2017 год: биткоин взлетает, майнеры скупают видеокарты, цены удваиваются. 2020 год: пандемия, заводы стоят, чипов не хватает никому. 2026 год: SSD на терабайт, который стоил 50 долларов, — уже 110, и ещё поди найди. Цены на оперативную память выросли больше чем вдвое за прошлый год. Каждый раз казалось: переживём, рассосётся. Крипта обвалилась — цены вернулись. Пандемия ушла — цены вернулись. Но на этот раз виновник никуда не уходит.
Статья 1995 года, которую никто не читал
За окном 1995 год. Интернет ещё по модему. Windows 95 только вышла. И вот в это время два исследователя из Виргинского университета — Уильям Вулф и Сали Маки — публикуют статью с названием, которое звучит почти как издёвка: «Удар о стену памяти: последствия очевидного». Мол, ребята, всё на поверхности, посмотрите на графики.

Графики показывали вот что. Скорость процессоров и скорость памяти растут одновременно — обе экспоненциально. Но экспоненты разные. Процессоры в те годы ускорялись примерно на 60–80% в год, а память — всего на 7%. Обе кривые ползут вверх, только одна — как ракета, другая — как улитка. И Вулф с Маки указали на принципиальный момент: разница между двумя расходящимися экспонентами сама растёт экспоненциально.
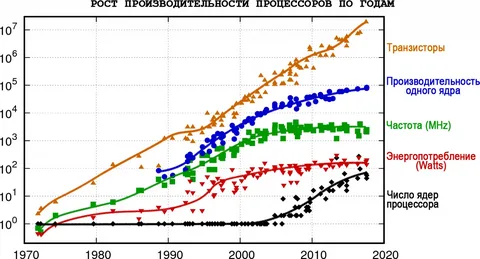
То есть со временем разрыв не сглаживается — он ускоряется. Рассуждение было простым. Допустим, процессор находит нужные данные в быстром кэше в 99 случаях из ста. Звучит отлично. Но оставшийся один процент нужно тянуть из основной оперативной памяти, которая медленнее в десятки раз. Если каждое такое обращение стоит процессору хотя бы пять тактов ожидания, производительность катастрофически проседает. Неважно, насколько быстрый процессор — он просто сидит и ждёт данные. Как курьер с едой: кухня готовит за три минуты, а лифт в двадцатиэтажном доме едет пятнадцать. Повар уже свободен, еда стынет, а курьер стоит. Скорость доставки определяется не скоростью готовки, а скоростью лифта.
Вулф и Маки подсчитали: даже при фантастическом показателе попаданий в кэш на уровне 99,8% стена будет достигнута через 11–12 лет — примерно к 2007 году. Индустрия, конечно, не стояла на месте. Инженеры придумали многоуровневую кэш-память L1, L2, L3, предсказатели ветвлений, которые угадывали нужные данные и подгружали их заранее, внеочередное исполнение команд — когда процессор, вместо ожидания застрявшей операции, переключается на другую задачу. Десятки умных трюков, чтобы процессор как можно реже обращался в медленную память. И это работало. Стену удалось не разрушить, но отодвинуть. А потом пришёл искусственный интеллект.
Почему нейросети убивают все трюки, накопленные за 30 лет
Классические программы — те, которые мы использовали десятилетиями, — работают с относительно небольшими кусками данных. Они часто возвращаются к одним и тем же участкам памяти: загрузил, посчитал, снова обратился к тому же. Кэш с этим справляется отлично — он как раз хранит то, к чему часто обращаются. Нейросети устроены принципиально иначе. Им нужно протащить через процессор гигабайты параметров — десятки миллиардов чисел — причём последовательно, слой за слоем. Один раз загрузил, использовал, выкинул, загрузил следующий. Кэш здесь бесполезен: данных слишком много, они попросту не помещаются. И каждый раз приходится обращаться в основную память — ту самую медленную.
Все трюки, которые индустрия копила тридцать лет, — кэши, предсказатели, переупорядочивание операций — разом перестали спасать. Нейросети их обнулили. Чтобы понять, почему проблема настолько глубока, нужно вернуться к самим корням.
В 1945 году математик Джон фон Нейман описал архитектуру, по которой до сих пор работают практически все компьютеры на планете. Идея простая: есть процессор, который считает, и есть память, которая хранит данные и инструкции. Между ними — шина, по которой информация передаётся туда и обратно. В 1945 году это было откровением: универсальная машина вместо десятков специализированных, компьютер, который можно перепрограммировать, не перепаивая провода. Но есть принципиальный изъян. Всё проходит через одну шину. Один мост через реку, по которому в обе стороны едут грузовики. Пока машин мало — проблемы нет. Но когда процессор научился считать в сотни раз быстрее, чем память отдаёт ему данные, мост встал в пробку. Для обычных задач терпимо, но для искусственного интеллекта, который непрерывно ворочает миллиарды параметров, — неприемлемо.
Так что пророчество Вулфа и Маки сбылось — только не совсем так, как ожидалось. Не через двенадцать лет, а через тридцать. И не из-за обычных программ, а из-за нейросетей, которых в 1995 году толком не существовало. Стена, залатанная синей изолентой из кэшей и умных алгоритмов, всё-таки не выдержала. Просто понадобился достаточно сильный удар.
Что происходит внутри нейросети: миллиарды чисел и проблема внимания
Любая нейросеть — это набор параметров, проще говоря, чисел. Когда вы слышите «модель на 70 миллиардов параметров», это буквально означает 70 миллиардов чисел, каждое из которых нужно хранить в памяти. Эти числа называют весами модели, и они — результат обучения. В них закодировано всё знание нейросети: грамматика, логика, факты, способность рассуждать.
Сколько это в гигабайтах? Зависит от формата хранения. В стандартном формате FP16 (половинная точность, два байта на число) модель на 70 миллиардов параметров весит 140 гигабайт. Для сравнения: топовая потребительская видеокарта Nvidia RTX 4090 имеет 24 гигабайта видеопамяти. Модель на 70 миллиардов параметров туда не влезет даже теоретически — нужно минимум шесть таких карт. И это только чтобы модель поместилась, без учёта всего остального. А остальное — самое интересное.
Все современные большие языковые модели — GPT, Claude, Gemini — построены на архитектуре, которую называют трансформером. Её придумали в 2017 году инженеры Google, и с тех пор она стала стандартом отрасли. Ключевой механизм трансформера — так называемое внимание (attention). Представьте, что вы читаете длинное предложение. Чтобы понять смысл каждого слова, нужно учитывать контекст — все остальные слова вокруг. «Замок» означает разное в «дверной замок» и «средневековый замок» — вы это понимаете, потому что смотрите на соседние слова. Механизм внимания делает ровно то же самое, только математически.

Каждый элемент текста — токен — смотрит на все остальные токены, чтобы понять контекст. Для этого модель создаёт три матрицы: Query («что я ищу»), Key («что здесь есть») и Value («какая информация мне нужна»). Перемножение Query на Key даёт матрицу внимания — таблицу, где для каждой пары токенов записано, насколько они связаны друг с другом. И вот здесь начинается проблема.
Размер этой таблицы пропорционален квадрату длины контекста. При контексте в 2 000 токенов — примерно небольшой рассказ — матрица содержит 4 миллиона элементов. Ерунда, влезает в кэш процессора. Но возьмём модель с контекстом 128 000 токенов — это целая книга. Матрица внимания вырастает до 16 миллиардов элементов: 32 гигабайта для одного слоя, а слоёв в модели — десятки. Вот ключевая закономерность: удвоили контекст — получили не двойной, а четырёхкратный рост потребления памяти. Это квадратичная зависимость.

Есть ещё один механизм, о котором знают в основном инженеры, но именно он часто становится главным пожирателем памяти. Когда языковая модель генерирует текст, она выдаёт по одному слову за раз. Для каждого нового слова ей нужно обратиться ко всему предыдущему контексту разговора. Пересчитывать всё с нуля каждый раз было бы безумно дорого. Поэтому модель запоминает промежуточные результаты — ключевые матрицы для всех предыдущих токенов. Эту «шпаргалку» называют KV-кэшем (Key-Value cache). И вот этот кэш растёт линейно с длиной контекста и числом одновременных пользователей.
Возьмём конкретные числа. Для модели Llama 70B при контексте 128 000 токенов и одновременном обслуживании 32 пользователей KV-кэш пожирает больше терабайта памяти. Даже со специальными методами сжатия — около 640 гигабайт. Только на «шпаргалку». Веса модели — 140 гигабайт, а кэш — от 640 до 1 300 гигабайт. Шпаргалка оказалась в несколько раз тяжелее учебника.

Чтобы выдать одно слово ответа, модели нужно загрузить из памяти все свои веса — все 140 гигабайт — прогнать через них данные, получить результат и для следующего слова загрузить все 140 гигабайт снова. Каждый токен требует полной загрузки весов модели из памяти. Скорость этой загрузки определяется пропускной способностью памяти. На видеокарте Nvidia H100 — одном из самых мощных ИИ-ускорителей — память отдаёт данные со скоростью 3 350 гигабайт в секунду. Делим 3 350 на 140 — получаем теоретический максимум примерно 24 токена в секунду. Этот потолок определяется не скоростью вычислений: процессорные ядра H100 могут считать гораздо быстрее. Потолок определяется тем, как быстро память отдаёт данные.
Видео — это уже совсем другой масштаб катастрофы
Текст — самая лёгкая модальность для ИИ. Возьмём видео. Одна секунда ролика в 720p — это 30 кадров. Каждый кадр — почти миллион пикселей. Каждый пиксель — три цветовых канала. Одна секунда видео содержит информации больше, чем целая книга в текстовых токенах.

Инженеры идут на хитрость: видео сначала сжимают в так называемое латентное пространство — примерно в сто раз. Представьте, что вы берёте детальную фотографию и превращаете её в грубый набросок, из которого можно восстановить оригинал. С этим наброском и работает нейросеть. Но даже после стократного сжатия пятисекундный ролик в 720p — это больше 80 000 токенов. А квадратичная зависимость внимания при 80 000 токенов означает матрицу из 6,4 миллиарда элементов только для одного слоя. И слоёв — десятки.

Конкретные цифры. Модель Stable Diffusion Video генерирует всего 14 кадров — меньше полсекунды видео. При разрешении 576 × 1024 пикселя она потребляет 39,5 гигабайта пиковой памяти. Генерация статичной картинки того же разрешения — 6,3 гигабайта. Рост в шесть раз, и это за жалкие полсекунды. Обучение модели уровня Sora обходится свыше 100 миллионов долларов при использовании более шести тысяч видеокарт одновременно. И значительная часть стоимости — это память. Генерация видео в 4К без предварительного сжатия потребовала бы примерно в 130 раз больше памяти, чем при разрешении 256 × 256 пикселей.
А на горизонте — мультимодальные модели, которые одновременно обрабатывают текст, картинки, видео, звук, трёхмерные данные. Контекстные окна за пять лет выросли с 2 000 токенов у GPT-3 до 10 миллионов у Llama 4 Scout — рост почти в пять тысяч раз. Каждый шаг к мультимодальности, каждый новый тип данных, каждое увеличение контекста — это новый порядок потребления памяти. И каждый раз система упирается всё в ту же стену.
HBM: почему обычная оперативка не справляется
Стандартный модуль DDR5, который стоит в вашем компьютере, выдаёт около 64 гигабайт данных в секунду. Для офисных задач, игр и даже видеомонтажа — более чем достаточно. Но чтобы модель Llama 70B сгенерировала хотя бы 24 слова в секунду, память должна отдавать 3 350 гигабайт в секунду. DDR5 медленнее в пятьдесят с лишним раз. На ней модель будет выдавать меньше одного слова за две секунды.
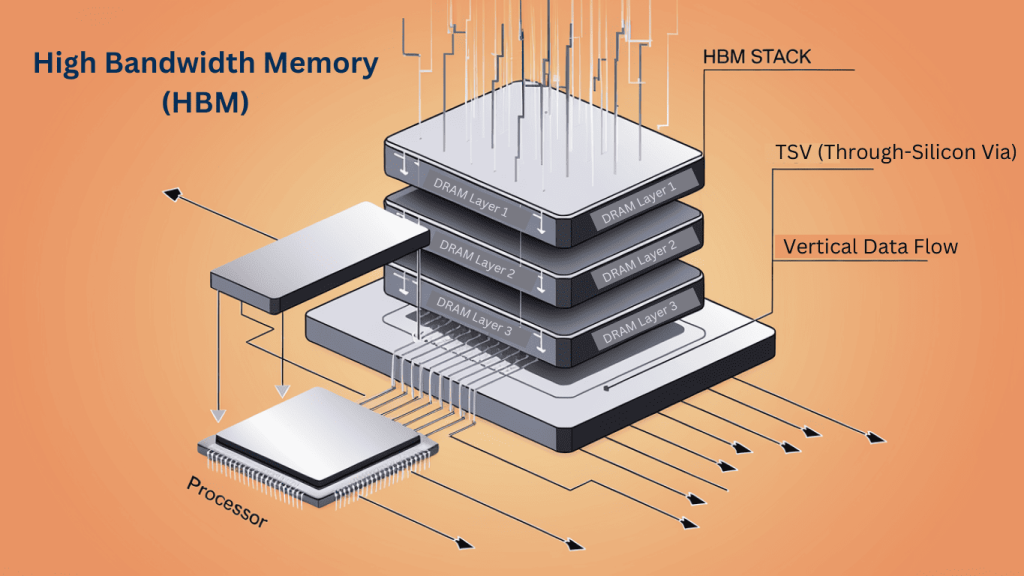
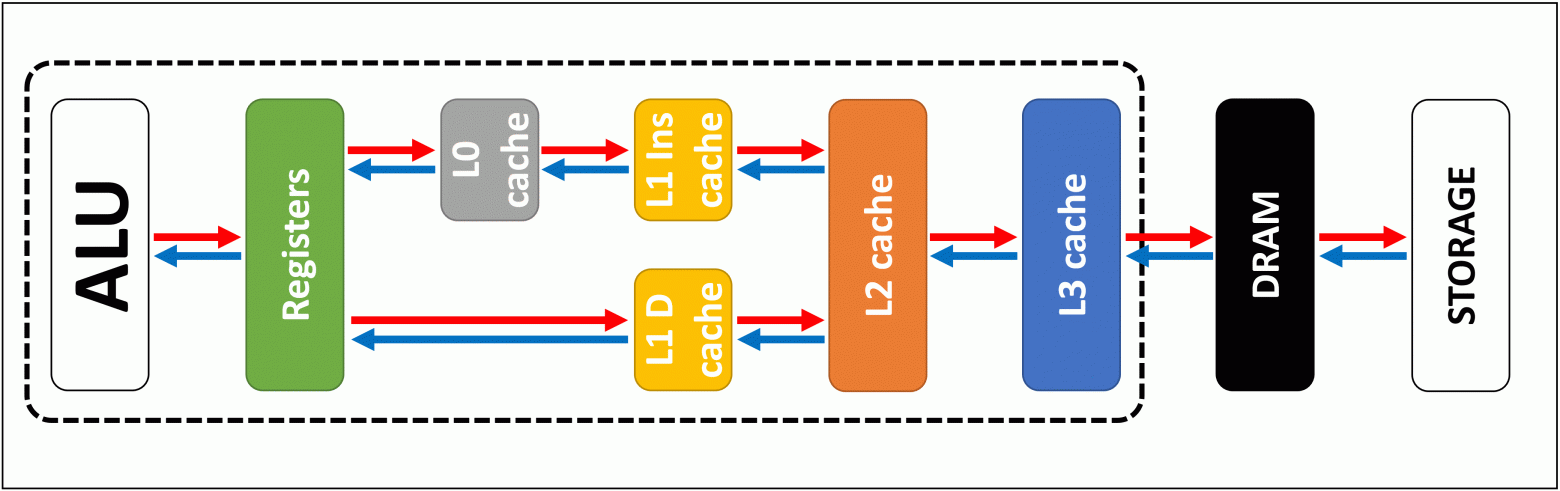
Решение называется HBM — High Bandwidth Memory, память с высокой пропускной способностью. Чтобы понять её устройство, представьте обычную оперативную память как одноэтажный склад: широкий, просторный, но данные вывозятся через одни ворота. HBM — это многоэтажный склад с идеальной логистикой: восемь или двенадцать этажей, буквально уложенных один над другим, соединены тысячами грузовых лифтов. Данные едут одновременно со всех этажей.
Технически это восемь-двенадцать кристаллов обычной памяти, уложенных друг на друга. Каждый кристалл — тончайшая кремниевая пластинка. Они соединены тысячами микроскопических вертикальных контактов, пронизывающих все слои насквозь. Их называют TSV — Through-Silicon Vias, сквозные кремниевые переходы. Это и есть те самые лифты. Ширина шины данных у HBM — 1024 бита; у DDR5 — 64 бита.
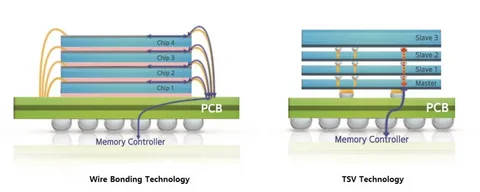
Шестнадцатикратная разница. При этом каждый отдельный бит бежит по шине HBM медленнее, чем в GDDR. Но если GDDR — скоростная однополосная трасса, то HBM — шестнадцатиполосная магистраль. Один стек HBM3E выдаёт скорость больше 1 200 гигабайт в секунду. Nvidia H200 несёт шесть стеков HBM3E — суммарная пропускная способность превышает 4 800 гигабайт в секунду.

Но есть одна принципиальная сложность. Нельзя просто взять HBM и припаять к видеокарте: стандартные дорожки на печатной плате слишком грубые для тысяч микроскопических контактов. Нужен специальный промежуточный слой — кремниевый интерпозер, на котором рядом размещаются GPU и стеки HBM. Технология, по которой это делается, называется CoWoS (Chip on Wafer on Substrate), и практически полностью принадлежит TSMC. Можно произвести сколько угодно GPU и HBM по отдельности — без упаковки CoWoS они бесполезны, как двигатель и колёса без шасси. Nvidia зарезервировала больше 60% всех мощностей CoWoS до конца 2026 года.
Три компании против всего мира: дефицит, который не закончится
HBM производят всего три компании в мире. SK Hynix — южнокорейский гигант, контролирует около 60% рынка. Micron и Samsung делят оставшееся, при этом Samsung долгое время отставал из-за проблем с качеством при квалификации HBM3E у Nvidia. Сейчас он восстанавливает позиции и уже первым в мире начал коммерческие поставки HBM4.

Все три производителя заявили, что их продукция HBM полностью распродана до конца 2026 года. В апреле 2026 года Samsung предупредила инвесторов о «значительном дефиците» по всем видам памяти минимум до 2027 года. Это зеркально повторяет слова SK Hynix, произнесённые неделей ранее. Когда два из трёх крупнейших производителей памяти одновременно предупреждают о многолетнем дефиците — это не квартальная флуктуация.

Рынок HBM растёт стремительно: по оценкам аналитиков, с 35 миллиардов долларов в 2025 году до 100 миллиардов к 2028-му. HBM уже потребляет 23% всего мирового производства пластин для DRAM — против 19% в 2025-м. Производство одного бита HBM требует примерно в три раза больше мощностей пластинного производства, чем обычная DDR5. Это означает: каждый гигабайт HBM, произведённый для нужд ИИ-кластера, — это три гигабайта обычной памяти, которые не попали на потребительский рынок.
В итоге весь мировой ИИ висит на острове в 180 километрах от Китая — Тайване, где расположена TSMC с монополией на CoWoS, — и на полуострове рядом с Северной Кореей, где сосредоточены заводы Samsung и SK Hynix.
Почему дорожает ваш ноутбук, смартфон и SSD
Производство памяти — замкнутая система. Чистые комнаты, в которых делают чипы, стоят миллиарды. Новая фабрика строится три-пять лет. Оборудование для литографии — штучный товар, его производят буквально несколько компаний на планете. Нельзя просто щёлкнуть пальцами и удвоить выпуск.

Samsung и SK Hynix перенаправили до 40% своих мощностей под HBM. Почему? Маржинальность. Один стек HBM3E приносит в пять-десять раз больше прибыли, чем горсть модулей DDR5 для потребительского рынка. Если вы директор завода и можете продать одну и ту же пластину кремния в виде обычной памяти или в пять-десять раз дороже в виде HBM — что вы выберете?

Дальше — чистая арифметика. По данным IDC, цены на DRAM выросли примерно в два с половиной раза только за 2025 год. DRAM-цены в первом квартале 2026 года прибавили ещё 90% по сравнению с четвёртым кварталом 2025-го — это «беспрецедентный» рост, по словам аналитика TrendForce. Стоимость чипов NAND, основы любого SSD, выросла с 4 до 10 долларов за чип за несколько месяцев — то есть более чем вдвое. Потребительские SSD на терабайт, которые в 2023 году стоили 50 долларов, сегодня стоят 110 и выше.
Как это бьёт по конкретным рынкам? В среднем сегменте память составляет 15–20% себестоимости смартфона. Когда память дорожает на десятки процентов, производителям некуда девать эту разницу, кроме как переложить на покупателя. По прогнозам, рынок смартфонов сократится на 12,9% в 2026 году, рынок ПК — на 11,3%. Средняя цена смартфона достигнет исторического максимума. Lenovo, Dell, HP, Asus и Acer уже предупредили клиентов о повышении цен на 15–20%.

Apple и Samsung пострадают меньше — у них и резервы побольше, и долгосрочные контракты с поставщиками памяти, заключённые на несколько лет вперёд. Micron и вовсе свернул потребительский бренд Crucial, полностью переориентировались на корпоративных и ИИ-заказчиков. Lenovo описал происходящее как «беспрецедентный» рост затрат.
Это не циклический дефицит, не сезонная флуктуация, которая сама рассосётся. Вспомните криптобум 2017–2018: видеокарты подорожали вдвое-втрое, потому что майнеры скупали всё подряд. Но когда крипта рухнула — цены вернулись. Ковидный дефицит 2020–2021: из-за сбоев логистики нельзя было купить ни консоль, ни ноутбук. Пандемия прошла — рынок выровнялся. Но сейчас совсем другая история.
Гиперскейлеры — Microsoft, Amazon, Google — заключают многолетние контракты на поставку памяти. Они забирают ёмкости не на квартал и не на год, а на несколько лет вперёд. IDC называет происходящее не циклическим дефицитом, а «потенциально перманентным стратегическим перераспределением мирового кремния».
Как инженеры штурмуют стену: три атаки со стороны программ
Если вы думаете, что индустрия сидит сложа руки, — вы плохо знаете инженеров. Атака идёт с двух сторон: программисты учат модели обходиться меньшим количеством памяти, а разработчики железа перестраивают саму архитектуру чипов.
Первый программный подход. Помните матрицу внимания, которая растёт квадратично с длиной контекста? В 2022 году аспирант Стэнфорда Три Дао задал неочевидный вопрос: зачем вообще собирать эту огромную таблицу целиком? Представьте, что вам нужно сложить гигантский пазл, но стол слишком маленький. Стандартный подход — найти стол побольше. Подход Дао — собирать по частям: берёте фрагмент, собираете на маленьком столе, запоминаете результат, убираете, берёте следующий. Технически алгоритм FlashAttention нарезает данные на блоки, которые помещаются в быструю кэш-память прямо на чипе. Каждый блок обрабатывается локально, в медленную основную память ничего не записывается вообще. Обращений к памяти в девять раз меньше, скорость в два-четыре раза выше. Именно благодаря FlashAttention контекстные окна моделей смогли вырасти до сотен тысяч токенов.
Второй подход — квантование. Каждый параметр модели — число с кучей знаков после запятой. Квантование — это, по сути, округление. Переход от стандартного формата FP16 к INT4 сжимает модель в восемь раз. Llama 70B влезает в 35 гигабайт вместо 140. Цена: для небольших моделей на сложных логических задачах точность может проседать на 8–14%. Крупные модели переносят квантование гораздо легче — потери составляют всего 1–3%. Но в задачах, где важна каждая доля процента — например, в медицинской диагностике — даже такая разница имеет значение.
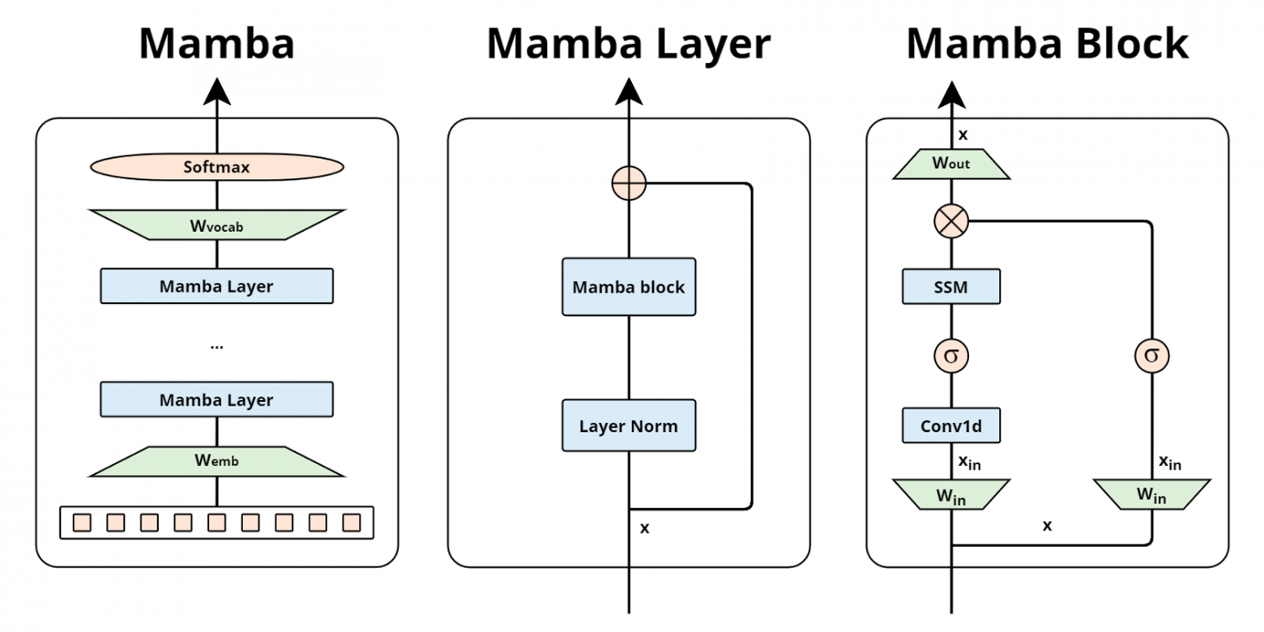
Третий, самый смелый подход — вопрос: а что, если проблема не в памяти, а в самой архитектуре трансформера? В 2023 году появилась архитектура Mamba, построенная на совершенно другом фундаменте. Она вообще не строит квадратичную матрицу внимания, а обрабатывает текст последовательно, храня компактное состояние разговора. Расход памяти постоянный — хоть тысяча токенов, хоть миллион. Пока это нишевое решение, но оно может изменить правила игры.
Как инженеры штурмуют стену: три атаки со стороны железа
Представьте повара, у которого кухня на втором этаже, а холодильник в подвале. Духовка уже раскалилась, сковородка готова — а он бегает по лестнице за каждым ингредиентом. Вот так выглядит современный процессор, ожидающий данные из памяти.
Первое решение — перенести холодильник на кухню. Технология Processing-in-Memory встраивает вычислительные блоки прямо в чипы памяти. Данные обрабатываются там, где лежат, никуда не путешествуя. Samsung уже продемонстрировал рабочие прототипы. Второе решение — сделать к холодильнику скоростной лифт. Технология CXL (Compute Express Link) объединяет память нескольких серверов в общий пул. Немного медленнее локальной памяти, зато ёмкость вдвое-вчетверо больше — GPU перестают простаивать в ожидании данных. Google 24 марта 2026 года анонсировала TurboQuant — собственную технологию сжатия памяти для языковых моделей, которая даёт шестикратное снижение потребления памяти при инференсе на H100.

Третье решение — заменить сами провода. Медные соединения на высоких скоростях теряют сигнал катастрофически. Оптические интерконнекты передают данные фотонами — без потерь и нагрева. По прогнозам, к 2028 году без оптики будет просто не обойтись: требования к скорости связи между чипами перешагнут 50 терабайт в секунду.
Каждое из этих решений бьёт в свой участок стены. Вместе они её расшатывают — но пока не пробивают. Новые мощности от Micron и SK Hynix достигнут серийного объёма не раньше 2027–2028 годов. До тех пор структурный разрыв между спросом и предложением сохранится.
Стена стоит. Что дальше?
В 1995 году Вулф и Маки озаглавили свою статью «Последствия очевидного». Ирония в том, что очевидное — самая незаметная вещь на свете. Крипта обвалилась — цены вернулись. Пандемия ушла — цены вернулись. Мы привыкли, что дефициты рассасываются.

Но ИИ растёт, и каждое следующее поколение требует больше памяти, чем предыдущее. Это новая реальность, в которой память становится стратегическим ресурсом. Дешёвые гигабайты закончились не потому, что кто-то что-то сломал или захотел нажиться. Они закончились потому, что самая трансформирующая технология поколения голодна — и сам механизм встроен в её математику, в квадратичный рост матриц внимания, в необходимость каждый раз загружать из памяти сотни гигабайт весов.
Тот, кто разрушит стену памяти, изменит мир не меньше, чем те, кто придумал транзистор. Пока стена стоит. И пока она стоит — ваш следующий ноутбук, смартфон или SSD будет дороже, чем предыдущий.
