Последние несколько лет с камерами в смартфонах происходит нечто странное. Устоявшиеся лидеры рынка — Apple, Google, Samsung — словно застряли на месте. Каждое новое поколение приносит косметические улучшения: чуть больше мегапикселей, чуть точнее автофокус, чуть лучше ночной режим. Но прорыва, сопоставимого с тем, что когда-то совершил портретный режим или ночная съёмка на Pixel, не было уже давно.
А вот китайские производители — Vivo, OPPO, Xiaomi, Huawei — за тот же период совершили колоссальный рывок. Они больше не догоняют западных и корейских конкурентов. Они задают тренды.
Возникает закономерный вопрос: что происходит? Почему китайские компании так резко вырвались вперёд? Что они делают принципиально иначе? И самое главное — действительно ли речь идёт о технологическом прогрессе, или же всё это не более чем ловкий трюк с нейросетями?

В этом материале мы подробно разберёмся в ситуации. Значительная часть анализа будет посвящена компании Vivo — не в порядке рекламы, а потому что именно на примере их технологий проще всего проследить, куда движется вся индустрия мобильной фотографии. Vivo открыто публикуют свои научные работы, их инженеры охотно отвечают на вопросы, а количество накопленного исследовательского материала позволяет провести по-настоящему глубокий разбор.
Мы объясним, как устроен «китайский» портретный режим и почему смартфоны внезапно научились безупречно обрабатывать каждый волосок на голове модели. Поговорим о главной болезни современных камерофонов — так называемой нейромазне: откуда она берётся и почему раздражает пользователей. А в конце попробуем ответить на вопрос, который многие задают уже вслух: стоит ли Apple, Google и Samsung начинать нервничать? Или, быть может, уже поздно.
Информация, собранная в этой статье, уникальна — часть данных получена напрямую от инженеров Vivo Camera Research и не публиковалась ранее в русскоязычных источниках.
Вычислительная оптика: как всё началось
2016 год. Apple совершают очередную «революцию». В iPhone 7 Plus появляется вторая камера на задней панели — телефото-модуль. По меркам того времени решение далеко не очевидное. Но именно с этого момента принято отсчитывать эпоху вычислительной оптики в мобильной фотографии.

Чтобы понять, почему это событие стало столь значимым, необходимо вспомнить базовые принципы. Фотографии, сделанные большими профессиональными камерами, привлекают нас по нескольким причинам: высокая детализация, точная цветопередача, широкий динамический диапазон. Но главное — характерное, приятное глазу размытие фона, известное как боке.
По первым трём параметрам — детализации, цветам и динамическому диапазону — мобильные камеры к тому моменту уже довольно близко подобрались к профессиональным. В этом помогли быстрые процессоры и всё более совершенные алгоритмы обработки. Однако боке — это явление чисто оптическое. Для того чтобы получить красивое, естественное размытие фона, необходим большой объектив и большой сенсор. Разместить всё это в тонком корпусе смартфона физически невозможно. Таковы законы оптики, и никакая инженерия не способна их обойти.
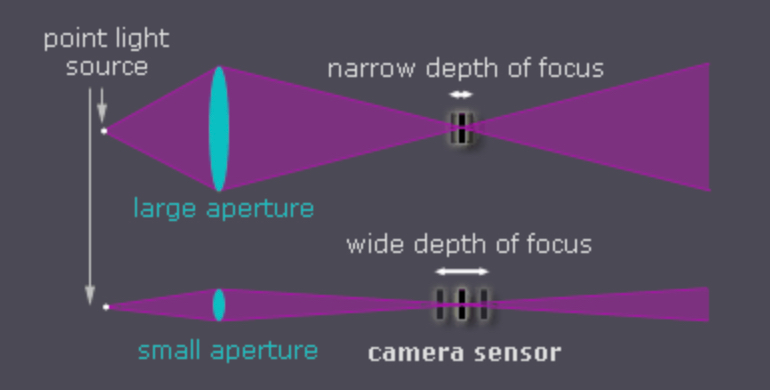
Но маркетинг Apple, образно говоря, не привык считаться с подобными ограничениями. Было объявлено, что отныне iPhone снимает как профессиональная камера. Так родился знаменитый портретный режим.
Портретный режим: первые шаги
Идея, реализованная в Купертино, была элегантна в своей простоте: раз получить красивое боке оптическим путём невозможно — попробуем вычислить его математически.
Когда смартфон пытается программно имитировать размытие фона, перед ним встаёт одна главная задача: понять трёхмерную структуру сцены. Иными словами, необходимо построить так называемую карту глубины. Это чёрно-белое изображение, в котором закодировано расстояние от каждой точки сцены до объектива камеры. Чем светлее пиксель — тем он ближе к камере; чем темнее — тем дальше.

Возникает ключевой вопрос: откуда вообще взять эти данные о расстоянии? У человека для определения глубины есть два глаза, работающих совместно. Apple пошли тем же путём: раз у iPhone теперь две камеры сзади — почему бы этим не воспользоваться?
Так в портретном режиме iPhone начал снимать сцену одновременно на две камеры и по разнице между полученными изображениями вычислять карту глубины — по принципу стереоскопического зрения, свойственного человеку.
Однако полученная таким образом карта оказывалась весьма грубой. Поэтому Apple сразу дополнили систему алгоритмами машинного обучения, призванными сгладить края и исправить наиболее очевидные ошибки.
Результат получился… терпимым. При условии, что зритель не всматривается слишком пристально. Первые версии портретного режима работали исключительно с лицами людей. Алгоритм старался удерживать в фокусе лицо, а всё остальное аккуратно замыливал — во многом для того, чтобы замаскировать огрехи сегментации и неточности в карте глубины.


Иными словами, несмотря на громкие маркетинговые заявления, до реальной замены большой оптики было ещё очень далеко.
Google Pixel 2: вторая камера не нужна
Прогресс, однако, не стоял на месте. Уже через год в игру вступила компания Google со своим Pixel 2 — и продемонстрировала, что для создания портретного размытия вторая камера вообще не обязательна.
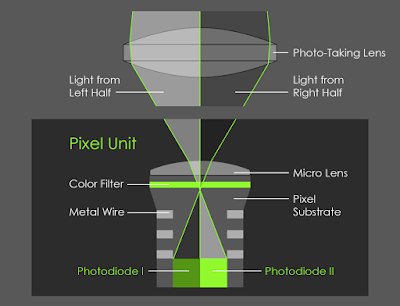
Вместо неё инженеры Google использовали фокусировочные субпиксели единственного сенсора — технологию PDAF (Phase-Detect Auto-Focus, фазовый автофокус). Суть её в том, что каждый пиксель матрицы фактически разделён на два субпикселя. Камера получает два почти идентичных изображения, между которыми существует микроскопический параллакс — ничтожный сдвиг, обусловленный тем, что свет попадает на каждый субпиксель под чуть разным углом.

Этой минимальной разницы между двумя изображениями оказалось достаточно, чтобы строить карту глубины не хуже, чем у iPhone. То есть тоже — весьма посредственно.

В последующие годы все производители двигались по накатанной колее. Алгоритмы становились умнее, сегментация — аккуратнее, края — чище. К двум камерам добавлялся LiDAR-сканер (Apple), Time-of-Flight сенсоры (Samsung, Huawei), всё более сложные нейросетевые модели для определения глубины.

Но за почти десять лет ни один производитель так и не научился идеально имитировать реальную оптику.
Портретный режим оставался инструментом «для домашнего альбома и социальных сетей». Приемлемым — но далёким от совершенства. Любой, кто хоть раз всматривался в границы между объектом и размытым фоном на портретном снимке со смартфона, видел характерные артефакты: ореолы вокруг волос, размытые кончики ушей, резко «обрезанные» контуры плеч.
Vivo входит в игру
И тут к игре подключилась компания Vivo. Без громких пресс-конференций, без обещаний революции, без хвастливых слайдов с надписью «лучшая камера в истории» — их смартфоны просто начали фотографировать на уровне, который заставил индустрию обратить внимание.
Размытие — естественное. Каждый волосок, каждая ниточка, каждая шерстинка — идеально проработаны. Количество ошибок сведено к минимуму. Некоторые кадры откровенно трудно отличить от снимков, сделанных на полноценную беззеркальную камеру.
Как компания, которую за пределами Китая многие знают лишь понаслышке, сумела сделать то, что лидеры рынка не добились за десять лет?
Логичное предположение: они нашли способ строить идеальную карту глубины. Но нет. Ответ оказался куда более неожиданным.

В Vivo честно признали: построить точную карту глубины на смартфоне — задача нерешаемая в принципе. Ограничения, заложенные в самой физике маленького сенсора и короткого базиса между камерами, не позволяют этого сделать. Но вместо того чтобы биться головой о стену, инженеры Vivo нашли обходной путь.
Они решили создавать весь размытый фон целиком. Генерировать его с нуля.

Да, именно так. Тот красивый размытый фон на портретных снимках со смартфонов Vivo — это не результат «умного» размытия исходного изображения. Это генерация. И, забегая вперёд, скажем, что размытие — далеко не единственное, что генерируется.
Но прежде чем хвататься за сердце и обвинять Vivo в «нейросатанизме», стоит разобраться в том, как именно работает эта технология. Потому что она, по существу, гениальна.
Диффузионные модели: почему боке на смартфонах не работало
Чтобы понять, в чём заключается прорыв Vivo, необходимо сначала осознать, почему все предшествующие методы имитации боке неизбежно давали сбой.
Ахиллесова пята всех существующих алгоритмов программного размытия — это области с так называемым разрывом глубины. Границы, где происходит резкий переход от близких объектов к дальним: контур головы на фоне далёкой стены, пальцы руки перед размытым пейзажем, прядь волос, выбившаяся из общей массы.

Именно на этих границах даже самые продвинутые алгоритмы начинают давать ошибки. Причина фундаментальна: все существующие методы строго опираются на карту глубины. Если в карте есть неточности — а они неизбежны, — то неточности возникнут и в размытии. Избежать этого практически невозможно в местах, где присутствует множество мелких деталей: волосы, мех, ветви деревьев, складки ткани.
В результате алгоритм попадает в одну из двух ловушек.
Либо он размывает то, что размывать нельзя — и вокруг объекта появляется характерный мутный ореол, «свечение», которое мгновенно выдаёт программную природу размытия.
Либо, напротив, не размывает то, что следовало бы — и по контуру объекта возникают жёсткие, неестественные края, словно фигуру вырезали ножницами и наклеили на размытый фон.
Самое обидное в этой ситуации — всё остальное может быть сделано безупречно: экспозиция, цвета, общая композиция, характер размытия вдали от границ. Но эти мелкие дефекты на переходах мгновенно бросаются в глаза и разрушают всю иллюзию.

У Vivo же — именно там, где все прочие спотыкаются, — внезапно всё работает. Как?
Ответ связан с технологией, которая в последние годы перевернула всю индустрию генеративного искусственного интеллекта. Речь о диффузионных моделях — тех самых нейросетях, на которых построены Midjourney, Stable Diffusion и их многочисленные аналоги. Именно они генерируют бесконечные потоки изображений: от фотореалистичных портретов до фантастических пейзажей.
Рассуждение инженеров Vivo было логичным: если диффузионная модель способна генерировать любые изображения в высоком разрешении с впечатляющей детализацией — почему бы не обучить её генерировать изображения с оптически корректным размытием?

Так появился алгоритм BokehDiff.
Как работает BokehDiff
BokehDiff — это диффузионная модель, построенная на базе архитектуры Stable Diffusion XL. Разработчики этого не скрывают: соответствующая научная работа опубликована в открытом доступе на arxiv.org и была принята на конференцию ICCV 2025 — одну из наиболее авторитетных площадок в области компьютерного зрения.
Однако работает BokehDiff совершенно нестандартно.
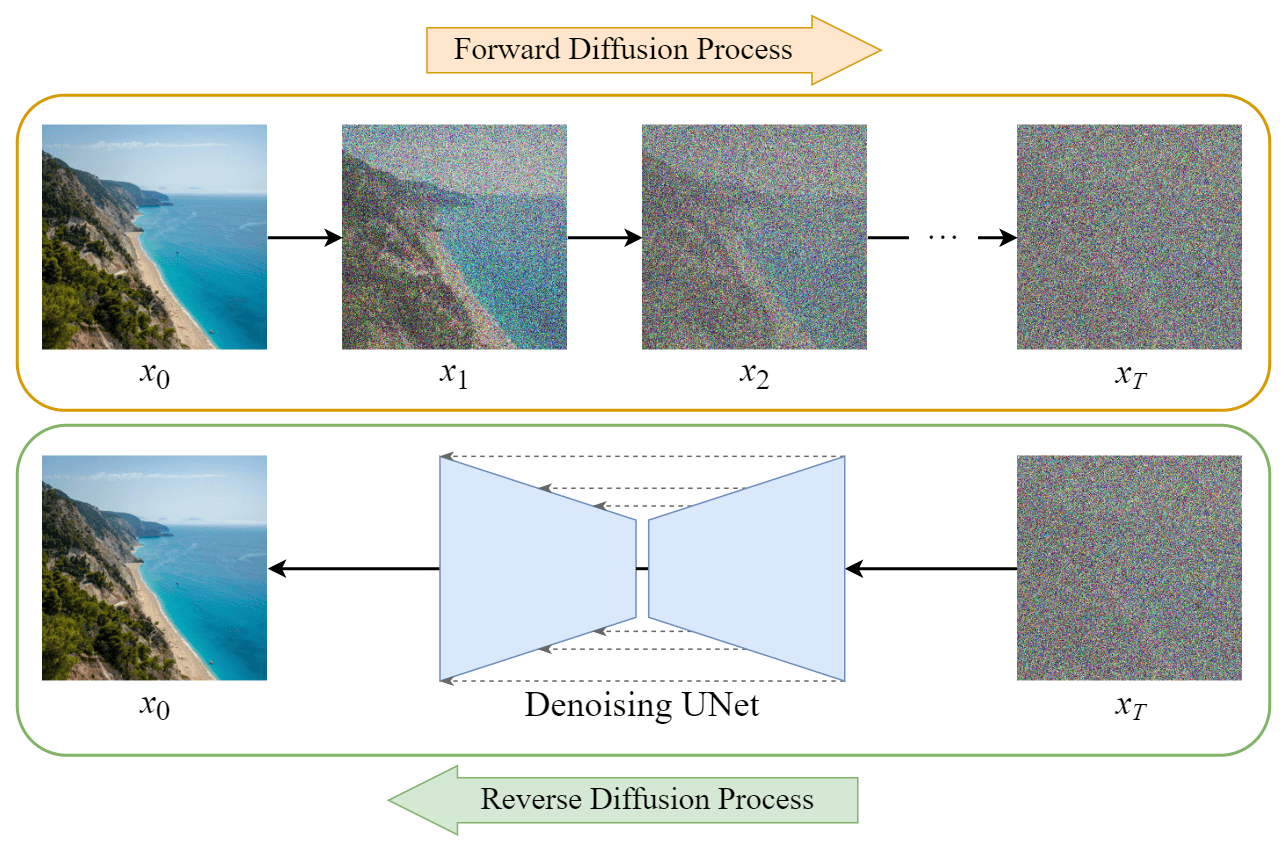
Для понимания необходимо кратко напомнить, как функционируют обычные диффузионные модели. По своей сути это чрезвычайно продвинутые системы подавления шума, наделённые, образно говоря, богатым воображением.

Базовый принцип прост. Модели предъявляется изображение, состоящее из случайного шума, и даётся указание: «На этой картинке — суслик. Убери шум и покажи суслика». Модель шаг за шагом удаляет шум, на каждом этапе «воображая» всё больше деталей. Через сотню, две сотни, пять сотен итераций шум исчезает — а суслик действительно появляется.
Существует и другой сценарий использования. Берётся готовое изображение в низком качестве, к нему добавляется шум, а затем модели сообщают: «На самом деле это превосходная фотография в высоком разрешении. Просто шум мешает её разглядеть». Нейросеть послушно удаляет шум и попутно дорисовывает детали, которых в исходном изображении не существовало.
Но в этом подходе кроются две фундаментальные проблемы.
Во-первых, диффузию невозможно применить «чуть-чуть». Каждый раз, добавляя шум к изображению, мы разрушаем его исходную структуру и затем собираем заново. В процессе картинка неизбежно меняется: модель привносит собственные «фантазии», искажает детали, подменяет текстуры.
Во-вторых, сотни итераций — это огромные вычислительные затраты. Для серверных GPU это терпимо, но для мобильного процессора — совершенно неприемлемо. Пользователь не станет ждать минуту, пока смартфон обработает портретный снимок.
Требовался алгоритм, который работает быстро, не фантазирует лишнего и при этом соблюдает физику оптического размытия.
И здесь инженеры Vivo в буквальном смысле перевернули саму идею диффузионных моделей.
Они решили вообще не добавлять шум к исходному изображению. Вместо этого они взяли чёткую, необработанную фотографию — без каких-либо изменений — и «сказали» нейросети: «Это зашумлённая версия снимка с боке. Найди этот шум и удали его. Но главное — сделай всё за один проход».
С точки зрения нейросети, чёткое изображение — «неправильное». Оно «испорчено шумом», который скрывает под собой «истинную» размытую версию. Задача сети — найти этот «шум» и удалить его. И попытка — всего одна.
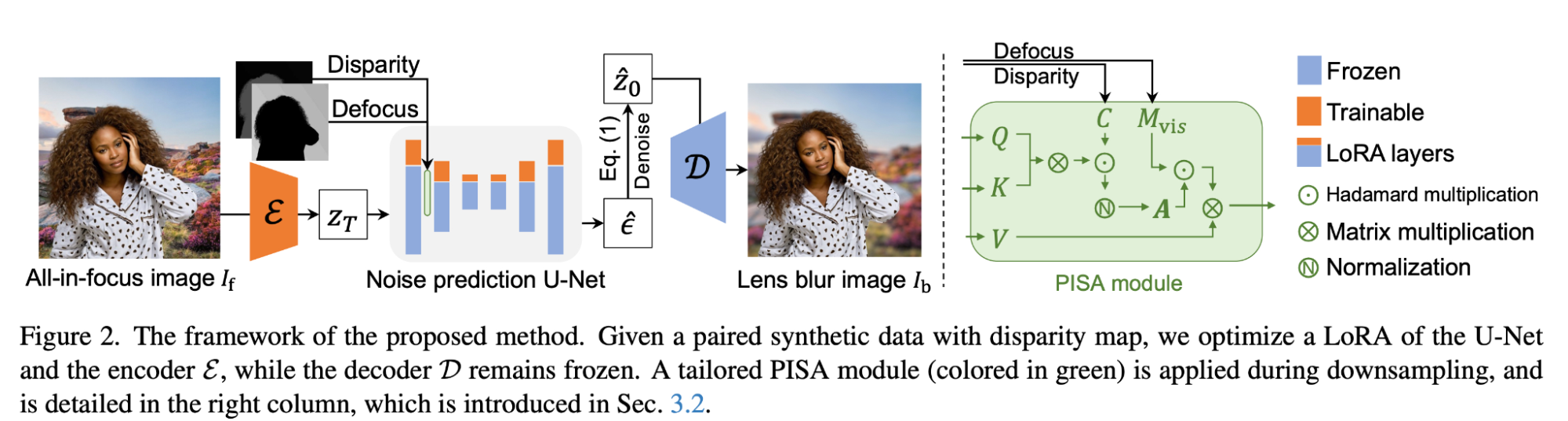
Результат превзошёл ожидания. Никаких сотен итераций. Никаких неконтролируемых фантазий. На выходе — аккуратное, визуально убедительное боке за один вычислительный шаг.
PISA: физика на страже реализма
Но одной лишь генерации недостаточно. Принципиально важно, чтобы размытие выглядело не просто красиво, а оптически корректно — как у настоящей камеры с большим объективом.
Поэтому в архитектуру BokehDiff встроен специализированный модуль, выполняющий роль строгого надзирателя за физической достоверностью результата. Он называется PISA — Physics-Inspired Self-Attention, «физически вдохновлённый модуль самовнимания».
Чтобы понять его роль, нужно знать, что в обычных диффузионных моделях механизмы самовнимания (self-attention) отвечают за общее понимание структуры изображения. Они следят за композицией и обеспечивают целостность: без них нейросеть могла бы нарисовать глаз «где-нибудь» в произвольном месте; с ними она понимает, что глаз должен располагаться строго определённым образом относительно носа, рта и другого глаза.
В BokehDiff модуль самовнимания выполняет иную задачу. PISA следит не за композицией картинки, а за физикой размытия, контролируя соблюдение трёх ключевых принципов.
Первый принцип — сохранение энергии (Energy-Conserved Normalization). Свет не возникает из ниоткуда и не исчезает бесследно. Когда пиксель размывается, его яркость не пропадает — она перераспределяется между соседними пикселями. PISA следит за тем, чтобы суммарная яркость сцены оставалась неизменной. Это устраняет тёмные пятна и засветы, типичные для программного размытия.
Второй принцип — ограничение кругом нерезкости (Circle-of-Confusion Spatial Constraint). В реальной оптике всё устроено просто: чем дальше объект от плоскости фокусировки, тем сильнее он размывается. PISA воспроизводит эту зависимость программно. Модуль берёт карту глубины, выбранную точку фокусировки и виртуальную диафрагму, после чего для каждого пикселя рассчитывает допустимый радиус размытия. В итоге степень размытия не скачет хаотично от пикселя к пикселю: объекты вблизи фокуса остаются чёткими, удалённые плавно уходят в боке, а размер кружков нерезкости определяется значением виртуальной диафрагмы — в точности как у настоящего объектива.
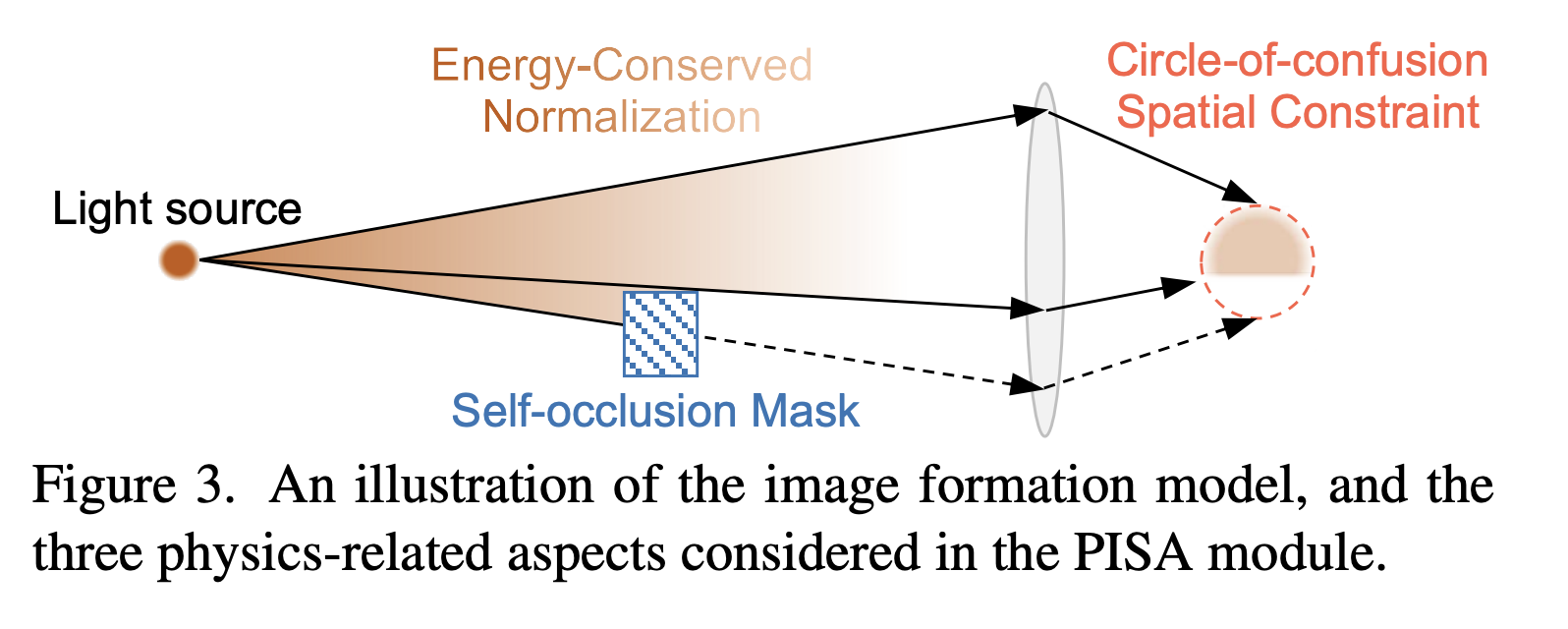
Третий принцип — маска самоокклюзии (Self-Occlusion Mask). Это, пожалуй, самый важный из трёх. PISA следит за тем, чтобы размытый фон не «наезжал» на объекты переднего плана. Модуль попиксельно строит маску видимости, определяя, что принадлежит переднему плану (и должно располагаться «поверх» всего), а что является фоном (и уходит на задний слой).
Именно благодаря маске самоокклюзии алгоритм столь успешно справляется с волосами, шерстью, нитками и полупрозрачными деталями — теми самыми элементами, на которых неизменно спотыкались все предшествующие методы. Границы остаются чистыми, без ореолов и грубых краёв.
И ещё одно важное следствие: даже если карта глубины содержит ошибки (а она неизбежно их содержит), на финальном результате это почти не сказывается. Почему? Ответ — в том, как модель обучали.

Как приручить BokehDiff: секрет обучающих данных
Классическая проблема в мире нейросетей — качество обучающих данных. Чтобы обучить алгоритм уровня BokehDiff, в идеале необходимы тысячи, а лучше десятки тысяч идеальных пар фотографий: одна — полностью резкая, и она же — с настоящим оптическим боке, снятая в абсолютно идентичных условиях.

Где взять такой массив данных? Снять его на реальную камеру невозможно: между двумя кадрами камера неизбежно чуть сдвинется, изменится освещение, подует ветер — а для обучения критична даже минимальная разница между парами. Создать датасет средствами трёхмерного рендеринга тоже не выход: сгенерированные сцены выглядят неестественно и «пластмассово», а обученная на них модель будет плохо работать с реальными фотографиями.
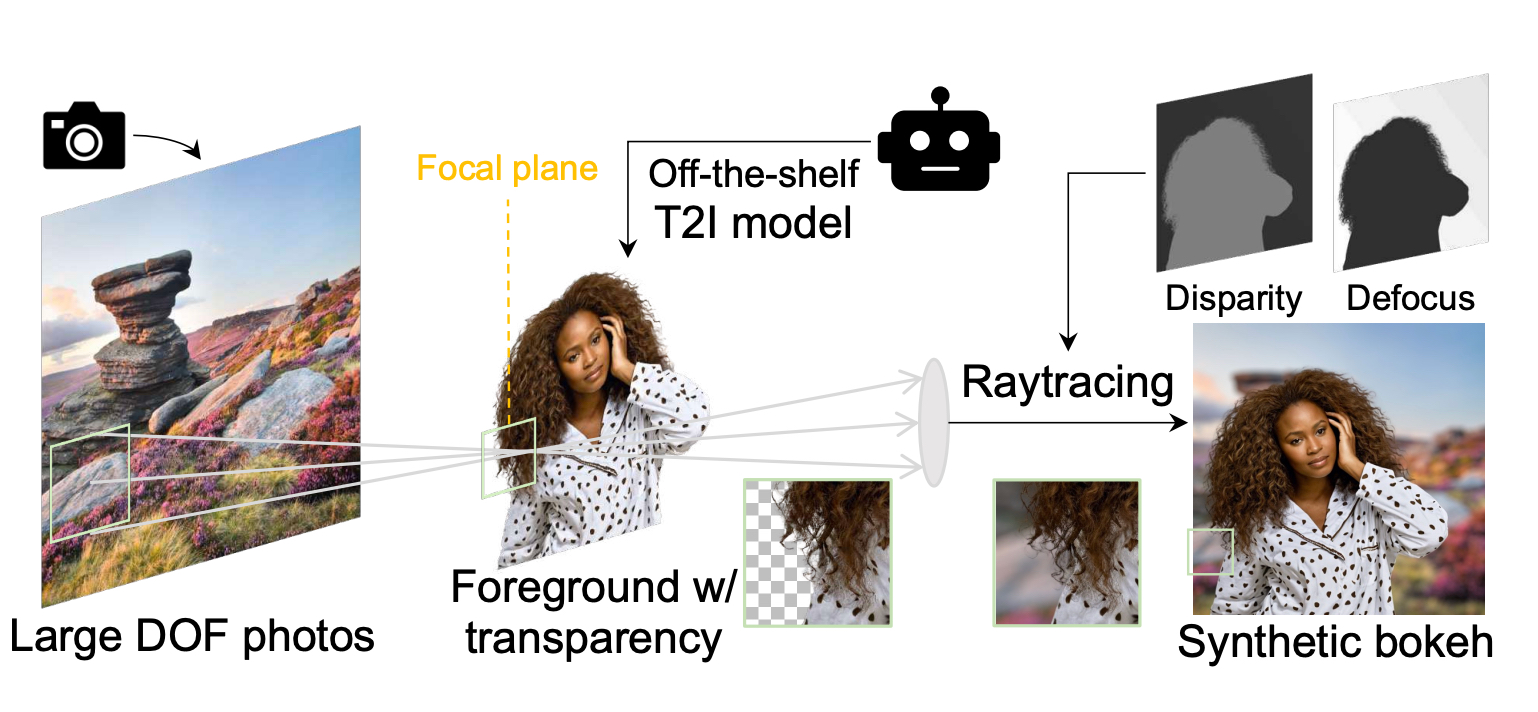
Инженеры Vivo нашли остроумное решение. Раз они и так работают с диффузионными моделями, способными генерировать фотореалистичные изображения, — почему бы не сгенерировать идеальный обучающий датасет? Процесс был устроен следующим образом. Сначала было собрано большое количество реальных, высококачественных фотографий фонов, снятых с максимальной резкостью и глубиной. Затем поверх этих подлинных фонов с помощью диффузионных моделей генерировались фотореалистичные объекты переднего плана: люди, животные, предметы — причём сразу с альфа-каналом, то есть с идеально проработанной прозрачностью и краями. После этого фон размывался физически корректным образом — с учётом точно известных параметров: расстояния до каждого объекта, диафрагмы, фокусного расстояния.
В результате получился датасет, о котором можно только мечтать: идеальные пары фотографий — резкая и размытая версии — с любой диафрагмой на выбор и безупречной маской сегментации.

Но самое интересное — и самое принципиальное — решение последовало далее. В реальности ничего идеального не бывает. Карта глубины, которую смартфон строит в полевых условиях, всегда содержит ошибки, шум и неточности. Поэтому при обучении инженеры начали целенаправленно портить карту глубины, подаваемую на вход модели. Вносили ошибки, шум, снижали точность и разрешение — имитируя те несовершенства, с которыми алгоритм неизбежно столкнётся в реальной жизни.

В результате BokehDiff научился не полагаться слепо на карту глубины и не «паниковать» из-за ошибок, а принимать решения по контексту — опираясь на своё «понимание» того, как должно выглядеть оптически корректное размытие. Именно поэтому на практике алгоритм демонстрирует поразительную устойчивость к неточностям входных данных.
Можно без преувеличения сказать, что BokehDiff — это прорыв в вычислительной оптике, которого индустрия ждала почти десять лет.
Тем не менее необходимо сделать оговорку. На момент публикации этого материала (середина 2025 года) BokehDiff используется только в новейших флагманах Vivo 300-й серии, и то не во всех режимах. К примеру, портретная съёмка на фронтальную камеру по-прежнему опирается на более ранние методы обработки. Но компания заявляет о планах по значительно более широкому внедрению алгоритма в будущих устройствах.
Нейромазня: слон в комнате
BokehDiff — далеко не единственная нейросеть, работающая в камерах смартфонов Vivo. И если портретное размытие вызывает преимущественно восхищение, то другие нейросетевые модели порождают куда более противоречивые чувства.

Прежде чем перейти к деталям, уместен вопрос: откуда вообще стало известно, что именно алгоритм BokehDiff используется в смартфонах Vivo — и конкретно в моделях X300 и X300 Pro?
Ответ прост. Был отправлен запрос напрямую одному из авторов научной работы — ведущему инженеру подразделения Vivo Camera Research. И он ответил. Более того, он не только подтвердил предположение относительно BokehDiff, но и предоставил информацию о четырёх других моделях, которые уже функционируют в камерах смартфонов Vivo прямо сейчас.
Все четыре модели, как и BokehDiff, являются диффузионными. Но есть принципиальное отличие: они не размывают детали, а, напротив, дорисовывают их.
Модель первая: TSD-SR — универсальное сверхразрешение
TSD-SR (One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution) — алгоритм повышения чёткости и детализации. Он работает практически постоянно, обрабатывая все фотографии целиком — вне зависимости от режима съёмки.
Как и BokehDiff, модель функционирует в один шаг, что делает её примерно в сорок раз быстрее аналогичных диффузионных алгоритмов сверхразрешения. При этом, согласно опубликованным бенчмаркам, TSD-SR демонстрирует лучшее качество среди всех конкурирующих методов.
Результаты действительно впечатляют. На сравнительных иллюстрациях, приведённых в научной работе, видно, как алгоритм восстанавливает мельчайшие текстуры оперения птиц, структуру радужной оболочки глаза, узоры на крыльях бабочек — детали, которые в исходном изображении были либо смазаны, либо отсутствовали вовсе.


Модель вторая: TriFlowSR — сверхразрешение для архитектуры
TriFlowSR (Ultra-High-Definition Reference-Based Landmark Image Super-Resolution with Generative Diffusion Prior) — узкоспециализированный алгоритм сверхразрешения, предназначенный исключительно для архитектурных объектов.

Результаты этой модели выглядят почти невероятно. Размытые, едва различимые декоративные элементы зданий — лепнина, черепица, резьба по камню — после обработки приобретают такую степень детализации, что возникает ощущение, будто фотография была переснята с близкого расстояния.

Отдельного внимания заслуживает сравнение с универсальным TSD-SR на тех же архитектурных сценах: специализированная модель неизменно выигрывает. Это объясняет, зачем в смартфон необходимо интегрировать сразу несколько разных нейросетей: универсальный алгоритм в принципе не способен достичь того качества, которое обеспечивает модель, обученная на узком классе изображений.

Модель третья: TADiSR — сверхразрешение для текста
TADiSR (Text-Aware Real-World Image Super-Resolution via Diffusion Model with Joint Segmentation Decoders) — ещё один специализированный алгоритм, на сей раз ориентированный на текст в изображениях.

Номера домов, уличные вывески, надписи на этикетках — всё, что при цифровом увеличении обычно превращается в нечитаемую кашу, TADiSR аккуратно восстанавливает, возвращая буквам чёткие очертания. Практичная и полезная технология, не вызывающая никаких этических вопросов.
Модель четвёртая: AuthFace — и тут начинаются проблемы
AuthFace (Towards Authentic Blind Face Restoration with Face-oriented Generative Diffusion Prior) — модель реконструкции лиц. И именно на ней Vivo, мягко говоря, споткнулись.

Когда смартфон дорисовывает детали архитектуры или повышает чёткость текста — никто не возражает. Пользователи рады дополнительным деталям. Но когда нейросеть начинает «работать» с лицами людей, отношение меняется кардинально.
Что, как правило, первым делом делает новый владелец смартфона Vivo? Ищет способ отключить все бьютификации и нейросетевую дорисовку лиц. Профильные форумы переполнены жалобами и рецептами «как это выключить». Увы, сделать это безболезненно и без компромиссов — практически невозможно.


Но в чём причина недовольства? Неужели алгоритм плох? Отнюдь. С технической точки зрения AuthFace — один из лучших в своём классе. На сравнительных иллюстрациях из научной работы хорошо видно: там, где конкурирующие модели (GFP-GAN, CodeFormer, DR2, BFRffusion, SUPIR) выдают откровенные артефакты и деформации, AuthFace показывает весьма достойный результат.
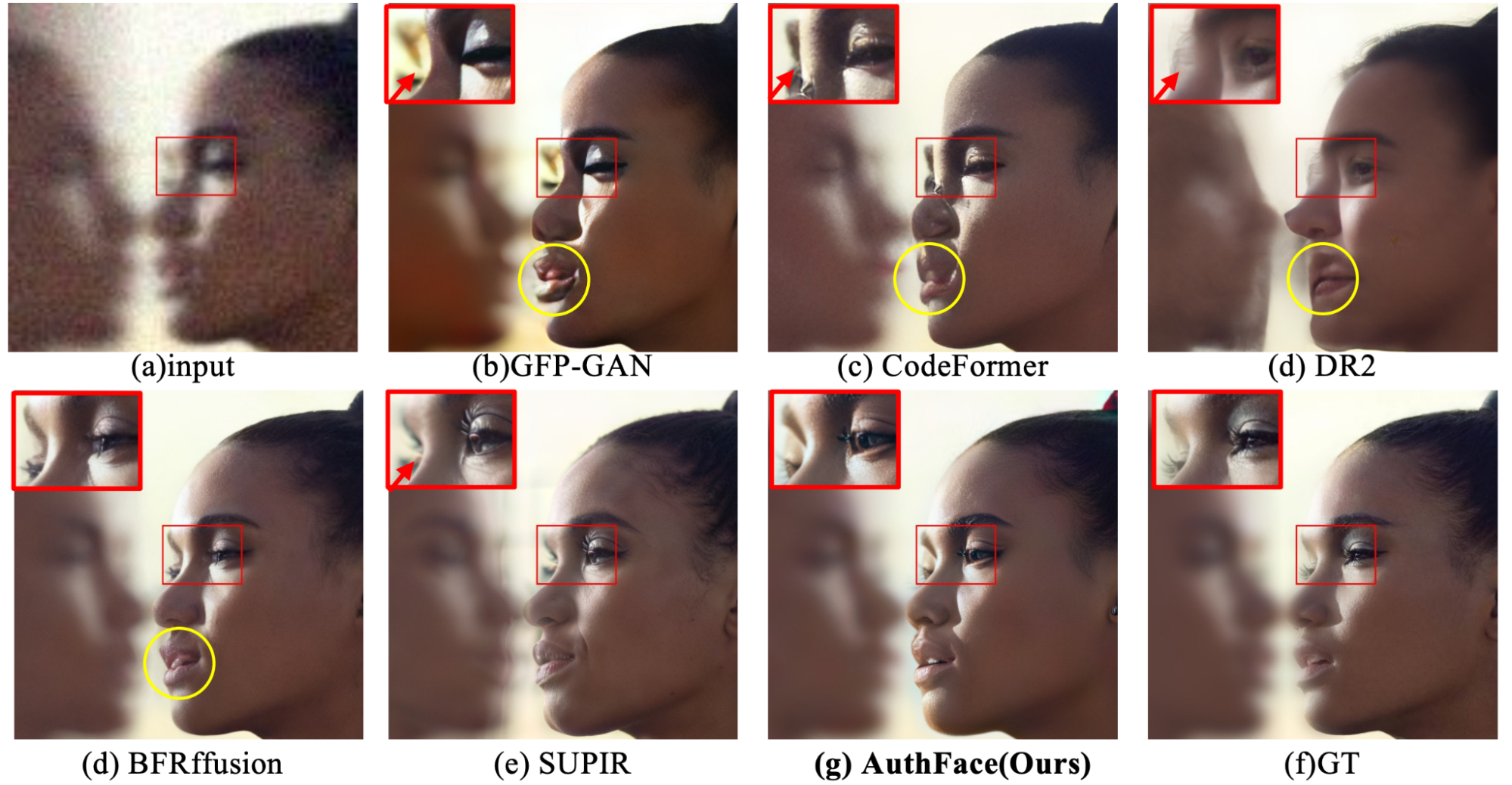
Но — не идеальный. И в этом заключается ключевая проблема.
Если нейросеть дорисовала лишнюю травинку на газоне или несуществующую текстуру на кирпичной кладке — это, по большому счёту, никого не волнует. Но если она добавила или изменила хотя бы одну деталь на лице — морщину, родинку, форму брови — это ошибка, которой нет прощения. Человеческий мозг натренирован распознавать лица с невероятной точностью, и любое, даже незначительное отклонение от ожидаемого вызывает мгновенное ощущение «неправильности».
Аналогия с кулинарией здесь напрашивается сама собой. Нейросети в камере — как приправы в блюде. Применённые уместно и в меру, они превращают пресную кашу из серых пикселей во вкусную, аппетитную фотографию. Но стоит переборщить — и блюдо становится несъедобным.
У китайских производителей уже есть все необходимые ингредиенты. Осталось лишь немного подправить рецепт — найти правильный баланс между агрессивной обработкой и естественностью. Впрочем, не исключено, что дело попросту в различии вкусов: внутренний рынок Китая традиционно благосклонен к заметной обработке лиц, тогда как западная и российская аудитория предпочитает естественность.
Аппаратный фундамент: железо и оптика
Если до сих пор речь шла преимущественно о программных алгоритмах, то теперь пришло время взглянуть на аппаратную составляющую — и понять, почему крупнейшим брендам действительно есть о чём беспокоиться.
На протяжении многих лет Apple, Samsung и Google продавали по премиальной цене довольно среднее — по нынешним меркам — железо. Сенсоры в их смартфонах меньше, чем у китайских конкурентов. Оптика слабее: хроматические аберрации, потеря резкости по краям кадра и, в случае Apple, ставшие притчей во языцех блики от ярких источников света.

Справедливости ради, долгое время это работало. За счёт превосходных алгоритмов обработки, мощных специализированных чипов и жёсткой вертикальной интеграции аппаратного и программного обеспечения те же iPhone, пусть и не блистая по «железным» характеристикам, стабильно выдавали качественный и, что не менее важно, предсказуемый результат. Пользователь знал: нажал кнопку — получил хорошую фотографию. Без сюрпризов.
Сейчас ситуация изменилась. iPhone стабильно уступают китайским флагманам в слепых сравнениях фотографий. Причём речь не только о Vivo — они проигрывают практически всем: Huawei, Xiaomi, OPPO и даже OnePlus.
В области видеосъёмки iPhone пока удерживает позиции — это правда. Однако разрыв стремительно сокращается. И на то есть объективные причины.

Китайские производители за последние годы совершили качественный скачок не только в нейросетевых алгоритмах, но и в аппаратной части — буквально по всем фронтам.
Возьмём Vivo в качестве примера. Компания не просто приобретает «с полки» самый дорогой и крупный сенсор, доступный на рынке, и устанавливает его в смартфон. Vivo совместно с Sony и Samsung проектируют сенсоры по собственным техническим заданиям. Иными словами, сенсоры заточены под конкретный конвейер обработки изображений, используемый в их устройствах.
Аналогичная ситуация с оптикой. Vivo разрабатывают оптические модули самостоятельно, а также — если верить маркетинговым материалам — в сотрудничестве с немецкой компанией ZEISS. Вне зависимости от степени участия ZEISS, главное остаётся фактом: оптика кастомная, созданная под конкретные задачи, а не взятая из каталога стандартных компонентов.

Но, пожалуй, наиболее примечательные вещи происходят в области специализированных чипов обработки изображений.
Два ISP-чипа: VS1 и V3+
В модели X300 Pro установлены сразу два процессора обработки изображений (ISP — Image Signal Processor), разработанных собственным подразделением Vivo.
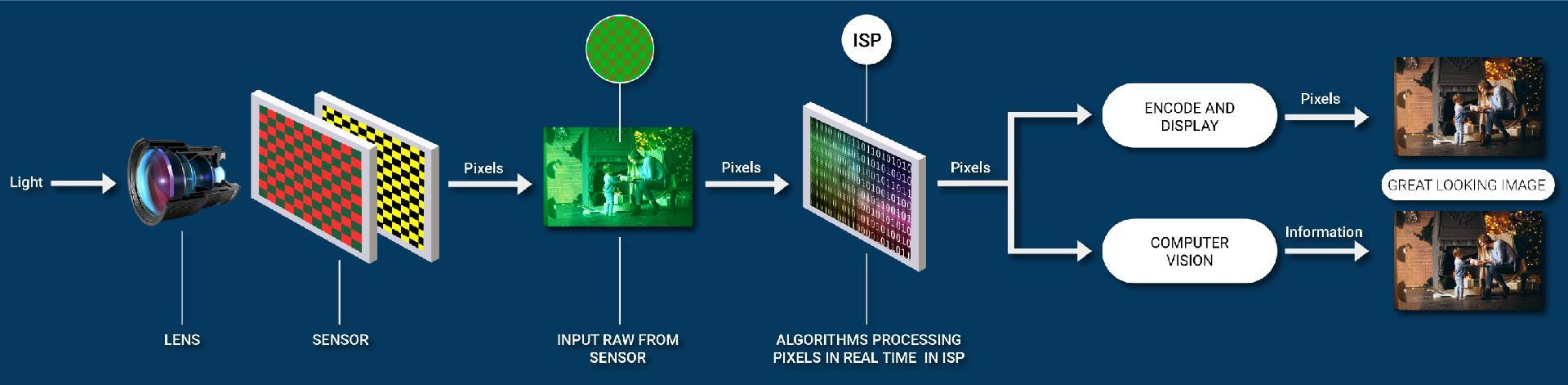
Первый — VS1. Он отвечает за предварительную обработку: экспозицию, автофокус, HDR-стекинг (объединение нескольких кадров с разной экспозицией), первичное шумоподавление. VS1 работает ещё до того, как фотография «станет» фотографией. Он анализирует сцену в реальном времени, помогает правильно экспонировать кадр, навести фокус и собрать максимально чистые исходные данные. Именно поэтому уже «на входе» у Vivo картинка отличается высоким качеством.
Кроме того, VS1 отвечает за превью в приложении камеры. Благодаря этому пользователь видит на экране смартфона практически финальный результат — включая портретное размытие в реальном времени, — ещё до нажатия кнопки спуска. Долгие годы эта функциональность была эксклюзивной прерогативой Apple.
Второй чип — V3+. Он отвечает за постобработку: берёт на себя все наиболее сложные и ресурсоёмкие задачи, в том числе запуск всех описанных выше нейросетевых алгоритмов — BokehDiff, TSD-SR, TriFlowSR, TADiSR, AuthFace.
Интеграция в Dimensity 9500: переломный момент
Однако самое важное событие произошло в 2025 году. Vivo заключили соглашение с компанией MediaTek, и чип V3+ был интегрирован непосредственно в системный чипсет Dimensity 9500.

Это означает, что процессор обработки изображений теперь находится на одном кристалле с центральным процессором, графическим ядром, памятью и всей остальной логикой — и выполнен по самому передовому на сегодня техпроцессу: 3 нанометра.
Практические следствия этого решения значительны. Максимальная скорость обработки при минимальном энергопотреблении и нагреве. Минимальные задержки при передаче данных между компонентами.

Результаты ощутимы на практике. Смартфон меньше нагревается при длительной работе камеры. Быстрее снимает и обрабатывает кадры. И может позволить себе такую роскошь, как запись 4K-видео в портретном режиме при 60 кадрах в секунду. Или запись 4K LOG с частотой 120 кадров в секунду — напрямую во внутреннюю память. iPhone на момент публикации этого материала подобных возможностей не предоставляет.
Прежде встроить кастомный ISP непосредственно в систему на кристалле могли позволить себе лишь Apple (со своими чипами серии A и M), Samsung (с линейкой Exynos) и отчасти Google (с процессорами Tensor, хотя, справедливости ради, это не помогло им совершить прорыв в качестве фото). Теперь в этом элитном клубе — и Vivo.

Более того, Vivo не закрывают доступ к своему ISP для других производителей, использующих платформу Dimensity 9500. Возможно, именно поэтому OPPO Find X9, построенный на том же чипсете, фотографирует на уровне, вплотную приближающемся — а порой и превосходящем — результаты самого Vivo. Вероятно, свою роль играет и собственное партнёрство OPPO с Hasselblad.
Главное наблюдение: судя по темпам прогресса, китайские производители не собираются останавливаться.
Стоит ли выбрасывать iPhone?
Итак, напрашивается вопрос: настало ли время массово переходить на китайские смартфоны и отказываться от Apple, Google и Samsung?
Ответ — нет. По крайней мере, не для всех.

В формате «достал и снял, не задумываясь о настройках» iPhone и Google Pixel по-прежнему остаются чемпионами. Особенно iPhone — это, пожалуй, самая удобная, самая надёжная и, что критично для многих пользователей, самая предсказуемая камера на рынке. Вы знаете, какой результат получите. Каждый раз.
С китайскими флагманами, особенно с Vivo, придётся потрудиться. Разобраться в многочисленных настройках, которых там действительно много. Сделать сотни тестовых снимков. Понять, какой режим и для какой сцены лучше подходит. Найти оптимальный баланс нейросетевой обработки — или научиться её отключать.
Но если вам интересна мобильная фотография как таковая, если вы готовы экспериментировать с настройками, изучать возможности камеры и стремитесь к максимально возможному качеству снимков со смартфона — китайские бренды сегодня заслуживают самого пристального внимания.

По крайней мере, в области фотографии они объективно опережают нынешних лидеров рынка на пару поколений. И куда вся эта история приведёт нас дальше — пожалуй, самый интригующий вопрос, ответ на который ещё только предстоит узнать.
