А вы знали, что QR-коды бывают цветные, круглые или одноглазые? А еще в сам код может поместиться целый видеоролик? Не по ссылке, а в сами вот эти квадратики.
Привычный QR-код — это три квадратика и много чернобелых точечек. Его можно увидеть в статье Wikipedia про QR-коды, и отсылает он, как ни странно, к стартовой странице мобильной Wikipedia.
https://youtu.be/JsoPq5EJGY8
Мы постоянно встречаем QR-коды вокруг. Последние годы еще чаще. А сейчас нам предстоит познакомиться с QR-кодами и в платежах. Но задумывались ли вы, как они устроены? Зачем нужны все эти квадраты, что они означают и что кодируют? Можно ли при помощи него закодировать песню или ролик? И как он еще используется, кроме рекламы ВКонтакте? А еще узнаем, как японские инженеры переизобрели золотое сечение!
История
Начнем с первых чернобелых кодов.
Япония 1950-х годов. Причем тут она?
Первой черно-белой картинкой для быстрого сканирования и хранения информации был шрихкод. Они появились еще в середине XX века.
В 1950-х годах в США стали появляться первые штрих-коды. Произошло это как раз на заре “японского экономического чуда”. Помните, как в нулевых полки магазинов наводнило всё дешевое и китайское? Нечто похожее было в 1950-х, только с Японией. Но огромный поток товаров, расширение магазинов сделали труд сотрудников буквально невыносимым.
Вчера продавец занимался одной только рыбой, а уже сегодня рулит супермаркетом. От постоянного клацанья по цифрам кассового аппарата у продавцов массово равивался синдром запястного канала. Это постоянная боль в запястье из-за защемления нерва. Им срочно требовалось решение проблемы ручного введения маркировок и цен товаров, и штрих-код тут пришелся весьма кстати, потому что позволял узнать информацию о товаре в один клик.

Штрихкоды все видели много раз, а многие и сканировали на кассах самообслуживания в Пятерочке и других супермаркетах. Но давайте разберемся, как они устроены. По принципу работы создатель штрихкода Джозеф Вудланд сравнивал его с азбукой Морзе. Толстые черные линии — тире, тонкие — точки, белые линии — паузы. При помощи их чередования можно закодировать различные символы. Если переводить все это двоичную систему счисления (нули и единицы, то, как кодируют любую инфу программисты), то черные полосы — это единицы, а белые — нули. Черная полоса минимальной толщины — это единица, белая — ноль. Если сделать любую из них в два раза толще, то это будут две единицы (в случае черной) или два нуля (в случае белой). И так далее. Толщина полос не меняет суть донесения информации, просто в толстой полосе поместится больше единиц или нулей, чем в тонкой, и толстые полосы позволяют закодировать поместить несколько единиц или нулей подряд (это видно на картинке).
Такая система называется одномерным штрихкодом, потому что в линиях важен только их горизонтальный порядок. Иными словами, сканировать линии можно в любом положении, можно сделать это и по диагонали — главное, чтобы все линии были отсканированы.

Одномерные штрихкоды эффективны и просты, но не лишены недостатков. Главный из них — небольшой объем информации, которую можно закодировать, — он ограничивается приблизительно 20 символами (если речь идёт о цифрах, поскольку штрихкод в основном именно их и кодирует — он должен содержать цену и/или код маркировки. Если мы захотим включить в него еще и буквы, максимальный объем символов значительно сократится).
Для большей части стандартов можно закодировать и больше, ограничение тут скорее не на программном, а на хардверном уровне. Чем больше штрихкод, тем больше в нем должно быть полос, значит, тем длиннее он будет. А чем длиннее код, тем сложнее его считать сканером. Это и есть основная проблема одномерных кодов — они линейны, и чтобы заложить в них больше информации, нужно сделать линию длиннее, а мы не можем делать это бесконечно.
К середине 1990-х годов стало очевидно, что для многих процессов штрихкоды недостаточно ёмкие. Надо было что-то делать. И тут мы оказываемся…
В Японии 1990-х годов.
Например, сотрудники Toyota жаловались, что у них слишком много наименований деталей с разной маркировкой: какие-то из них содержали цифры и буквы, а какие-то — японские иероглифы кандзи и кана.
Проект по разработке нового стандарта штрихкода запустила дочерняя компания Toyota — DENSO WAVE INCORPORATED, а конкретнее — сотрудник отдела разработки Мисихиро Хара. В его задачи входило не только создать более объемный код, способный вместить больше информации. Помимо этого код должен был считываться максимально быстро, из любой ориентации в пространстве и быть устойчивым к повреждениям, которые часто случаются с маркировками на производствах.
Идея использовать комбинацию из белых и черных точек пришла к Мисихиро, когда он наблюдал за традиционной японской игрой го.

Разрабатываемая система должны была стать, в отличие от штрих-кода, двумерной, то есть кодирующей информацию не линейно, а на плоскости, в двух направлениях.
С командой из двух человек Мисихиро Хара провел исследование и пришел к двум важным выводам.
Во-первых, квадрат — это форма, которую легче всего распознают считывающие устройства. Также квадраты реже всего встречались на официальных документах, что уменьшало вероятность ошибки. Логика здесь достаточно простая — если рядом с кодом находится похожее на него изображение, сканер может принять за код именно его.
Но более интересная задача заключалась в другом — придумать такой внешний вид кода, чтобы автомат мог легко обнаружить его среди других изображений. Мисихиро с сотрудниками проанализировали бесчисленное количество печатной продукции: от газет и проездных билетов до пакетов молока, чтобы понять, какое соотношение белого и черного цветов встречается реже всего. Все с той же целью — сделать их код как можно более уникальным по форме. Вышло, что такое соотношение 1:1:3:1:1. Расположение белых и черных форм в таком соотношении позволяло сканировать код из любого положения, стоя хоть слева, хоть справа, хоть сидя на кортанах или со стремянки, потому что сканер всегда распознавал правильное соотношение цветов.
Почему именно 1:1:3:1:1? Чтобы рассказать об этом, надо углубиться в то, как устроен QR-код. Потому что японцы похоже переизобрели «золотое сечение»!
Прежде всего, в QR-коде достаточно много служебной информации. Далеко не все квадраты кодируют ту функциональную инфу, которую мы в него поместили. Каждый QR-код разбивается на зоны, чтобы сканирование прошло правильно. Смотрите.
1. Чтобы определить, что перед сканером находится именно QR-код, ему нужно за что-то зацепиться. Для этого существуют маркеры позиционирования — три больших одинаковых квадрата по краям каждого кода. Если посмотреть на каждый такой квадрат, то он содержит 3 квадрата: черный большой по краю, черный маленький посередине и белый между ними. Эти квадраты позволяют поделить маркер позиционирования на 5 блоков (по сути вертикальных линий). Две из них по краям черные, две, такой же толщины, содержат белые и черные элементы и самый широкий, по центру, тоже состоит как из белого, так и черного цветов. Соотношение площадей этих блоков и составляет 1:1:3:1:1. Такое уникальное соотношение позволяет быстро определить наличие QR-кода на изображении и его ориентацию, вне зависимости от того, как код повернут относительно сканера.
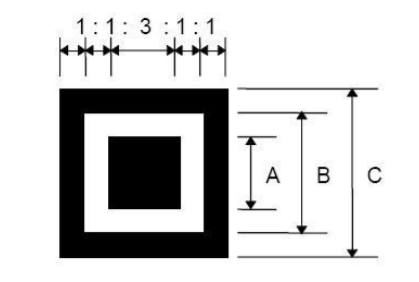
(A,B,C — это 3 квадрата, из которых состоит маркер позиционирования. Блоки, связанные соотношением 1:1:3:1:1, показаны сверху)
(картинки показывают, что вне зависимости от ориентации код будет считан)

2. При помощи этих трех маркеров код может быть определен в идеальных условиях — например, когда вы считываете его с экрана. Но очень часто QR-коды можно увидеть на смятых афишах, ЖД-билетах и даже на стенах домов. Как быть в этом случае? Для этого нужен маркер выравнивания. Можно сказать, он действует как ориентир, позволяющий легче структурировать информацию. Своего рода маяк для сканера. И чем больше информации хранит код, тем больше шаблонов выравнивания он требует и тем большего размера они должны быть. Это тоже достаточно логично: чем сложнее рельеф побережья и чем туманнее погода, тем более мощным должен быть маяк для корабля.

3. Также неподалеку от маркеров позиционирования находятся полосы синхронизации: по чередованию черных/белых точек внутри этих линий сканер определяет размер данных (квадратиков), хранящихся в QR-коде.

4. Маркер версии определяет, к какой из более чем 40 версий принадлежит QR-код. Каждая версия имеет особенности в конфигурации и количестве точек (модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177.С увеличением версии меняется только количество информации, которое можно закодировать в QR-коде. Смартфоны обычно способны считывать версии с первой по четвертую, дальше точки становятся для них слишком мелкими.

5. Далее идет информация о формате. В этих ячейках продублирована некоторая системная информация, что увеличивает устойчивость кода к повреждениями, также тут содержится информция о том, солько информации конкретно этот код может потерять, пока она не станет критической для считывания.

6. От окружающих объектов код отделяет тихая зона. Белые рамки вокруг кода позволяют сканеру отличить код от всего, что его окружает. Чтобы сканер случайно не добавил в QR-код муху, сидящую на листке бумаги.

И это только служебные блоки.
ВЫ НАХОДИТЕСЬ ЗДЕСЬ
Наконец, что же с самой информацией, хранящейся в коде? Она может занимать разную площадь, в зависимости от версии QR-кода, уровня коррекции и количества информации, которую мы хотим закодировать.
Но самое любопытное. Оказывается, что в зоне с информацией квадратов всегда больше, чем нужно, чтобы закодировать наши конкретные данные. Зачем это нужно? Чтобы QR-код был все еще читаем даже при повреждении. Это и называется уровнем коррекции. Их бывает 4: L, M, Q и H. Для самого маленького уровня L допустимо всего 7% повреждений, зато в него можно поместить больше данных. Для самого большого H даже потеря 30% информации не скажется на считывании, но из-за этого придется пожертвовать размером кодируемой информации.
Так, в QR код третьей версии с уровнем коррекции L можно поместить до 53 байт данных, а в аналогичный с уровнем коррекции H — максимум 24. Также эта градация может быть важна при оформлении QR-кода. Вы же видели все эти брендовые коды с рисуночками?


Для того, чтобы создать такие, нужно иметь максимальное пространство для кодирования информаци, потому что часть полезной площади занимает рисунок. Поэтому для таких кодов стоит выбрать минимальный уровень коррекции.
Как же кодируется информация в этих маленьких квадратиках?
QR-код поддерживает несколько способов кодирования данных, в зависимости от того, какие символы используются: цифровое, буквенно-цифровое и кандзи (японские иероглифы). Эти способы различаются преимущественно количеством информации, которая требуется на кодирование определенного количества символов. Так, при кодировании цифр нам понадобится 10 бит на 3 символа, а для кодирования букв и символов — 11 бит на 2 символа.
Смотрите, как это устроено?
Чтобы закодировать фразу, нам нужно разделить каждое слово на группы по 2 буквы, затем присвоить им номера и перекодировать в 11-битный двоичный код (то есть таким образом, чтобы каждые 2 буквы состояли из последовательности из 11 нулей и ед иниц. Если в слове нечетное количество букв, то последняя буква будет закодирована 6-битным кодом, то есть будет состоять из 6 нулей и единиц). Например, возьмем слово HELLO. После разбивания на слоги это будет HE LL O. В 11-битном двоичном коде это будет выглядеть как 01100001011 01111000110 011000. А если написать все вместе, то 0110000101101111000110011000.
Далее, после выбора уровня коррекции и версии и после добавления всех служебных полей, о которых мы говорили ранее, ( нам следует перевести информацию, которая у нас содержится в битах, в байты, для этого нужно сделать число цифр в коде кратным восьми. Для этого нужно прибавить к последовательности нужное количество нулей. ) В нашей последовательности HELLO 28 цифр. Добавляем 4 нуля и готово. В итоге у нас получается количество байт, которое нужно распределить по количеству блоков, что делает компьютер с учетом всех служебных блоков. Например, QR-код первой версии минимального уровня коррекции, кодирующий HELLO, будет выглядеть вот так.


Теперь стоит поговорить о том, что же могут кодировать QR-коды? Какие типы файлов них помещаются? На самом деле, в QR можно поместить практически любой файл, здесь все ограничивается объемом кода и целесообразностью помещения.
В QR-код наибольшей ёмкости, то есть код версии 40 с минимальным уровнем корректировки, можно поместить максимально 2953 байта или 2,9 мегабайт. В него можно было бы вместить песню или очень короткое видео, но нужно понимать, что далеко не каждый девайс сможет “прочесть” такой оъемный код, да и какой в этом смысл, если можно поместить в код ссылку на те же песню или видео? На серверах места в любом случае больше. Поэтому с развитием интернета наиболее частым содержанием QR-кодов стали визитки, идентификаторы WI/FI сетей, данные почты или номера мобильных телефонов и обычные URL ссылки.
Разные типы QR
Но единственный ли формат тот квадратный QR-код, к которому мы привыкли? За годы существования накопилось множество форм кодов, немного отличающихся по сферам применения.
Например, Ацтек-код, в котором маркер позиционирования находится по центру. Его используют некоторые ЖД и авиалинии в качестве электронных билетов.

Макси-код отличается от Ацтека тем, что маркер позиционирования округлый, а сама кодировка происходит при помощи структур, напоминающих пчелиные соты. Такой, например, использует почтовая служба США.

Microsoft Tag
А код с совершенно бесчеловечным названием PDF417 интересен тем, что был изобретен на три года раньше, чем известный всем нам QR. Однако, по сути, это своего рода переходная форма между штрих-кодом и QR, так как он хоть и модет кодировать больше информации, чем стандартный штрих-код, все же не является двухмерным, как QR, и может быть считан обычным линейным сканером, как на кассе в магазине. Он в настоящее время используется в билетах в РЖД.

В целом, разные форм-факторы отличаются преимущественно количественно: объемом закодированной информации и толерантностью к повреждениям.
Использование

Где же еще применяются QR-коды? Вряд ли кому-то из смотрящих это видео надо реально рассказывать о применении того, что есть на каждой остановке. Но если задуматься, легко и быстро считываемые визуальные коды создали очень много возможностей.
Стало намного легче рекламировать интернет-продукты, предпринимателям теперь не надо носить с собой кучу визиточной макулатуры, а в больнице можно оставить обратную связь о работе каждого врача. Не говоря уже о коронавирусных ограничениях.
В Китае вовсе не прижилась технология NFC, поскольку они используют QR-коды для оплаты покупок. Как это работает? Покупатель сканирует QR-код продукта, после чего банковское приложение формирует QR-код транзакции, который сканирует продавец, и приложение на его телефоне формирует уникальный QR-код подтверждения, который сканирует покупатель и после подтверждает покупку.
Это намного проще, чем NFC, потому что требует только наличия хорошего интернета у покупателя и продавца, что для Китая не является проблемой. Не нужно покупать кассовое оборудование с поддержкой NFC и возиться с его настройкой.
Сама по себе оплата QR-кодами звучит недостаточно футуристично? Ученые из Индонезии считают, что QR-код можно эффективно связать с меткой наподобие NFT для подтверждения подлинности документов на физическом носителе.
Конкретно, они предложили такую технологию для проверки подлинности вузовских дипломов. На диплом наносится QR-код, хранящий личное дело выпускника, верифицированное при помощи блокчейн-технологий. Такой метод можно уже сейчас применять для борьбы с фальсификацией дипломов о высшем образовании, но у него нет ограничений для применения и на других официальных документах.
В заключение для примера сайт QR code Monkey, который позволяет закодировать практически все, что душе угодно. Это может быть и геотег, и даже музыка с видео, если простые ссылки на них вас по какой-то причине не устраивают.
