Что если бы вычислительная мощность, которую ещё несколько лет назад можно было встретить разве что в специализированных исследовательских центрах, уместилась в корпус размером с увеличенный Mac mini и встала на ваш рабочий стол? Именно с таким вопросом NVIDIA вышла на сцену CES 2025 — и ответ оказался не риторическим.
При слове «суперкомпьютер» воображение рисует привычную картину: просторный машинный зал, стойки с оборудованием от пола до потолка, ряды вентиляторов, непрерывный гул. Такие системы строят для моделирования климата, разработки ядерного оружия, расчёта сложных физических процессов и — в последние годы всё чаще — для обучения и запуска крупных моделей искусственного интеллекта. Доступ к подобным мощностям традиционно означал либо работу в государственном исследовательском институте, либо аренду облачной инфраструктуры у технологических гигантов.\

В NVIDIA задались простым вопросом: а что если сделать это компактным? Project Digits — именно так устройство называлось на момент анонса — стал ответом на этот вопрос. Суперкомпьютер, который помещается в небольшой корпус и может стоять прямо на рабочем столе. Впрочем, к моменту выхода в продажу устройство сменило имя: с осени 2025 года оно называется NVIDIA DGX Spark.

Для кого это устройство — и для кого точно нет
Нужно сразу сказать прямо: для рядового пользователя DGX Spark бесполезен. Это не игровая машина, не мощная рабочая станция для монтажа видео и не замена привычному домашнему компьютеру. Устройство создавалось для вполне конкретной аудитории: разработчиков в сфере искусственного интеллекта, исследователей и студентов, которым нужно создавать, дообучать и запускать крупные языковые модели локально — без постоянного обращения к облачной инфраструктуре.
По замыслу NVIDIA, DGX Spark — это инструмент для прототипирования. Разработчик создаёт и тестирует модель на настольном устройстве, а когда она готова к промышленному применению, разворачивает её в облаке или в корпоративном дата-центре. Причём — и это принципиально — на той же самой программной архитектуре. Никакой переписки кода, никакой адаптации под другую платформу.

Кроме того, устройство открывает интересную возможность для тех, кто ценит конфиденциальность: на нём можно запустить собственную языковую модель, обучить её на персональных данных и работать с ней локально, не передавая ничего в интернет. Это значительно отличается от привычной схемы, при которой любой запрос к ChatGPT или аналогичному сервису обрабатывается на удалённых серверах.
Операционная система — не привычная Windows, а DGX OS: специализированный дистрибутив на базе Ubuntu 24.04, настроенный под задачи искусственного интеллекта. В комплекте идут CUDA, cuDNN, TensorRT, Docker и целый набор готовых сценариев применения — от RAG-систем до мультиагентных рабочих процессов. Всё это позволяет приступить к работе практически сразу после включения.
Что внутри: архитектура GB10 Grace Blackwell
Внешне DGX Spark выглядит как типичный мини-компьютер — золотистый металлический корпус размером 150 × 150 × 50,5 мм, стилистически напоминающий уменьшенную копию легендарного DGX-1. Именно такой суперкомпьютер Дженсен Хуанг лично доставил Илону Маску в офис OpenAI в 2016 году — системы, которую принято считать отправной точкой всего нынешнего бума генеративного ИИ. Намёк на эту историю в дизайне DGX Spark вряд ли случаен.

128 гигабайт оперативной памяти и накопитель NVMe объёмом до 4 ТБ — внушительно, но вполне ожидаемо для устройства подобного класса: обученные языковые модели занимают значительное место. Самое интересное — в главном чипе. Сердце DGX Spark — GB10 Grace Blackwell Superchip, система на кристалле (SoC), разработанная совместно с компанией MediaTek.

Прежде чем двигаться дальше, стоит пояснить саму концепцию SoC для тех, кто с ней не знаком. Традиционный компьютер состоит из множества отдельных компонентов, расположенных на разных платах и соединённых между собой: центральный процессор, графический процессор, оперативная память, контроллеры. В случае системы на кристалле все эти элементы интегрированы на одном чипе. Это позволяет существенно сократить занимаемое пространство и снизить задержки при передаче данных между компонентами.

GB10 объединяет графический процессор на архитектуре Blackwell — с новейшими ядрами CUDA и тензорными ядрами пятого поколения — и центральный процессор Grace с двадцатью энергоэффективными ядрами на базе архитектуры Arm (10 высокопроизводительных ядер Cortex-X925 и 10 энергоэффективных Cortex-A725). Соединяет их технология NVLink-C2C, обеспечивающая пропускную способность в пять раз выше, чем интерфейс PCIe Gen 5. Унифицированная архитектура памяти означает, что процессор и графический сопроцессор совместно используют единый пул из 128 ГБ — без накладных расходов на копирование данных между раздельными банками.
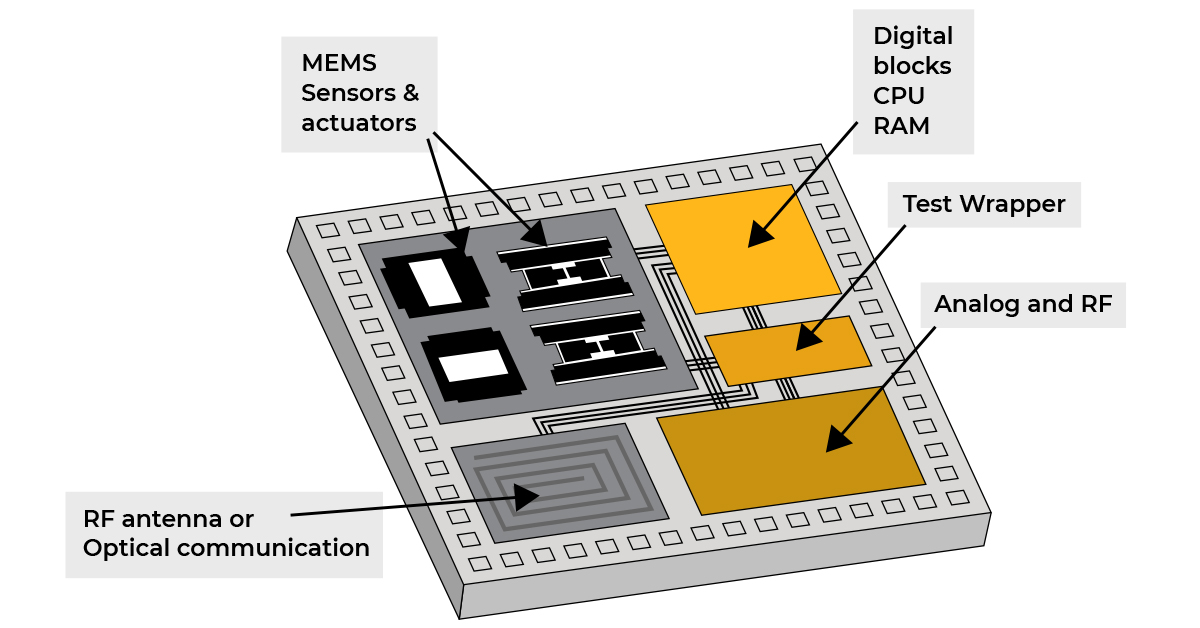
Благодаря этому DGX Spark способен локально запускать языковые модели с числом параметров до 200 миллиардов. Для сравнения: GPT-3 — модель, с которой во многом началась нынешняя эпоха генеративного ИИ — содержит 175 миллиардов параметров. Если же соединить два устройства через специальный адаптер ConnectX с пропускной способностью 200 Гбит/с, объединённая система справляется с моделями до 405 миллиардов параметров — размер флагманской Llama 3.1 от Meta.
Петафлопс петафлопсу рознь: о чём умалчивают в пресс-релизах
Заявленная производительность в 1 петафлопс — квадриллион операций в секунду — звучит впечатляюще. Для сравнения: Sony PlayStation 5 Pro выдаёт около 33 терафлопс, то есть примерно в тридцать раз меньше. Однако у этой цифры есть существенная оговорка, о которой важно говорить честно.
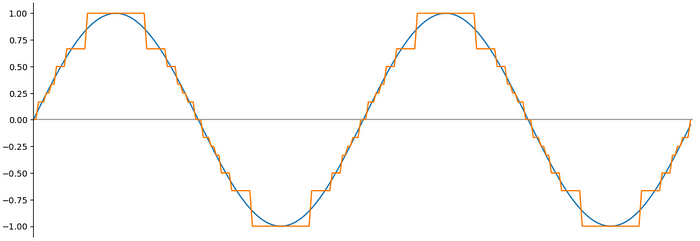
Заявленный петафлопс относится к вычислениям с точностью FP4 — то есть к операциям с четырёхбитными числами с плавающей точкой. Для сравнения: стандартные научные расчёты ведутся с точностью FP32 (32-битные числа), а большинство современных нейросетей при обучении используют как минимум FP16. FP4 — это очень низкая точность. При ней каждое число кодируется четырьмя битами вместо шестнадцати или тридцати двух, что позволяет резко ускорить вычисления, но ценой потери точности представления числовых значений.
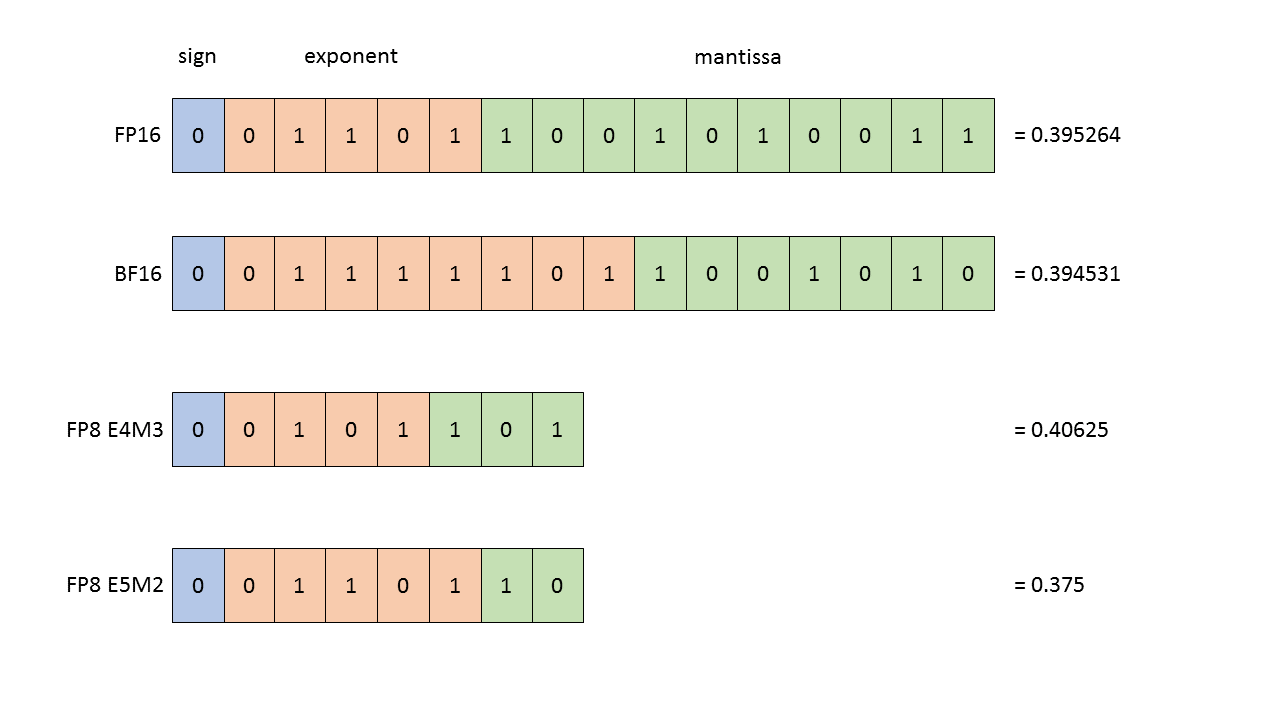
Кроме того, реальный показатель достигается с использованием технологии структурного прореживания (structured sparsity): она удваивает эффективную скорость вычислений, пропуская нулевые значения. Но работает это только при условии, что конкретная задача оптимизирована под этот режим — что в реальных приложениях выполняется далеко не всегда. Независимые тесты показывают реальную производительность на уровне около 100 терафлопс в формате BF16 и около 207 терафлопс в FP8 — цифры уважительные, но далёкие от рекламного петафлопса.
После выхода устройства в продажу эта тема вызвала оживлённую дискуссию в профессиональном сообществе. Критики указывали, что заявленная мощность — маркетинговая цифра, а не реальный показатель производительности для большинства задач. Один из обозревателей зафиксировал, что при работе с моделью Llama-3.1-8B устройство выдаёт около 36 токенов в секунду — ровно столько же, сколько Mac mini с процессором M4 Pro, который стоит примерно в три раза дешевле.

И всё же было бы несправедливо сводить дискуссию к простому «обману покупателей». NVIDIA действительно провела масштабную исследовательскую работу, чтобы сохранить практически приемлемую точность при переходе на FP4. На конференции HotChips в августе 2024 года компания продемонстрировала первый генератор изображений, работающий на модели с точностью FP4: результат визуально практически неотличим от FP16. Это говорит о том, что для задач инференса в нейронных сетях четырёхбитное представление чисел вполне имеет право на существование — особенно в сочетании с грамотными методами квантизации.
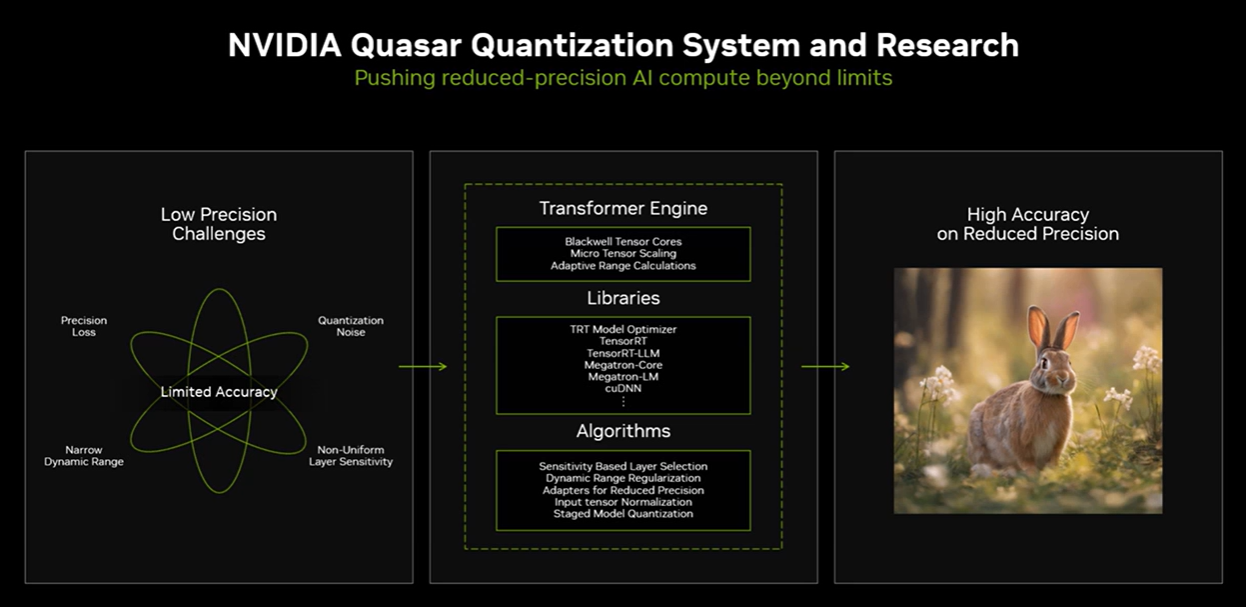
Немаловажно и то, что DGX Spark обладает уникальным преимуществом, которое не отражается ни в каких бенчмарках: нативная поддержка CUDA. Конкурирующие решения на базе AMD Ryzen AI Max или чипов Apple Silicon предлагают сопоставимую или даже превосходящую производительность по соотношению цена/качество — но все они лишены доступа к экосистеме CUDA, которая по-прежнему остаётся де-факто стандартом в разработке ИИ.
От анонса к реальности: как Project Digits стал DGX Spark
Путь от анонса до прилавка оказался долгим. На CES 2025 устройство обещали выпустить в мае того же года по цене 3 000 долларов. В марте 2025 года NVIDIA переименовала Project Digits в DGX Spark. Первые поставки начались лишь осенью 2025 года — и уже по цене 3 999 долларов за версию Founders Edition. К февралю 2026 года цена выросла ещё раз — до 4 699 долларов, что NVIDIA объяснила дефицитом 128-гигабайтных модулей памяти LPDDR5x.

Параллельно к выпуску устройств подключились партнёры: Acer, ASUS, Dell, Gigabyte, HP, Lenovo и MSI выпустили собственные версии на базе того же чипа GB10 — как правило, с меньшим объёмом накопителя и по более низкой цене. Рынок обозначил своё отношение к категории довольно отчётливо: сопоставимые по возможностям системы на Ryzen AI Max+ стоят существенно дешевле, хотя и проигрывают в поддержке программного стека NVIDIA.
Реальные пользователи и независимые обозреватели дали устройству в целом осторожно положительную оценку. Отмечается исключительное удобство работы с готовым программным стеком — DGX OS поставляется с предустановленными инструментами, и первую рабочую нейросетевую задачу можно запустить буквально через несколько минут после распаковки. 128 ГБ единой памяти, разделяемой между процессором и графическим ускорителем, действительно позволяют запускать модели, недоступные на большинстве потребительских устройств. Встроенный сетевой интерфейс ConnectX-7 с пропускной способностью 200 Гбит/с — компонент, который в отдельной поставке стоит от 1 700 долларов — также выгодно отличает DGX Spark от конкурентов.
Вместе с тем критики указывают на тепловые ограничения: компактный металлический корпус объёмом 1,13 литра при длительных нагрузках заметно греется, и часть пользователей фиксировала самопроизвольные перезагрузки. Устройство потребляет значительно меньше заявленного TDP, что свидетельствует о термическом или программном ограничении производительности. Ситуацию должны исправить обновления прошивки — одно из них уже снизило потребление в режиме ожидания более чем на треть.
Намёк на будущее: NVIDIA на рынке потребительских процессоров?
На пресс-конференции в январе 2025 года Дженсен Хуанг обронил фразу о том, что у компании есть «собственные планы» относительно дальнейшего использования разработанного процессора. На фоне устойчивых слухов о том, что NVIDIA активно работает над собственным потребительским центральным процессором, это заявление прозвучало не как дежурная ремарка, а как намеренный сигнал рынку.
Если компания действительно выйдет на рынок потребительских процессоров — рынок, который десятилетиями делят Intel и AMD, — последствия для индустрии сложно переоценить. GB10 уже доказал, что архитектура Arm в связке с графическим ускорителем Blackwell и унифицированной памятью работает. Остаётся вопрос: захочет ли NVIDIA идти дальше? Пока что это лишь намёки. Но в истории технологий именно так всё и начинается.
Главное — не само устройство
DGX Spark — устройство для узкой аудитории. При нынешней цене в несколько тысяч долларов, работе исключительно под управлением Linux и ориентации на профессиональные задачи ИИ оно явно адресовано не широкому потребителю. Разработчики и исследователи получили то, о чём давно мечтали: возможность работать с крупными языковыми моделями локально, без облачной зависимости и без необходимости делиться данными с внешними серверами.

Но, пожалуй, главное в этой истории — не само устройство. Главное — прецедент. Впервые в истории суперкомпьютерные вычисления в сфере искусственного интеллекта оказались в форм-факторе настольного компьютера с ценой, соответствующей профессиональной рабочей станции. Это тот самый момент, когда технология, существовавшая исключительно в серверных залах, делает шаг навстречу обычному рабочему пространству. Пусть пока — только для профессионалов. Но закономерность здесь такая же, как и всегда: сначала появляется дорогой инструмент для специалистов, а затем — через несколько лет — доступная версия для всех остальных.
