоположения пользователя. Но об этом чуть позже.
MatrixNet от Яндекса: машинное обучение раньше всех
Кстати, поиск от Яндекса и сама компания в целом были важными первопроходцами в индустрии. Разработчики Яндекса буквально первыми стали использовать машинное обучение в поиске, когда Google ещё даже не задумывался об этом.

В 2009 году Яндекс сделал важный шаг в развитии поисковых технологий, начав использовать машинное обучение (ML — Machine Learning) значительно раньше Google. Компания разработала собственную технологию под названием MatrixNet, которая совершила настоящий прорыв в области поисковых систем.
К тому моменту интернет уже был огромным, и по некоторым запросам находились миллионы страниц. Просто показать все сайты, содержащие слова из запроса, было уже недостаточно — ведь пользователю пришлось бы целую вечность листать страницы с результатами. Требовалось научиться определять, какие страницы действительно отвечают на вопрос пользователя.
Для этого поисковик анализировал множество факторов: как часто встречаются слова из запроса, сколько на сайт ведёт ссылок, насколько он популярен у пользователей, и так далее. Всего таких факторов были тысячи, и первоначально они отслеживались вручную. Специалисты-эксперты — так называемые асессоры — помогали системе учиться, оценивая качество результатов поиска. Они оценивали конкретные страницы по конкретным запросам, и затем на этих оценках обучалась формула, которая ранжировала сайты по любому запросу.

Главная особенность MatrixNet заключалась в том, что он мог автоматически работать с огромным количеством таких факторов и при этом не переобучаться. То есть формула ранжирования сайтов стала подбираться на основании всех известных факторов и знаний о том, какие страницы лучше соответствуют запросу, а какие — хуже. Обычные алгоритмы в подобной ситуации начинали находить несуществующие закономерности, а MatrixNet оставался точным.
Более того, сама система могла настраивать поиск для разного типа запросов. Например, можно было улучшить поиск по музыке, не испортив при этом поиск по другим темам. А ещё MatrixNet был невероятно быстрым: он успевал проверить все факторы за доли секунды. Всё это работало на тысячах серверов одновременно — каждый искал по своей части интернета, находил лучшие результаты, а потом они объединялись в единый список, и пользователь практически мгновенно получал именно те сайты, которые ему были нужны.

Эта технология стала важнейшим шагом в развитии поиска. Она позволила учитывать намного больше факторов, чем раньше, и при этом делать это точно. С появлением MatrixNet поиск стал значительно умнее — он начал гораздо лучше понимать, чего хочет пользователь.
Самое забавное: технология настолько опередила своё время, что инженерам Яндекса пришлось сооружать инсталляцию из водяных труб, чтобы наглядно объяснить журналистам, что такое машинное обучение.
Три кита поиска прошлого
Подведём итог «поиска вчера» и назовём три главных кита, на которых он держится:
- Индексирование веб-страниц — создание своеобразной картотеки всего интернета.
- Настройка релевантности поиска — по типу PageRank от Google.
- Машинное обучение — впервые полноценно применённое Яндексом в 2009 году.
Поиск сегодня: от тысяч факторов до нейросетей
Нынешние поисковые системы эволюционировали в совершенно невероятные сервисы, которыми мы пользуемся каждый день. Когда компании осознали, что на продаже рекламы на самых посещаемых ресурсах интернета можно прекрасно зарабатывать, организации, которые изначально просто занимались поиском веб-страниц, превратились в настоящих технологических гигантов. Достаточно посмотреть на Google или Яндекс и оценить, в скольких сферах они присутствуют сегодня.
С расширением интернета стало очевидно, что искать нужно не только сайты, но и отдельные видеоролики, изображения, рестораны, природные локации и многое другое. Работы меньше не стало — интернет за последние десятилетия вырос многократно.
Предугадывание запросов
Например, чтобы ускорить поиск информации, появилась функция угадывания запроса пользователя. Специальный алгоритм запоминал, к какому слову привязана самая частая продолжающая связка — с учётом местоположения пользователя, самых частых запросов и множества других факторов. Если человек начинает вводить запрос «кто такой», поисковик мгновенно предлагает несколько вариантов продолжения. Попробуйте проверить это сами — результаты могут удивить.
От единиц к тысячам факторов
По сути, все технологии из «поиска вчера» перекочевали в «поиск сегодня», но на совершенно иных мощностях. Если раньше использовались лишь несколько метрик (вспомните PageRank от Google), то сегодня поисковики оперируют тысячами факторов ранжирования. Давным-давно для присвоения статуса полезности нужна была всего одна метрика — цитируемость ссылки. Теперь же алгоритмы анализируют колоссальное число параметров. MatrixNet от Яндекса, о котором мы уже рассказали, в своё время был именно таким исключением — он опережал эпоху.
Администрировать эти тысячи факторов вручную, естественно, невозможно. И тут на помощь приходит машинное обучение.
RankBrain от Google: поиск вещей, а не строк
Нейросети прочно вошли в нашу жизнь. С их помощью мы генерируем изображения, создаём видео, пишем тексты. И революция, которая происходит вокруг нас сейчас, стала возможной в том числе благодаря поиску в интернете. Ведь прародителями современных нейросетей с начала 2010-х годов стало именно машинное обучение.
Google тоже не стоял на месте. В 2015 году компания представила технологию RankBrain, и поисковик научился искать вещи, а не строки.
Чтобы обучить алгоритмы, инженеры Google сначала «скармливали» ему данные из различных источников, чтобы он начал их сопоставлять и упорядочивать выдачу на основе этих вычислений. Затем RankBrain наблюдал, как пользователи взаимодействуют с результатами поиска, созданными при помощи машинного обучения. Если пользователи оставались довольны результатами, алгоритм продолжал работать в том же направлении. Если результат не устраивал — машина начинала процесс заново.
RankBrain также оценивал релевантность контента на странице. Речь шла не только о сопоставлении ключевых слов, но и о глубоком понимании контекста. Он мог различать фрагменты, которые затрагивают разные аспекты и подтемы, связанные с основной темой запроса.
В целом, RankBrain выполнял две основные задачи. Во-первых, учился понимать поисковые запросы — их смысл и ключевые слова на веб-страницах. Во-вторых, измерял удовлетворённость пользователя результатами и подстраивался соответственно.
Нейросети-трансформеры: поиск по смыслу
Внедрение машинного обучения многократно улучшило опыт поиска. Он стал значительно персонализированнее и намного умнее. Именно благодаря нейросетям нового типа — так называемым нейросетям-трансформерам — и Google, и Яндекс научились понимать смысл запроса, а не просто искать совпадения слов.
Например, сегодня можно написать в поисковой строке «фильм, где мужчина выращивает картошку на Марсе», и вы получите множество релевантных ссылок с правильным ответом — фильм «Марсианин». Всё это происходит потому, что поисковик понимает смысл запроса, а не просто ищет ключевые слова на страницах.
Поиск завтра: эра искусственного интеллекта
Однако всё вышесказанное — лишь часть картины. Речь не только о машинном обучении. За последние несколько лет произошла настоящая революция — появились чатботы на основе больших языковых моделей.
На самом деле поиск будущего уже среди нас, и его можно смело назвать поиском настоящего. Это третий этап в развитии интернета и в поведении пользователей. Теперь в интернете есть все и всё: бизнес, инвестиции, сильные команды и продукты. Сейчас недостаточно просто находить актуальную информацию быстро. Теперь важно быстро находить самое лучшее из всего существующего контента.

У чатбота можно узнать практически что угодно, причём максимально персонализированно. В последний год компании массово внедряют чатботов в свои поисковые системы.
Экзистенциальный кризис поисковиков
Любопытно, что когда чатботы только начали появляться, поисковые компании пережили своего рода экзистенциальный кризис. Google вообще ввёл «красный код» внутри компании и стал считать ChatGPT своей главной угрозой. Однако спустя время стала очевидна одна крайне важная вещь: чатботы ошибаются. Причём не просто ошибаются, а порой галлюцинируют — выдумывают факты, которых не существует в реальности.

Простыми словами, чатбот, который должен был стать абсолютным поиском, оказался неспособен в одиночку справиться с этой задачей. Однако решение проблемы нашлось: объединить чатбота и поисковую систему.
Симбиоз: чатбот + поисковая система
Выгода от подобного симбиоза получается превосходная. Чатбот естественным языком отвечает на поставленный вопрос, превосходя все алгоритмы прошлого в десятки раз. С ним можно просто разговаривать как с человеком, и нет необходимости переходить по множеству ссылок, потому что вся информация суммируется сразу в один готовый ответ. А технологии поиска, в свою очередь, помогают чатботу находить достоверную и актуальную информацию, подкрепляя ответ релевантными ссылками на источники.
Copilot от Microsoft
Одним из первых представителей такого подхода стал Copilot от Microsoft. Компания инвестировала миллиарды долларов в OpenAI и встроила в свой поисковик Bing на тот момент самый мощный чатбот в истории — GPT-4 Turbo. То есть технология поиска работала совместно с чатботом, чтобы выдать максимально персонализированный результат.

Google AI Overviews и Gemini
Google же решила подойти к проблеме более фундаментально. В мае 2024 года компания представила собственную модель Gemini, специально адаптированную для поиска. Система получила название AI Overviews и работает через так называемые «ИИ-обзоры».

Когда пользователь задаёт вопрос, Gemini не просто ищет информацию, но анализирует её, структурирует и представляет в удобном формате. При этом система всегда указывает источники информации, позволяя пользователю проверить данные.
Одна из самых интересных возможностей — анализ видео для поиска решения технических проблем. Например, если у вас сломался проигрыватель виниловых пластинок, достаточно снять короткое видео проблемы, и система поможет найти решение.
Google также анонсировала системы, которые не только помогают с поиском, но и выполняют действия за пользователя. Например, можно написать: «Купи билет из Москвы в Стамбул», и нейросеть самостоятельно оформит покупку.
SearchGPT от OpenAI
Не остаётся в стороне и сама компания OpenAI. В конце 2024 года она представила собственный поисковик SearchGPT (впоследствии интегрированный в ChatGPT как функция поиска). Он объединяет возможности языковой модели GPT-4o с прямым доступом к актуальной информации из интернета.
SearchGPT работает принципиально иначе, нежели привычные поисковики. Когда вы задаёте вопрос, система не просто выдаёт список ссылок, а сразу формирует подробный ответ, основанный на данных из различных источников. При этом каждый факт в ответе сопровождается ссылкой на первоисточник — будь то новостная статья, научная публикация или специализированный блог.
В SearchGPT также появились специальные визуальные форматы для определённых типов запросов. Например, при поиске погоды пользователь видит детальный прогноз с графиками. При запросе котировок — биржевые данные в реальном времени. Для спортивных событий — актуальное расписание матчей и результаты.
Однако подобные решения, разумеется, есть и у других игроков рынка. И в этом отношении OpenAI пока остаётся в роли догоняющего. Главное преимущество SearchGPT — это возможность вести полноценный диалог: можно задавать уточняющие вопросы, и система будет учитывать контекст всего разговора.
Яндекс и поиск с Нейро
Отечественные разработчики тоже не отстают. В октябре 2024 года Яндекс представил масштабное обновление своего поисковика, интегрировав в него технологию Нейро. Поиск с Нейро работает по той же модели: он сразу даёт ответ на вопрос, ссылаясь на источники в интернете. Система автоматически определяет, когда её помощь будет действительно полезна, и появляется в результатах поиска самостоятельно. Если же нейросетевой ответ не был показан автоматически, достаточно нажать на специальную кнопку под поисковой строкой.

Поиск с Нейро умеет работать со сложными составными вопросами, и с ним можно вести полноценный диалог, поскольку он понимает контекст. Например, вы можете спросить: «Какая сегодня ключевая ставка?» А потом просто уточнить: «А когда изменится?» И поиск ответит датой следующего заседания Центрального банка. Раньше для этого пришлось бы делать два полноценных независимых поисковых запроса.
Кроме того, система научилась работать и с изображениями. В поиске по картинкам или через умную камеру можно задавать вопросы о конкретных деталях на фотографии. Сфотографировали автомобиль — и просто спросили, сколько он стоит. Не нужно знать марку и модель: вы сразу получаете готовый ответ. А если на фотографии рядом с основным объектом присутствует другой предмет — например, велосипед — поиск поймёт контекст и всё равно ответит именно про автомобиль.

Более того, можно сфотографировать задачу по математике для девятого класса, и поиск самостоятельно её решит — даже если такой задачи нет в интернете. (Простите за это опасное знание.)
Поиск завтрашнего дня: AGI и абсолютная персонализация
Всё описанное выше — это поиск сегодня, и мы уже живём с ним бок о бок. Но что ждёт нас в будущем?
По прогнозам экспертов, в ближайшее время поиск сможет давать ответы на основе не только текстовой, но вообще любой информации в интернете — например, на основе содержимого конкретного видеоролика.

Однако использование нейросетей в связке с поиском — это, по всей видимости, промежуточный вариант. Настоящий поиск будущего должен быть связан с AGI — Artificial General Intelligence, то есть так называемым «настоящим» искусственным интеллектом. Не просто алгоритмом, который пытается угадать, что хочет пользователь, а полноценным цифровым разумом, способным мыслить и понимать.
Только представьте, насколько поиск станет совершеннее, когда у вас появится собственный ассистент, который знает вас лучше, чем кто-либо другой, и способен буквально по первым нескольким буквам угадать, что вам нужно. А с учётом того, как стремительно всё развивается в 2025 году, подобный поиск мы, возможно, увидим достаточно скоро.

Судите сами: нынешние технологии уже умеют искать по тексту и изображениям, вести с пользователем полноценный диалог, а персонализированный ИИ-ассистент сможет делать всё это индивидуально для каждого.
Персонализация — вот главная черта поиска будущего, если всё пойдёт так, как предрекают лидеры индустрии.
Заключение
История интернет-поиска — это история человеческого стремления к знаниям. От бумажных каталогов и примитивного Archie в 1990 году — через революцию PageRank и MatrixNet — к нейросетевым ассистентам, которые разговаривают с нами на естественном языке. Каждый этап этой эволюции делал доступ к информации проще, быстрее и точнее.

Сегодня мы стоим на пороге новой эпохи, в которой границы между поисковой системой и интеллектуальным собеседником окончательно стираются. И если прошлое научило нас чему-то, то это тому, что следующий скачок может произойти быстрее, чем кто-либо из нас ожидает
