Сегодня на пресс-конференции NVIDIA в рамках CES 2022 компания представила новую флагманскую видеокарту RTX 3090 Ti. По словам компании, более подробная информация появится в ближайшее время.
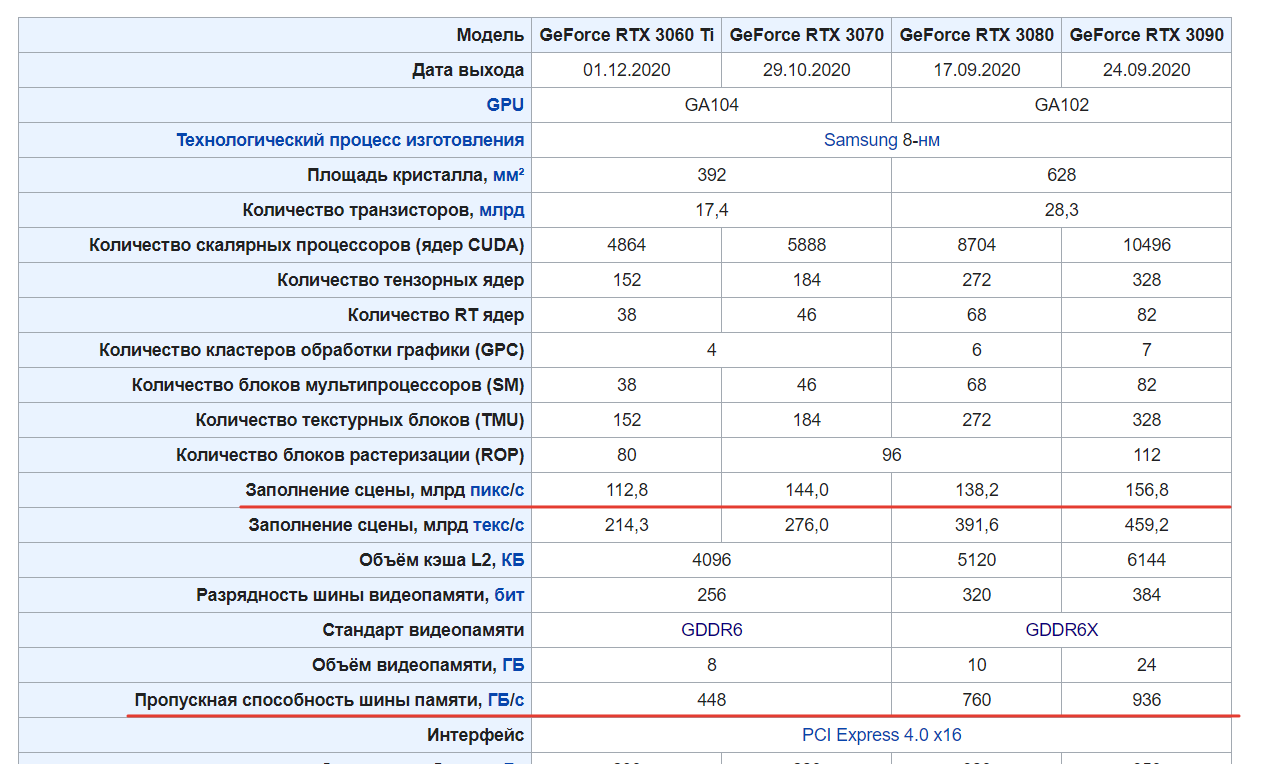
Напомним, что в настоящее время NVIDIA предлагает RTX 3090, RTX 3080 Ti, а RTX 3080 является мейнстримовым флагманом. Все три карты построены на одном и том же чипе GA102, а ключевыми отличиями являются количество активных ядер, тактовая частота и конфигурация памяти.
Как и 3090, 3090 Ti будет иметь 24 ГБ памяти GDDR6X, однако она будет работать на скорости 21 Гбит/с, в отличие от 19,5 Гбит/с у 3090. NVIDIA также утверждает, что GPU способен вычислять 40 шейдерных терафлопсов, выдавать 78 терафлопс в трассировке лучей и 320 тензорных (AI) терафлопс. Это сравнимо с 35,6 шейдерными терафлопс, 69,5 RT терафлопс и 285 тензорными терафлопс у 3090.
Эти цифры представляют собой 12,5-процентный прирост по сравнению с 3090 по всем параметрам и, вероятно, сделают 3090 Ti самой мощной игровой картой из когда-либо созданных. Мы не узнаем, как именно NVIDIA достигла этого, пока не представит полные спецификации, но мы можем сделать несколько предположений.
У 3090 активированы только 82 из 84 потоковых мультипроцессоров GA102, так что, скорее всего, у 3090 Ti работают все 84. Также NVIDIA немного увеличила тактовую частоту основного GPU. Некоторые математические расчеты показывают, что для достижения 40 терафлопной производительности, заявленной NVIDIA, тактовая частота ускорителя у 3090 Ti должна составлять около 1850 МГц (по сравнению с 1695 МГц у 3090).
NVIDIA говорит, что «больше подробностей появится позже в этом месяце», поэтому мы ожидаем, что скоро состоится небольшое мероприятие, посвященное 3090 Ti, где мы узнаем, насколько высока будет цена 3090 Ti. Напомним, что цена GeForce RTX 3090 составляет 1500 долларов.
Также на CES была анонсирована RTX 3050, которая станет самым дешевым графическим процессором 30-й серии для настольных ПК. NVIDIA также не предоставила полных спецификаций, но известно, что у GPU 8 ГБ памяти GDDR6 и он сможет вычислять 9 шейдерных терафлопс, 18 RT терафлопс и 73 тензорных терафлопс. NVIDIA утверждает, что видеокарта сможет работать с «новейшими играми с трассировкой лучей на скорости более 60 кадров в секунду», что, вероятно, правда, если учесть технологию масштабирования DLSS компании.
Как это обычно бывает с картами низшего класса, NVIDIA не будет выпускать версию Founders Edition, но RTX 3050 поступит в продажу через различных аппаратных партнеров компании уже 27 января с ценой 250 долларов или от 25 тысяч рублей.
Intel собирается создать собственные видеокарты для геймеров
Intel собирается создать конкурентов AMD и NVIDIA и в начале 2022 года представит миру свои первые видеокарты на основе микроархитектуры Xe-HPG.
Intel анонсировал новую линейку Arc. В ней появится премиальные графические карты.
Intel Arc создается для геймеров и первые видеокарты должны появится в первом квартале 2022 года. Кодовое имя GPU – Alchemist. Новые видеокарты, которые должны стать прямыми конкурентами видеокартам от AMD и NVIDIA, будут разрабатываться как для ноутбуков, так и для ПК.
В них будет использоваться микроархитектура Xe-HPG. Видеокарты от Intel будут поддерживать трассировку лучей Direct12 X Ultimate и многие другие современные фишки.
Кроме Alchemist нас ждут и другие продукты, но нам известны лишь кодовые имена устройства — Battlemage, Celestial и Druid.
Судя по всему, геймеры по всему миру будут рады, с другой стороны мы еще не знаем хэш-рейт новых видеокарт от Intel…
Google использует ИИ, чтобы создать дизайн чипов меньше чем за 6 часов
Обычно на этот процесс уходит не один месяц у людей, но искусственный интеллект позволяет драматически ускорить этот процесс.
Компания Google объявила о создании софта, который использует машинное обучение и искусственный интеллект для создания дизайн процессоров и чипов. Благодаря этому чип может быть создан всего за 6 часов. Для сравнения человеку требуются месяцы.
Интересно, что метод создания чипов описан в журнале Nature. «Наш метод мы использовали при разработке дизайна нового поколения Google TPU (тензорных процессоров)» — сказала глава отдела машинного обучения для систем Goole Азалия Мирхосейни.
По сути, ИИ рисует некий «план этажа» для более продвинутых систем, далее искусственный интеллект расставляет компоненты, включая CPU, GPU и ядра памяти. Именно на последний процесс «расстановки» у человека может уйти несколько месяцев поскольку инженеры должны продумать все ключевые характеристики, включая площадь чипа, энергопотребление и мощность, в то время как новая система обучения от Google натренирована на 10 тысячах всевозможных вариантов таких «планов этажей». За счет этого она может сделать работу меньше чем за 6 часов.
Рейтрейсинг идёт в недорогие ноутбуки: NVIDIA RTX 3050 и 3050 Ti
NVIDIA продолжает наращивать обороты и наконец представила видеокарты с рейтрейсингом для недорогих ноутбуков. Геймеры будут довольны…
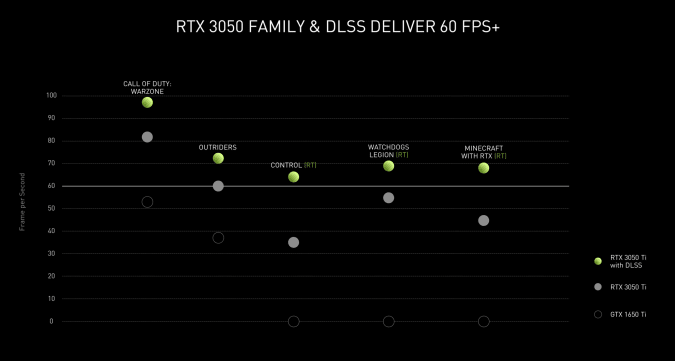
Не так давно компания Samsung анонсировала ноутбук Galaxy Book, одной из деталей которого стала тогда «мифическая» видеокартна NVIDIA GeForce RTX 3050 Ti. Но на самом деле Samsung просто тизернули скорый анонс новой видеографики. Теперь же мы можем официально сказать, что видеокарты с поддержкой технологии трассировки лучей NVIDIA GeForce RTX 3050 и 3050 Ti анонсированы.
По данным NVIDIA с видеокартой RTX 3050 Ti можно ожидать 80 кадров в секунду при Full HD графики со средними настройками и до 95 кадров в секунду с включенной функцией DLSS в игре Call Of Duty: Warzone. Для сравнения GTX 1650 Ti выдавал максимум до 55 кадров в секунду. Также новая графика выдаёт до 70 FPS в Outriders, когда старая в Full HD разрешении показывает 40 кадров в секунду.
Конечно же многих заинтригует поддержка трассировки лучей. По данным NVIDIA в Control при 1080p и включенном DLSS на средней графике с рейтрейсингом ноутбуки смогут работать в 60 кадрах в секунду и выше. При этом речь идёт о ноутбуках, цена на которые будет в районе 800 долларов.
Под капотом у RTX 3050 и 3050 Ti находится 2048 и 2560 CUDA-ядер соответственно. При этом в RTX 3060 ядер почти в два раза больше — 3840. К сожалению, кроме бенчмарков RTX 3050 Ti NVIDIA ничем не поделилось, хотя интересно на что способна и обычная 3050, у которой меньше тензорных ИИ и RT-ядер. Обе видеокарты идут с 4 ГБ GDDR6 памяти и 128-битным интерфейсом. По сути Full HD — это их предельное разрешение. Впрочем, для ноутбуков в этой ценовой категории большего и не надо…
Также будут варианты Max-Q, которые оптимизированы для более тонких ноутбуков. Кстати, информации о видеокартах RTX 3050 для декстопных компьютеров пока нет.
Samsung иначе «упаковал» чип: Быстрее и эффективнее
В условиях нехватки микроэлектронных компонентов по всему миру, Samsung делает новые более быстрые и эффективные «упаковки» для SoC.
Компания Samsung является одним из лидеров в области производства микроэлектроники и как и все испытывает трудности в этом направлении. При этом компания представила новый типа «упаковки» чипа, который потенциально может сделать процессор более эффективным и быстрым.
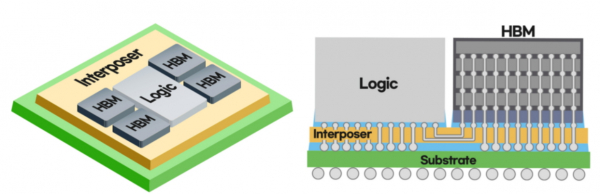
Новая технология называется I-Cube4, который является гибридом двух собственных технологий — I-Cube2 и X-Cube.
Новую технологию разработали и представили в марте 2021 года. Это гетерогенный 2,5D-чип, кристаллы в котором будут располагаться в горизонтальной плоскости.
На чипе можно распологать один или несколько логических кристалов — CPU, GPU, NPU и другие, а также несколько кристаллов высокоскоростной памяти HBM. При этом SoC сделан таким образом, что все эти кристаллы можно рассматривать как одно целое.
Такие чипы можно использовать в 5G, ЦОД, облачных решениях и вычислениях, приложений искусственного интеллекта и так далее. Главная идея в том, чтобы обеспечить скорость и эффективность работы всех ядер — логических и ядер памяти — между собой.
При этом непонятно, когда новые решения от Samsung появятся для заказа.
Не для майнеров: NVIDIA GeForce RTX 3060 будет только для геймеров!
Несмотря на очередной криптовалютный бум, NVIDIA приняла решение ограничить RTX 3060 в возможностях майнинга, чтобы GPU досталась геймерам.
Компания NVIDIA надеется, что видеокарты RTX 3060 достанутся геймероам в руки, ведь со своей стороны они закрывают возможность майнить крипту на этих видеокартах.
Для этого NVIDIA представила новый драйвер, который может задетектить алгоритмы, которые используются для майнинга Ethereum. Как только детекция происходит хэш-рейт карты падает вдвое. Это сделано для того, чтобы обеспечить видеокартами геймеров, которые до сих пор ждут обнволения GPU. Новые рекорды криптовалюты обеспечили новую волную высокого спроса на видеокарты, которые итак трудно было найти и приобрести.
Компания также объявила новую линейку чипов CMP — Crypto Mining Chips, которые сделаны исключительно для криптомайнинга. Эти чипы не будут являться графическими картами и иметь выходы. Такие чипы компания будет выпускать исключительно для майнинга с высокой эффективность и низким энергопотреблением.
«В первую очередь, мы геймеры. Мы хотим донести новые возможности до геймеров, новую архитектуру, новые технологии и игры. GeForce GPU — это видеокарты для геймеров. Со стартом продаж GeForce RTX 3060 мы делаем важный шаг, который поможет видеокарта наконец попасть в руки игрокам» — говорится в заявлении компании.
Доступная GeForce 3060 и RTX30 на ноутбуках: NVIDIA на CES 2021
Компания NVIDIA в рамках CES 2021 объявила о старте продаж ещё одной видеокарты на архитектуре NVIDIA Ampere — самой доступной GeForce RTX 3060. Новая видеокарта появится в продаже в России по цене от 32 990 рублей.
Графические процессоры с цифрой 60 на конце традиционно становятся популярными у массового пользователя. По данным Steam именно такие видеокарты использует большинство.
GeForce RTX 3060 — это полноценная видеокарта, которая поддерживает технологию трассировки лучей, а также DLSS. В сравнении с GeForce 1060 она обладает вдвое большей производительностью и десятикратной скоростью трассировки лучей. Пк с такой видеокартой справится с современными играми, такими как Cyberpunk 2077 и Fortnite даже с включенной технологией RTX. Производитель завялет о возможности играть в 60 fps.
Ключевые особенности GeForce RTX 3060:
13 TFLOPs в шейдерных операциях
25 TFLOPs в трассировке лучей
101 TFLOPs в операциях тензорных ядер для технологии NVIDIA DLSS (Deep Learning Super Sampling)
192-битный интерфейс памяти
12ГБ памяти GDDR6
Также здесь будет доступна технология Resizable BAR, которая поддерживается во всей серии GeForce RTX 30, начиная с RTX 3060. Совместимая материнская плата и PCI Express способны обеспечить быстрый доступ CPU ко всей памяти графического процессора и обеспечивает прирост производительности во многих играх.
Также RTX 3060 поддерживает инновации GeForce, длоступные в 30 серии: NVIDIA DLSS, NVIDIA Reflex и NVIDIA Broadcast. Все эти технологии повышают производительность и качество изображения. Также поддерживается технология трассировки лучей.
Заодно NVIDIA объявила о старте продаж более 70 ноутбуков с поддержкой архитектуры NVIDIA Ampere. Ноутбуки со встроенной графикой GeForce RTX 30 будут стоить от 99 999 рублей. Такие ноутбуки поддерживают технологию Max-Q третьего поколения.
Первые ноутбуки с GPU на базе архитектуры Ampere поступят в продажу уже с 26 января от ведущих производителей: Acer, Alienware, ASUS, Dell, HP, Lenovo, MSI, Gigabyte. Сначала в продаже появятся ноутбуки GeForce RTX на базе GPU GeForce RTX 3080 и GeForce RTX 3070, затем станут доступны ноутбуки с GPU GeForce RTX 3060.
Ноутбуки с RTX 3060 стартуют по цене от 99 999 рублей для России и являются производительнее ноутбуков с предыдущим флагманом NVIDIA — GeForce RTX 2080 SUPER, которые обычно стоили более, чем в 2 раза дороже.
Ноутбуки с RTX 3070 стартуют по цене от 139 999 рублей для России и их производительность на 50% быстрее моделей на базе RTX 2070.
Системы с RTX 3080 стартуют от 199 999 рублей для России.
Как работает видеокарта NVIDIA? Разбор
Рейтрейсинг, тензорные ядра, Тьюринг и Паскаль — все это про видеокарты. Сегодня мы досконально разберёмся — как они работают.
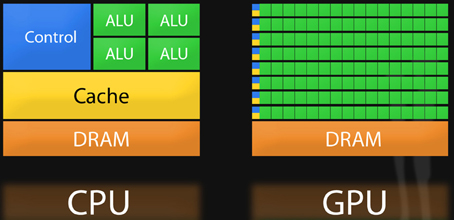
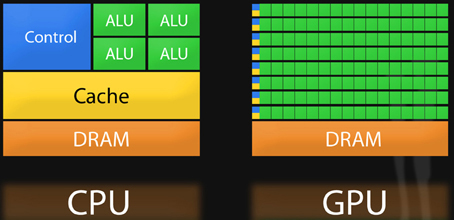
Мы привыкли воспринимать видеокарты как дополнение к основному процессору. А бывают даже интегрированные видюхи. Но на самом деле. Видеокарта — это компьютер в компьютере, который выполняет намного больше операций, чем остальные компоненты системы. Смотрите сами:
В центральном процессоре — 4, 8, ну может 16 ядер. В видеокарте вычислительных блоков — тысячи!
В ней миллиарды транзисторов, гигабайты своей видеопамяти с пропускной способностью до терабайта в секунду.
И всё это потребляет мощности, весит и стоит как отдельный комп!
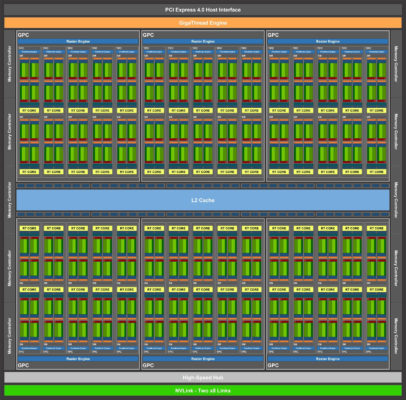
Вот например характеристики GeForce RTX 3090:
Ядра CUDA: 10496 | Тензорные ядра : 328 | Ядра трассировки лучей: 82
28 млрд. транзисторов
Видеопамять: 24 ГБ GDDR6X
Пропускная системной памяти: > 1 ТБ/с
Цена: от 136 990 руб.
Но раз видюхи такие производительные, зачем нам вообще центральный процессор? И в чем всё-таки отличия CPU от GPU?
А чем видеокарты отличаются между собой? Как такая бандура помещается в ноутбук? И главное выясним, можно ли в играть в Cyberpunk 2077 на ноутбуке на ультра-настройках. Поговорим об этом и о многом другом в большом разборе!
Сейчас видеокарты много чего умеют делать и часто делают некоторые задачи куда быстрее и эффективнее CPU? Но к такому положению вещей мы пришли не сразу. Первые видеокарты было бы справедливо назвать ASIC-ками (Application-Specific Integrated Circuit), то есть интегральными схемами специального назначения. Что это значит?
Центральный процессор — это универсальный чип. Он может выполнять совершенно разного рода задачи. Всё потому, что каждое ядро центрального процессора — это много разных блоков, каждый из которых умеет делать свой тип вычислений.
Это удобно, потому как на центральном процессоре мы можем сделать любое вычисление. И в принципе, один огромный ЦП может заменить собой вообще все остальные чипы. Но естественно, это будет неэффективно. Поэтому для специфических задач на помощь центральному процессору часто приходят сопроцессоры или ASIC-ки то есть отдельные чипы, заточенные под эффективное решение какой-то конкретной задачи.
Так в середине 90-х такой конкретной задачей стало ускорение первых 3D-игр вроде Quake!
Первые видеокарты
Без ускорения Quake выглядел достаточно постредсвенно. Всё очень пиксельное и тормозное.
Но стоило прикупить себе волшебный 3D-акселератор. Подключить его к вашей основной 2D-видеокарте снаружи коротким VGA кабелем. Да-да, раньше это делалось так. И Quake превращался в нечто запредельное. Игра становилась, плавной, красочной, а главное работала в высоком для того времени разрешении и соответственно никаких пикселей.
Тогда это воспринималось практически как магия. Но за счет чего происходило такое кардинальное улучшение картинки? Чтобы ответить на этот вопрос, давайте разберемся как работает видеокарта поэтапно.
Как работает видеокарта?
Этап 1. Растеризация.
Трёхмерный объект изначально векторный. Он состоит из треугольников, которые можно описать вершинами. То есть, по сути, объект — это набор вершин, со своими координатами в трехмерном пространстве.
Но ваш экран двумерный, да ещё и состоит из пикселей. Так как нам отобразить векторный 3D объект в двухмерном пространстве? Правильно — спроецировать его!
Мы переносим координаты вершин на плоскую поверхность соединяем их при помощи уравнений прямых на плоскости и заполняем пикселями плоскости треугольников. На этом этапе мы получаем двухмерную проекцию объекта на экране.
Этап 2. Текстурирование
Дальше нам нужно как-то раскрасить модельку. Поэтому на растрированный объект по текстурным координатам натягивается текстура.
Но просто натянуть текстуру недостаточно, ее нужно как-то сгладить. Иначе при приближении к объекту вы просто будите видеть сетку текселей. Прям как в первых 3D-играх типа DOOM. Поэтому дальше к текстуре применяются различные алгоритмы фильтрации.
На первых видеокартах применялась билинейная интерполяция. Её вы и видели на примере с Quake. Всё, что она делает — это линейно интерполирует промежуточные цвета между четырьмя текселями, а полученное значение становится цветом пикселя на экране.
Такую интерполяцию активно используют используют и сейчас. Но в дополнении к ней также делают трилинейную интерполяцию — это еще более продвинутая версия сглаживания, но используют её только на стыках разных уровней детализации текстур, чтобы их замаскировать.
А вот чтобы вернуть четкости текстурам под углами к камере используют анизотропную интерполяцию. Чем выше её коэффициент тем четче получается картинка, так как для получения цвета каждого пикселя делается до 16 выборок. Особенно это заметно на поверхностях, находящихся под острым углом к камере. То есть, к примеру, на полу.
Окей, теперь мы получили цветное изображение. Но этого всё ещё недостаточно, потому как в сцене нет освещения. Поэтому переходим к следующему этапу с интригующим названием пиксельный шейдер или затенение пикселей.
Этап 3. Пиксельный шейдер.
Вообще шейдер — это штука, которая позволяет программисту что-то делать с вершинами, треугольниками и пикселями на программном уровне. В случае Пиксельных Шейдеров — это даёт разработчикам разработчиком возможность динамически менять цвет каждого пикселя экрана по программе.
Кстати, впервые поддержка простых шейдеров появились в 2001 году, когда появилась NVIDIA GeForce 3. До этого освещение тоже делалось, но аппаратными средствами и разработчики особо не могли влиять на результат. Так вот сегодня это самый ресурсоемкий этап, на котором для каждого пикселя нужно просчитать как он отражает, рассеивает и пропускает свет. Как ложатся тени по поверхности модели и прочее. То есть иными словами рассчитывается финальный цвет пикселя.
Каждый объект сцены описывается при помощи нескольких текстур:
Карта нормалей, текстура, в которой хранятся векторы нормалей для каждой точки поверхности. При помощи этих векторов рассчитывается попиксельное освещение.
Карта зеркальности, которая описывает сколько света отражается от поверхности.
Карта шероховатостей (roughness mapbump map), которая описывает микрорельеф поверхности или то, как поверхность будет рассеивать свет.
Альбедо карта, то есть карта диффузии или естественный цвет объекта.
И прочие.
Этап 4. Сохранение
После кучи вычислений при помощи информации из всех вышеперечисленных текстур наступает последний этап. Мы получили финальный цвет пикселя и сохраняем его в видеопамять. А после обработки всей сцены мы уже можем выводить картинку на экран.
Мощность
Все эти вычисления нужно проводить очень быстро и главное параллельно. Например, чтобы вывести 60 раз в секунду 4К-изображение нужно посчитать цвет примерно полумиллиарда пикселей. А если мы хотим 120 FPS — то целый миллиард. Именно поэтому видеокарты отличаются по структуре от центрального процессора.
Центральный процессор заточен под последовательное, но очень быстрое выполнение множества разнообразных вычислений. Поэтому ядер в центральном процессоре мало, но зато они умеют быстро щелкать любые задачи. А вот в GPU вычислительных блоков тысячи, они не умеют максимально быстро выполнять задачи с небольшим количеством данных последовательно как процессор, но очень быстро делают параллельные вычисления с большим количеством данных. Например, NVIDIA GeForce RTX 3090 в пике может делать до 38 триллионов операций с плавающей точкой в секунду.
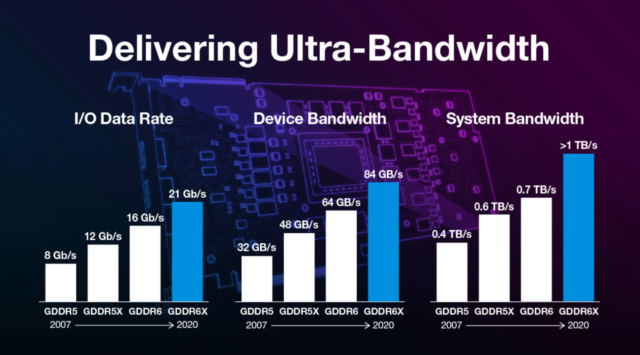
Так как видеокартам нужно постоянно загружать и выгружать огромное количество данных в память, то у них используется и свой тип памяти — GDDR. У неё выше задержки, чем в обычной DDR, поэтому такую память не имеет смысла использовать в качестве оперативной. Но у GDDR существенно выше ширина канала и пропускная способность, которая уже сейчас доходит до 1 ТБ в секунду.
Это позволяет видеокартам обрабатывать сотни миллиардов пикселей в секунду.
CUDA
Вся эта мощь нужна только для того чтобы в игры играть? На самом деле — нет. Видеокарты уже давно используется для профессиональных задач.
Но стало это возможно только в 2006 году, когда вышла карточка GeForce 8800, в которой впервые появились ядра CUDA — Compute Unified Device Architecture. Это унифицированные ядра, которые впервые позволяли использовать видеокарту не только для игр, но и для любых массивных параллельных вычислений: типа рендеринга видео, симуляции воды, дыма, ну или майнинга крипты, если вдруг это еще актуально.
А в 2018 году, произошла другая революция — появилась архитектура Turing, а вместе с ней новые типы ядер и, конечно же, технологии трассировки лучей. Поговорим сначала о ней.
Трассировка лучей
Что такое трассировка лучей? Несмотря, на то что видеокарты за годы своей эволюции обросли поддержкой кучи эффектов. Игры действительно стали выглядеть впечатляюще круто. Но всё равно, остались выглядеть как игры. Почему?
Дело в том, что до появления технологии трассировки лучей, в играх не было настоящего глобального освещения. Оно рассчитывалось для каждого объекта по отдельности, причем поочередно. Соответственно, мы не могли рассчитать как объекты влияют друг на друга, как преломляется и отражается свет между разными объектами. А всё глобальное освещение сцены просто заранее «запекалось» в текстуру в графическом редакторе игры. Есть еще зонды и куча других техник, которые позволяют получить грубую имитацию глобального освещения с кучей недостатков — протеканием света сквозь объекты, повышенными требованиями к объему видеопамяти, отсутствием физики, так как если изменится положение объектов в сцене, то и освещение придется заново считать, а с использованием заранее подготовленных ресурсов — это невозможно.
А вот трассировка лучей впервые позволила, построить освещение по законам природы и сняла кучу ограничений. Ну практически. Как это работает?
Вместо того, чтобы поочередно считать освещение для каждого объекта Сначала выводится вся трехмерная сцена и упаковывается в BVH коробки для ускорения трассировки. После чего из камеры в упакованную 3D-сцену запускается луч и мы смотрим с какой поверхностью он пересечется. А дальше от этой точки строится по одному лучу до каждого источника освещения. Так мы понимаем где свет, а где тень.
А если луч попал на отражающий объект, то строится еще один отраженный луч и так мы можем считать переотражения. Чем больше переотражений мы считаем, тем сложнее просчет, но реалистичнее результат.
Всё практически как в жизни, но для экономии ресурсов, лучи запускаются не от источника света а из камеры. Иначе бы пришлось просчитывать много лучей, которые не попадают в поле зрения игрока, то есть делать бесполезные, отнимающие ресурсы GPU вычисления.
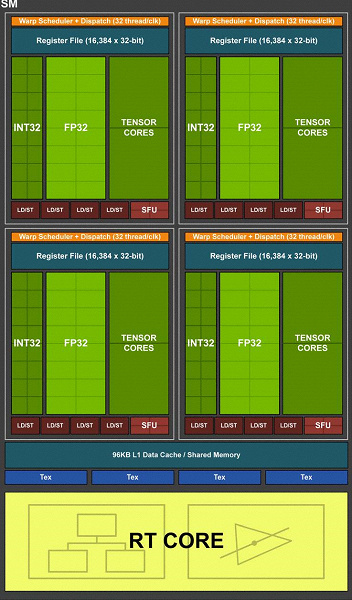
Новые ядра
Для реализации трассировки лучей, помимо ядер CUDA пришлось придумать ядра нового типа. Это RT-ядра, что собственно и значит ядра трассировки лучей и тензорные ядра.
RT-ядра выполняют тот самый поиск пересечений между лучом и полигонами сцены. И делают это очень эффективно для благодаря алгоритму BVH — Bounding Volume Hierarchy.
Суть алгоритма: Каждый полигон вкладывается в несколько коробок разного размера, как в матрешку. И вместо того, чтобы проверять пересечения с каждым полигоном сцены, коих миллионы, сначала проверяется попал ли луч в небольшое количесчтво коробок, в которые упакованы треугольники сцены, На последнем уровне BVH матрешки содержится коробка с несколькими треугольниками сцены. Коробок намного меньше, чем треугольников, поэтому на тестирование сцены уходит намного меньше времени, чем если бы мы перебирали каждый треугольник сцены.
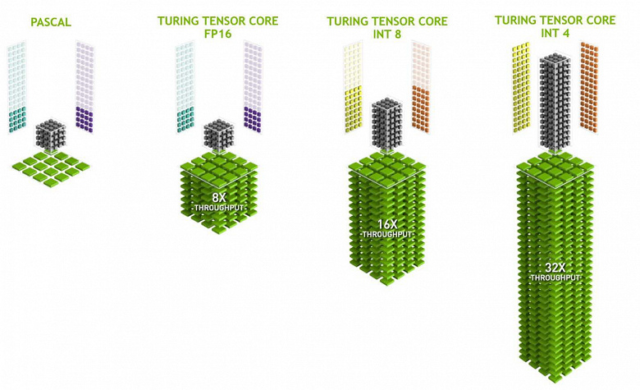
Тензорные ядра — это вообще необычная вещь для видеокарты. Такие ядра используется для операций матричного перемножения. То есть могут умножать много чисел одновременно. Это очень полезно для обучения глубоких нейронных сетей. Поэтому как правило, нейросети сейчас обучают и используют именно на видеокартах.
Но и в играх тензорные ядра имеют высокий вес. Во-первых, очищение рейтрейснутой картинки от шума в профессиональных пакетах с поддержкой OptiX.
Но в первую очередь, для реализации фирменной технологии DLSS — Deep Learning Super Sampling. Это технология сглаживания и апскейлинга картинки при помощи нейросетей. Например, у вас 4K-монитор, но видеокарта не тянет 4К на ультрах. Что в этом случае делает DLSS. Картинка рендерится в более низком разрешении 1440P или 1080P, а потом несколько соседних кадров объединяются нейросетью в новый кадр более высокого разрешенияи. Да так, что часто выглядит даже лучше чем в нативном разрешении. При этом мы получаем огромный прирост фреймрейта.
Многовато технологий! В таком можно и запутаться, поэтому чтобы упорядочить мысли давайте пройдёмся по этапам того как работает видеокарта.
Чем отличаются видеокарты?
Окей, кажется с принципом работы видеокарты разобрались. Теперь давайте поговорим почему одни видеокарты работают быстрее, а другие медленнее.
Во-первых, на скорость и возможности видеокарты влияет поколение. Например, до появления серии GeForce RTX 20-серии вообще не было трассировки лучей и прочих плюшек. Но если говорить о производительности в рамках одного поколения, то нас интересуют 4 параметра:
Количество ядер и прочих исполнительных блоков
Скорость и объём памяти
Частота ядра
Дизайн
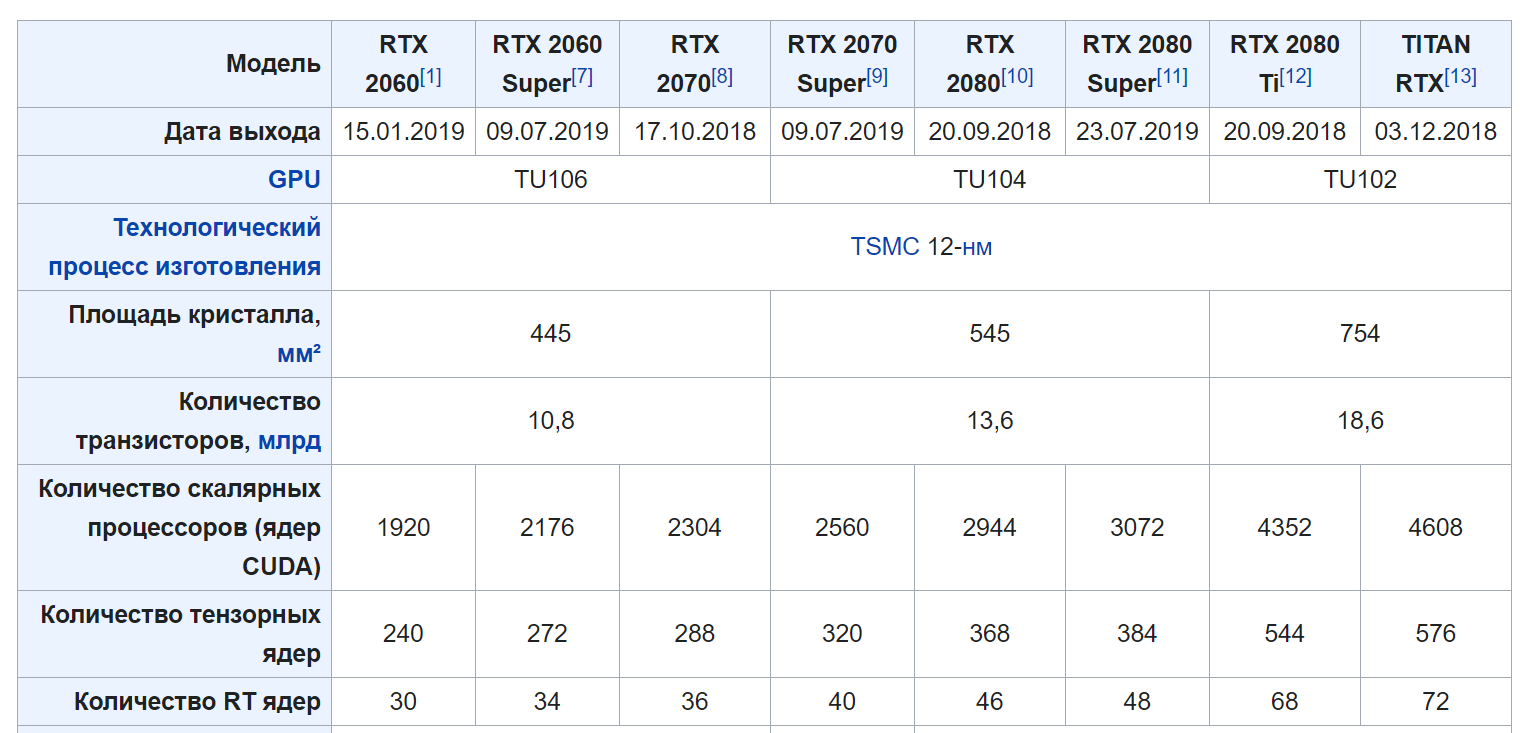
Допустим, сравним 20-ю серию.
В RTX 2060 — 1920 ядер CUDA , а в 2080 Ti — 4352. Соответственно в общих задачах мы можем рассчитывать на производительность примерно в 2 раза выше. С частотой ядра и объёмом памяти думаю тоже всё понятно. Чем больше, тем лучше.
Дизайн
Но причем тут дизайн?
Дело в том, что NVIDIA производит только чипы и показывает референсный дизайн видеокарты. А дальше каждый производитель сам решает какую систему охлаждения поставить и в каком размере сделать видеокарту. Соответственно, чем лучше охлаждение, тем выше будет частота работы, и больше производительность.
Но также под дизайном имеется ввиду формфактор. Дело в том что большие видеокарты, например, просто физически не влезут в ноутбук. А если даже влезут, энергопотребление в них будет запредельным. Поэтому существуют мобильные модификации видеокарт, которые просто распаиваются на материнской плате. Мобильные модификации карточек отличаются сниженными частотами и энергопотреблением.
Существуют две разновидности мобильных дизайнов:
Просто Mobile. Это версии для жирных игровых ноутов. они не сильно отличаются по производительности от десктопных версий. Иногда такие карточки называют Max-P, типа performance. А иногда вообще ничего не приписывают. Но не обольщайтесь в ноутбуке не может стоять не мобильная версия.
А бывает дизайн Max-Q. Такие карточки ставя в тонкие игровые ноуты. В них существенно ниже энергопотребление, но и частоты сильнее порезаны.
RTX 2080 Super
RTX 2080 Super Mobile (Max-P)
RTX 2080 Super Max-Q
CUDA ядра
3072
3072
3072
Частота яда
1650 МГц
1365 МГц
975 МГц
Частота в режиме Boost
1815 МГц
1560 МГц
1230 МГц
Энергопотребление (TDP)
250 Вт
150 Вт
80 Вт
Проверим на практике
Производительность игровых лэптопов приблизилась к десктопной. Но ноутбуки более удобны в силу форм-фактора. GeForce GTX — это ок, нормальный начальный уровень. RTX — оптимальный выбор для любителей игр. Кроме того, RTX GPU — это еще и ускорение более 50 рабочих приложений. Рптимальный выбор для работы и игр. Но хватит теории. Давайте проверим на практике, чем отличаются по производительности разные карточки.
У нас есть 3 ноутбука. Вот с таким железом.
ASUS ROG Zephyrus G15
Ryzen 7 4800HS
NVIDIA GeForce GTX 1650 Ti 4ГБ
ASUS ROG Zephirus DUO
Intel Core i9-10980HK
GeForce RTX 2080 SUPER Max-Q 8ГБ
Во всех трёх вариантах установлены разные процессоры, но они все мощные, поэтому не должны сильно повлиять на результат тестов. По крайней мере бутылочным горлышком они точно не будут.
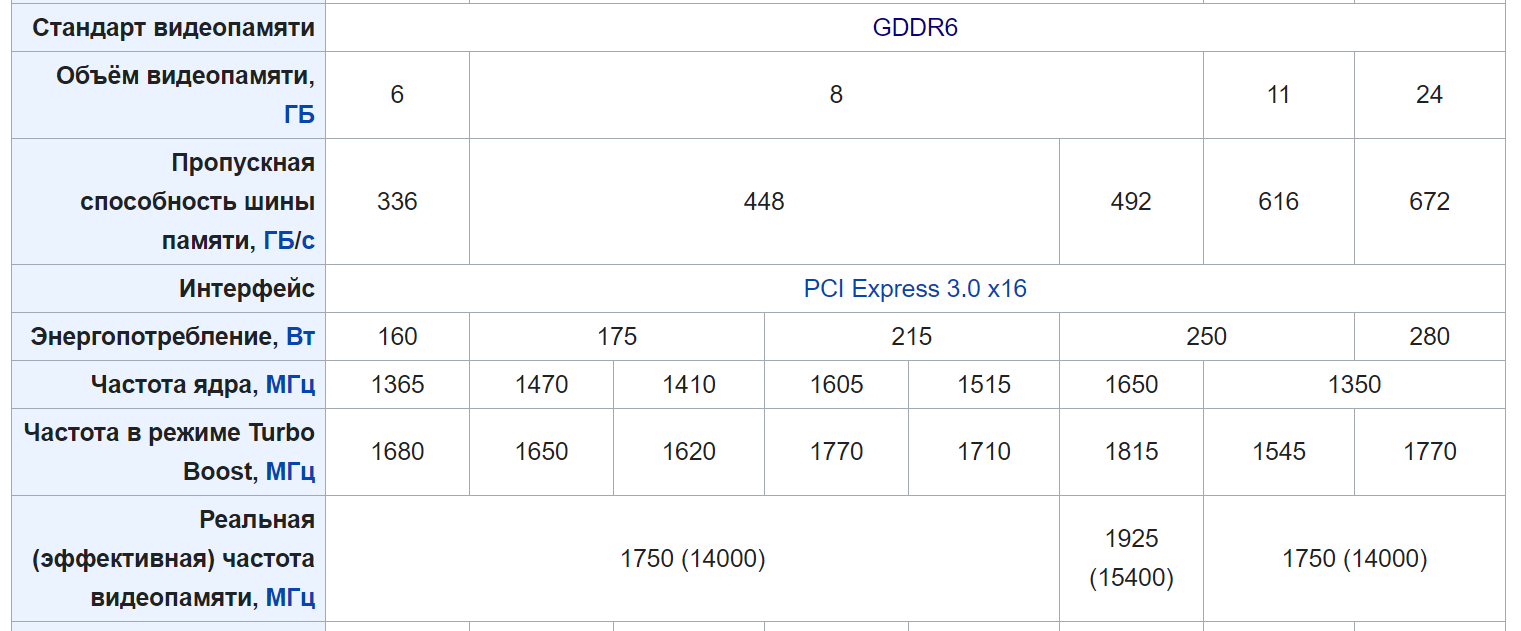
GTX 1650 Ti Mobile
RTX 2060 Max-Q
RTX 2080 Super Max-Q
CUDA ядра
1024
1920
3072
Частота ядра
1350 МГц
975 МГц
975 МГц
Частота в режиме Boost
1485 МГц
1185 МГц
1230 МГц
Тензорные ядра
—
240
384
RT-ядра
—
30
48
Объем видеопамяти
4 ГБ
6 ГБ
8 ГБ
Энергопотребление (TDP)
65 Вт
50 Вт
80 Вт
И, для начала, немного синтетических тестов. Судя по тесту 3DMark Time Spy, 2080 Super в дизайне Max-Q опережает 2060 на 25%, а 1650 Ti на 51%. А значит мы ожидаем, что 2080 будет выдавать примерно в 2 раза больший фреймрейт. Посмотрим так ли это на практике.
GTX 1650 Ti Mobile — 3948 (-51.7%)
RTX 2060 Max-Q — 6090 (-25.5%)
RTX 2080 Super Max-Q — 8170
Тест Cyberpunk 2077
Мы всё проверяли на Cyberpunk 2077 с версией 1.04 на не самой загруженной сцене, в закрытой локации. Тем не менее с наличием экшэна. Все ноутбуки работали в режиме производительности турбо.
Итак, в Cyberpunk 2077 есть 6 стандартных пресетов графики: низкие, средние, высокие, впечатляющие. И еще две настройки с трассировкой лучей: это впечатляющие настройки + среднее качество трассировки или ультра качество. В пресетах с трассировкой сразу же включен DLSS в режиме Авто. Это стоит учитывать.
Итак, на что способны наши видеокарты?
Во-первых, 1650 Ti показала себя очень неплохо, потому, что выдала супер играбельный фреймрейт на высоких настройках графики — стабильные 30+ FPS с редкими просадками до 25. А уж совсем играбельными оказались средние настройки — это уже 35-40 FPS.
Full HD, стандартные настройки
Настройки графики
GTX 1650 Ti Mobile
RTX 2060 Max-Q
RTX 2080 Super Max-Q
Впечатляющее + RT: ультра + DLSS Auto
—
~34 FPS
~ 49 FPS
Впечатляющее + RT: средне + DLSS Auto
—
~ 43 FPS
~ 63 FPS
Впечатляющее
~29 FPS
~48 FPS
~68 FPS
Высокое
~34 FPS
~ 55 FPS
—
Среднее
~38 FPS
~ 65 FPS
—
Низкое
~45 FPS
—
—
В этой карточке нет тензорных и RT-ядер, поэтому трассировка не поддерживается. GeForce GTX — это графика начального уровня. Но на удивление тут работает технология DLSS. Она дает не очень большой прирост, примерно +4 FPS. Но этого вполне достаточно чтобы комфортно играть на высоких настройках в разрешении FHD. Считаю, это победа.
GTX 1650 Ti Mobile FHD
Настройки графики 1080P
GTX 1650 Ti Mobile
Впечатляющее + RT: ультра + DLSS Auto
—
Впечатляющее + RT: средне + DLSS Auto
—
Впечатляющее
~29 FPS
Высокое
~34 FPS
Среднее
~38 FPS
Низкое
~43 FPS
Впечатляющее + DLSS Качество
~32 FPS
Впечатляющее + DLSS Ультрапроизводительность
~40 FPS
Высокое + DLSS Сбалансированное
~38 FPS
Среднее + DLSS Сбалансированное
~42 FPS
На 2060 можно играть вообще на всех настройках. На ультрах с рей трейсингом получаем стабильные 30 кадров. А на средних настройках уже больше 60 FPS без просадок.
А при включении DLSS мы получаем огромный прирост. Тут стабильные 60 кадров на впечатляющих настройках, но без трассировки лучей.
RTX 2060 Max-Q FHD
Настройки графики
RTX 2080 Super Max-Q
Впечатляющее + RT: ультра (без DLSS)
~8 FPS
Впечатляющее + RT: ультра + DLSS Auto
~47 FPS
Впечатляющее + RT: средне + DLSS Auto
~ 60 FPS
Впечатляющее
~ 21 FPS
RTX 2080 вообще особо не напрягается в разрешении FHD и выдает 60 FPS почти на максимальных настройках, а если отключить трассировку лучей и того выше. RTX 2080 и даже если отключить DLSS vs получаем играбельный фремрейт в районе 40 FPS на среднем качестве трассировки лучей.
RTX 2080 Super Max-Q FHD
Настройки графики
RTX 2080 Super Max-Q
Впечатляющее + RT: ультра (без DLSS)
~8 FPS
Впечатляющее + RT: ультра + DLSS Auto
~47 FPS
Впечатляющее + RT: средне + DLSS Auto
~ 60 FPS
Впечатляющее
~ 21 FPS
Поэтому для такой мощной карточки мы также запустили игру в 4K-разрешении и вот тут DLSS выступил во всейкрасе. Потому как без него мы получили слайдшоу меньше 10 FPS. А вот с DLSS 60 стабильных кадров на средних настройках трассировки. Отсюда делаем вывод что без DLSS в 4К-разрешении вообще играть нельзя.
RTX 2080 Super Max-Q 4K
Настройки графики
RTX 2080 Super Max-Q
Впечатляющее + RT: ультра (без DLSS)
~8 FPS
Впечатляющее + RT: ультра + DLSS Auto
~47 FPS
Впечатляющее + RT: средне + DLSS Auto
~ 60 FPS
Впечатляющее
~ 21 FPS
Итоги
Что в итоге? Несколько выводов. Во-первых Cyberpunk 2077 для ПК вполне играбелен даже на ноутбуках на железе позапрошлого поколения. Во-вторых, DLSS очень крутая технология. Раньше нам приходилось понижать разрешение или отрубать эффекты, чтобы поднять фреймрейт. Теперь же можно просто поменять режим DLSS и радоваться.
А сегодняшний тест мы подготовили в том числе благодаря магазину Ситилинк. Главные преимущества Ситилинк – приятные цены и широкий ассортимент. Выбирайте свой ноутбук мечты на базе Nvidia на Ситилинк.
NVIDIA объявила о покупке Arm за 40 миллиардов долларов
Слухи об этой сделке ходили довольно давно, но поскольку речь идёт о миллиардах долларов, она должна пройти еще несколько инстанций по регулированию.
Шутка про невидимую руку капитализма может войти в моду. Можно сказать, что у NVIDIA теперь появилась рука, ведь сегодня компания объявила о приобретении Arm за 40 миллиардов долларов.
Основная идея покупки заключается в развитии экосистемных решений с искусственным интеллектом. При этом Arm останется работать в Кембридже, где создаст центр исследования и обучения ИИ, а заодно создаст суперкомпьютер на базе решений обоих компаний.
При этом NVIDIA будет сохранять нейтралитет, а Arm продолжит модель лицензирования процессоров.
Важно заметить, что совместная деятельность компаний будет направлена в первую очередь не на B2C-сегмент, а на B2D, ведь в планах NVIDIA создание мощных дата-центров для клиентов, которые будут сочетать в себе решения и идеи NVIDIA и Arm.
В рамках продажи бывший владелец Arm — японский Softbank получит 21,5 миллиард долларов в виде акций NVIDIA, а также 12 миллиардов кэшем, включая 2 миллиарда подписного бонуса. Полная сделка займёт 18 месяцев в случае ее принятия со стороны Великобритании, Китая, Европейского Союза и США.
Как работает процессор и что важно знать?
Разбираемся в том, как работают процессоры Intel, какие фишки в них есть и каким образом они построены. Как всегда — доступно и понятно!
Процессор состоит из миллиардов транзисторов сопоставимых по размеру с молекулой ДНК. Действительно размер молекулы ДНК составляет 10 нм. И это не какая-то фантастика! Каждый день процессоры помогают нам решать повседневные задачи. Но вы когда-нибудь задумывались, как они это делают? И как вообще люди заставили кусок кремния производить за них вычисления?
Сегодня мы разберем базовые элементы процессора и на практике проверим за что они отвечают. В этом нам поможет красавец-ноутбук — Acer Swift 7 с процессором Intel на борту.
Ядро процессора
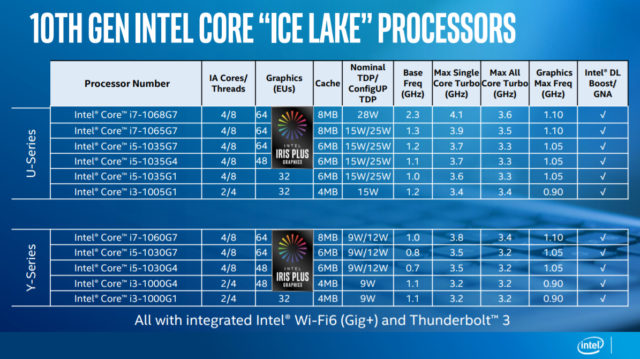
Модель нашего процессора i7-1065G7. Он четырёхядерный и ядра очень хорошо видны на фотографии.
Каждое ядро процессора содержит в себе все необходимые элементы для вычислений. Чем больше ядер, тем больше параллельных вычислений процессор может выполнять. Это полезно для многозадачности и некоторых ресурсоемких задач типа 3D-рендеринга.
Например, для теста мы одновременно запустили четыре 4К-видео. Нагрузка на ядра рспределяется более менее равномерно: мы загрузили процессор на 68%. В итоге больше всего пришлось переживать за то хватит ли Интернет-канала. Современные процессоры отлично справляются с многозадачностью.
Почему это важно? Чтобы ответить на этот вопрос, давайте разберемся — как же работает ядро?
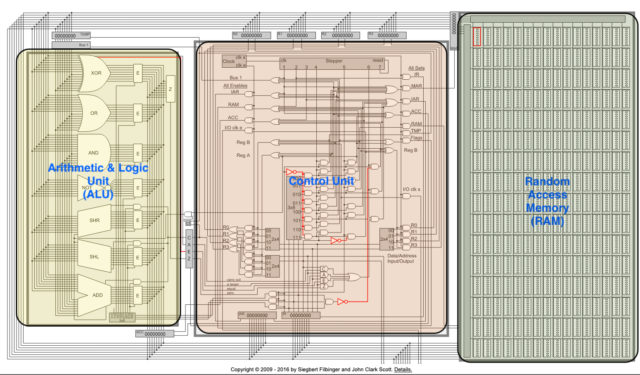
По своей сути ядро — это огромный конвейер по преобразованию данных. На входе загружаем одно, на выходе получаем другое. В его основе лежат транзисторы. Это миниатюрные переключатели, которые могут быть в всего в двух состояниях: пропускать ток или нет. Эти состояния компьютер интерпретирует как нули и единицы, поэтому все данные в компьютере хранятся в двоичном коде.
Можно сказать, что компоненты внутри компьютера общаются между собой при помощи подобия Азбуки Морзе, которая тоже является примером двоичного кода. Только компьютер отстукивает нам не точки и тире, а нолики и единички. Казалось бы, вот есть какой-то переключатель, и что с ним можно сделать? Оказывается очень многое!
Если по хитрому соединить несколько транзисторов между собой, то можно создать логические вентили. Это такие аналоговые эквиваленты функции “если то”, ну как в Excel. Если на входе по обоим проводам течет ток, то на выходе тоже будет течь или не будет или наоборот, вариантов не так уж и много — всего семь штук.
Но дальше комбинируя вентили между собой в сложные аналоговые схемы, мы заставить процессор делать разные преобразования: складывать, умножать, сверять и прочее.
Поэтому ядро процессора состоит из множества очень сложных блоков, каждый из которых может сделать с вашими данными что-то своё.
Прям как большой многостаночный завод, мы загружаем в него сырье — наши данные. Потом всё распределяем по станкам и на выходе получаем результат.
Но как процессор поймёт, что именно нужно делать с данными? Для этого помимо данных, мы должны загрузить инструкции. Это такие команды, которые говорят процессору:
это надо сложить,
это перемножить,
это просто куда-нибудь отправить.
Инструкций очень много и для каждого типа процессора они свои. Например, в мобильных процессорах используется более простой сокращённый набор инструкций RISC — reduced instruction set computer.
А в ПК инструкции посложнее: CISC — complex instruction set computer.
Поэтому программы с мобильников не запускаются на компах и наоборот, процессоры просто не понимают их команд. Но чтобы получить от процессора результат недостаточно сказать — вот тебе данные, делай то-то. Нужно в первую очередь сказать, откуда брать эти данные и куда их, собственно, потом отдавать. Поэтому помимо данных и инструкций в процессор загружаются адреса.
Память
Для выполнения команды ядру нужно минимум два адреса: откуда взять исходные данные и куда их положить.
Всю необходимую информацию, то есть данные, инструкции и адреса процессор берёт из оперативной памяти. Оперативка очень быстрая, но современные процессоры быстрее. Поэтому чтобы сократить простои, внутри процессора всегда есть кэш память. На фото кэш — это зелёные блоки. Как правило ставят кэш трёх уровней, и в редких случаях четырёх.
Самая быстрая память — это кэш первого уровня, обозначается как L1 cache. Обычно он всего несколько десятков килобайт. Дальше идёт L2 кэш он уже может быть 0,5-1 мб. А кэш третьего уровня может достигать размера в несколько мегабайт.
Правило тут простое. Чем больше кэша, тем меньше процессор будет обращаться к оперативной памяти, а значит меньше простаивать.
В нашем процессоре кэша целых 8 мб, это неплохо.
Думаю тут всё понятно, погнали дальше.
Тактовая частота
Если бы данные в процессор поступали хаотично, можно было бы легко запутаться. Поэтому в каждом процессоре есть свой дирижёр, который называется тактовый генератор. Он подает электрические импульсы с определенной частотой, которая называется тактовой частотой. Как вы понимаете, чем выше тактовая частота, тем быстрее работает процессор.
Занимательный факт. По-английски, тактовая частота — это clock speed. Это можно сказать буквальный термин. В компьютерах установлен реальный кристалл кварца, который вибрирует с определенной частотой. Прямо как в наручных кварцевых часах кристалл отсчитывает секунды, так и в компьютерах кристалл отсчитывает такты.
Обычно частота кристалла где-то в районе 100 МГц, но современные процессоры работают существенно быстрее, поэтому сигнал проходит через специальные множители. И так получается итоговая частота.
Современные процессоры умеют варьировать частоту в зависимости от сложности задачи. Например, если мы ничего не делаем и наш процессор работает на частоте 1,3 ГГц — это называется базовой частотой. Но, к примеру, если архивируем папку и мы видим как частота сразу увеличивается. Процессор переходит в турбо-режим, и может разогнаться аж до 3,9 ГГц. Такой подход позволяет экономить энергию, когда процессор простаивает и лишний раз не нагреваться.
А еще благодаря технологии Intel Hyper-threading, каждое ядро делится на два логических и мы получаем 8 независимых потоков данных, которые одновременно может обрабатывать компьютер.
Что прикольно, в новых процессорах Intel скорость частот регулирует нейросеть. Это позволяет дольше держать турбо-частоты при том же энергопотреблении.
Вычислительный конвейер
Так как ядро процессора — это конвейер, все операции через стандартные этапы. Их всего четыре штуки и они очень простые. По-английски называются: Fetch, Decode, Execute, Write-back.
Fetch — получение
Decode — раскодирование
Execute — выполнение
Write-back — запись результата
Сначала задача загружается, потом раскодируется, потом выполняется и, наконец, куда-то записывается результат.
Чем больше инструкций можно будет загрузить в конвейер и чем меньше он будет простаивать, тем в итоге будет быстрее работать компьютер.
Предсказатель переходов
Чтобы конвейер не переставал работать, инженеры придумали массу всяких хитростей. Например, такую штуку как предсказатель переходов. Это специальный алгоритм, который не дожидаясь пока в процессор поступит следующая инструкция её предугадать. То есть это такой маленький встроенный оракул. Вы только дали какую-то задачу, а она уже сделана.
Такой механизм позволяет многократно ускорить систему в массе сценариев. Но и цена ошибки велика, поэтому инженеры постоянно оптимизируют этот алгоритм.
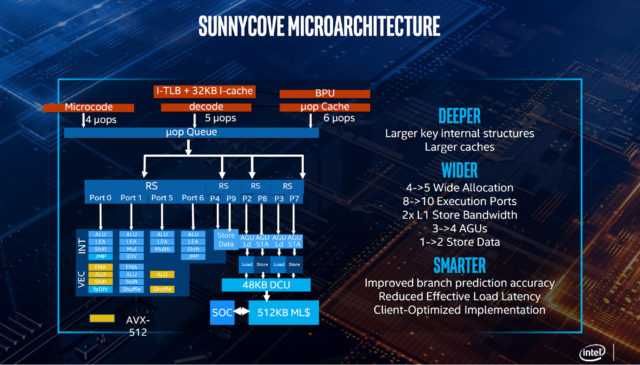
Микроархитектура
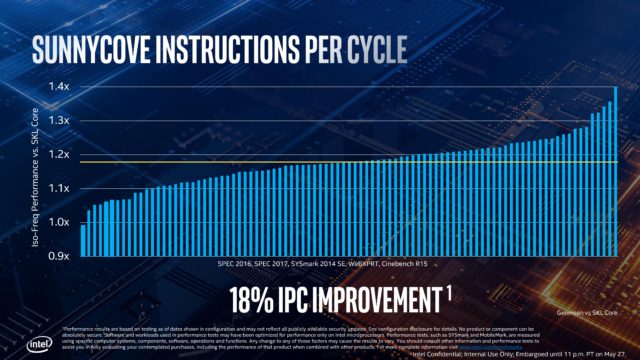
Все компоненты ядра, как там всё организовано, всё это называется микроархитектурой. Чем грамотнее спроектирована микроархитектура, тем эффективнее работает конвейер. И тем больше инструкций за такт может выполнить процессор. Этот показатель называется IPC — Instruction per Cycle.
А это значит, если два процессора будут работать на одинаковой тактовой частоте, победит тот процессор, у которого выше IPC.
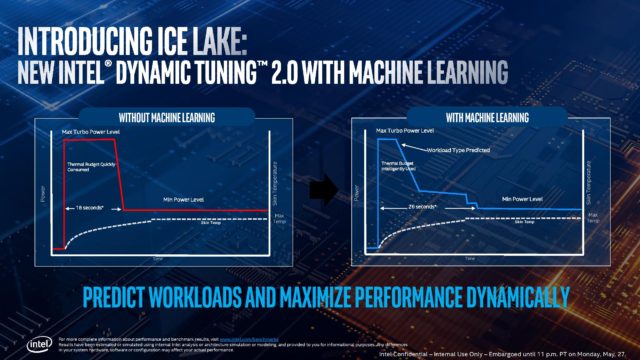
В процессорах Ice Lake, Intel использует новую архитектуру впервые с 2015 года. Она называется Sunny Cove.
Показатель IPC в новой архитектуре аж на 18% на выше чем в предыдущей. Это большой скачок. Поэтому при выборе процессора обращаете внимание, на поколение.
Система на чипе
Естественно, современные процессоры — это не только центральный процессор. Это целые системы на чипе с множеством различных модулей.
ГП
В новый Intel больше всего места занимает графический процессор. Он работает по таким же принципам, что и центральный процессор. В нём тоже есть ядра, кэш, он тоже выполняет инструкции. Но в отличие от центрального процессора, он заточен под только под одну задачу: отрисовывать пиксели на экране.
Поэтому в графический процессорах ядра устроены сильно проще. Поэтому их даже называют не ядрами, а исполнительными блоками. Чем больше исполнительных блоков тем лучше.
В десятом поколении графика бывает нескольких типов от G1 до G7. Это указывается в названии процессора.
А исполнительных блоков бывает от 32 до 64. В прошлом поколении самая производительная графика была всего с 24 блоками.
Также для графики очень важна скорость оперативки. Поэтому в новые Intel завезли поддержку скоростной памяти DDR4 с частотой 3200 и LPDDR4 с частотой 3733 МГц.
У нас на обзоре ноутбук как раз с самой топовой графикой G7. Поэтому, давайте проверим на что она способна! Мы проверили его в играх: CS:GO, Dota 2 и Doom Eternal.
Что удобно — Intel сделали портал gameplay.intel.com, где по модели процессора можно найти оптимальные настройки для большинства игр.
В целом, в Full HD разрешении можно комфортно играть в большинство игр прямо на встроенной графике.
Thunderbolt
Но есть в этом процессоре и вишенка на торте — это интерфейс Thunderbolt. Контроллер интерфейса расположен прямо на основном кристалле, вот тут.
Такое решение позволяет не только экономить место на материнской плате, но и существенно сократить задержки. Проверим это на практике.
Подключим через Thunderbolt внешнюю видеокарту и монитор. И запустим те же игры. Теперь у нас уровень производительности ноутбука сопоставим с мощным игровым ПК.
Но на этом приколюхи с Thunderbolt не заканчиваются. К примеру, мы можем подключить SSD-диск к монитору. И всего лишь при помощи одного разъёма на ноуте мы получаем мощный комп для игр, монтажа и вообще любых ресурсоемких задач.
Мы запустили тест Crystalmark. Результаты вы видите сами.
Но преимущества Thunderbolt на этом не заканчиваются. Через этот интерфейс мы можем подключить eGPU, монитор, и тот же SSD и всё это через один кабель, подключенный к компу.
Надеюсь, мы помогли вам лучше разобраться в том, как работает процессор и за что отвечают его компоненты.