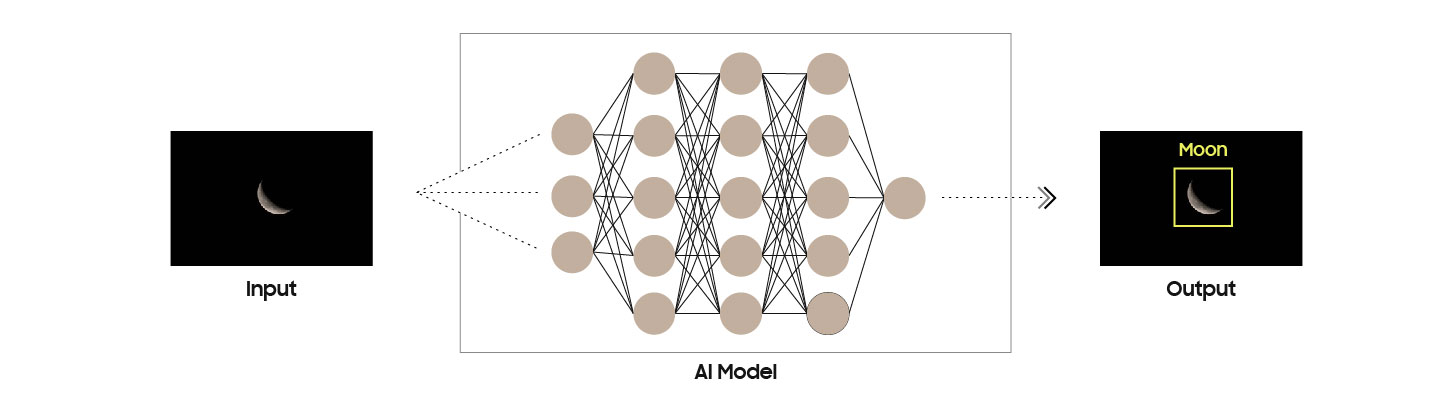
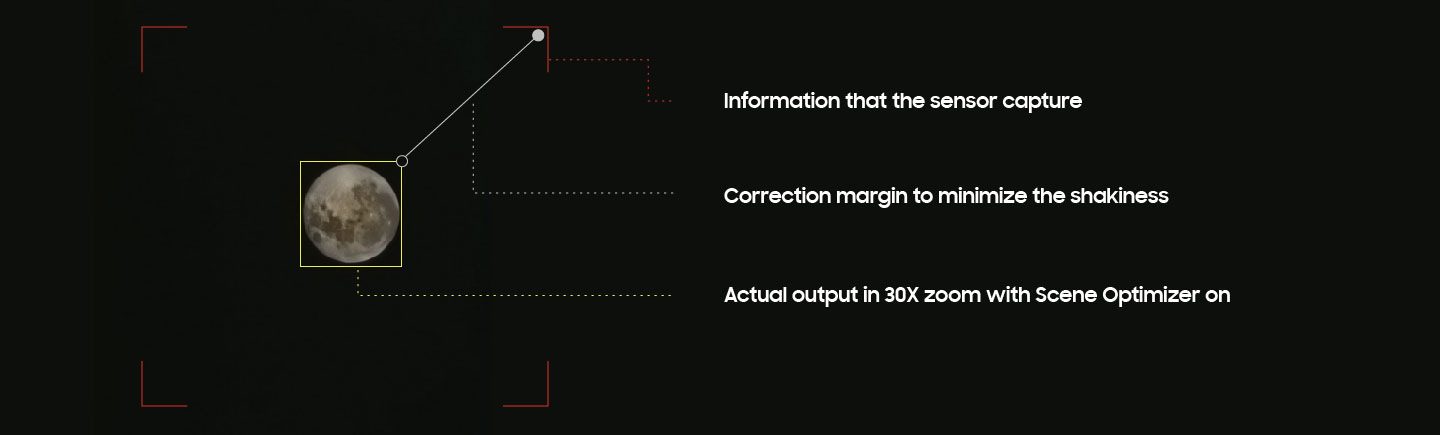
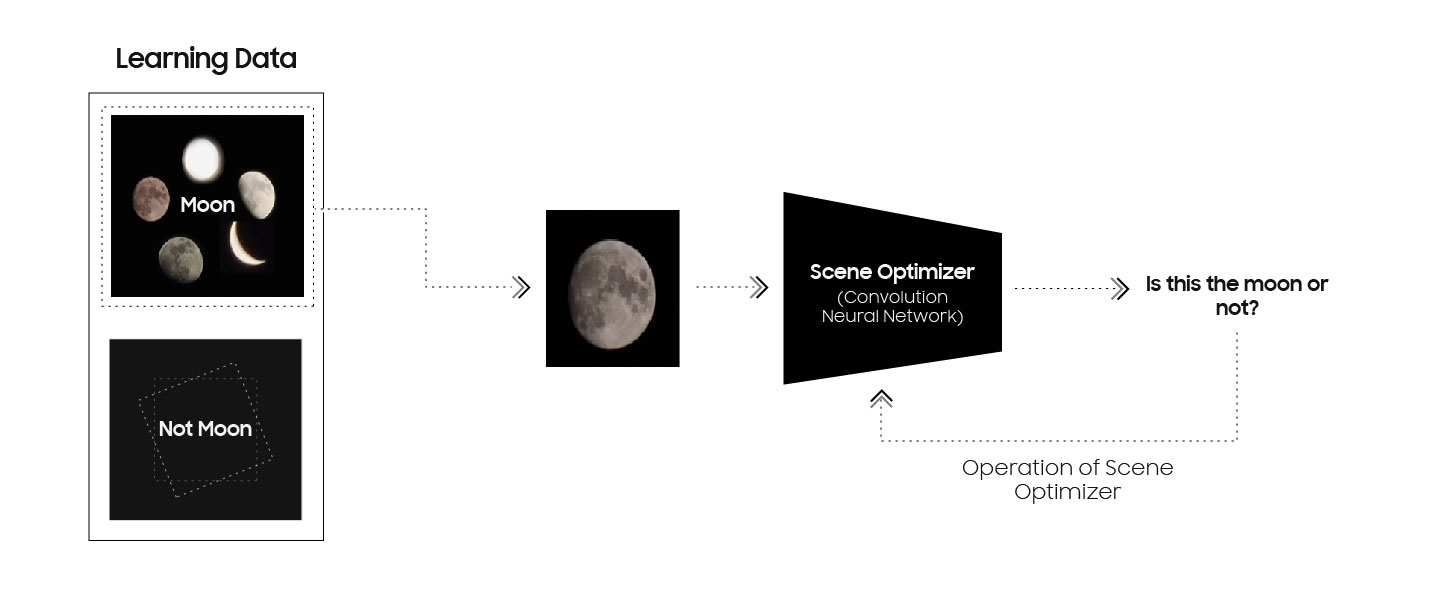
Мы все чаще слышим про то, как нейронки прокачивают камеры наших смартфонов, да и не только камеры — голосовые ассистенты, также они уже пишут музыку и рисуют картины, кто-то это называет ИИ, а еще есть машинное обучение и глубокое обучение! Признайтесь, вы тоже до сих пор не улавливаете разницы между всеми этими понятиями. Это не дело в двадцать первом-то веке! Чем же они отличаются друг от друга? И кто из них будущий SkyNet, Altron или Jarvis? Сейчас мы разложим все по полочкам.
https://youtu.be/tDyDWVqBw5s
Перед тем как погрузиться в будущее, заглянем в прошлое!
В середине XX века, когда появились первые компьютеры, впервые в истории человечества вычислительные возможности машин стали приближаться к человеческим.
- Z1. Германия
- ENIAC (Electronic Numerical Integrator and Computer). США
- ASCC (Automatic Sequence Controlled Calculator). США
Поэтому в учёном сообществе возник справедливый вопрос: а каковы рамки возможностей компьютеров, есть ли эти рамки вообще и достигнут ли машины уровня развития человека? Именно тогда и зародился термин Искусственный Интеллект.
В 1943 году американские ученые Уоррен Мак-Каллок и Уолтер Питтс в своей статье «Логическое исчисление идей, относящихся к нервной активности» предложили понятие искусственной нейронной сети, имитирующей реальную сеть нейронов, и первую модель искусственного нейрона.
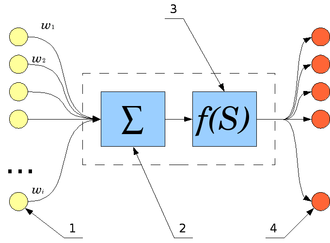
Схема устройства нейрона
А в 1958 году американский нейрофизиолог Фрэнк Розенблатт предложил схему устройства, математически моделирующего процесс человеческого восприятия, и назвал его «перцептроном», что, собственно, стало прообразом нынешних нейросетей.
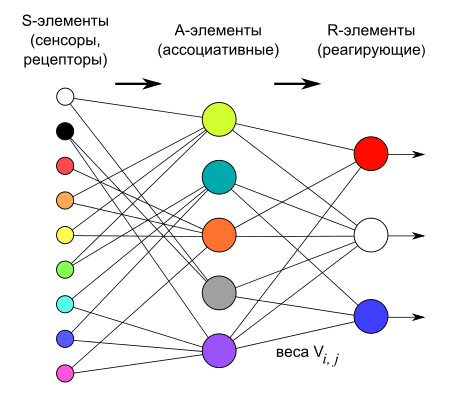
Логическая схема перцептрона с тремя выходами
А за несколько лет до этого, в 1950 году английский учёный Алан Тьюринг, пишет статью с громким названием «Может ли машина мыслить?». В ней он описал процедуру, с помощью которой можно будет определить момент, когда машина сравняется в плане разумности с человеком. Эта процедура сегодня носит название теста Тьюринга, о котором мы уже рассказывали ранее. Но вернемся к началу нашего повествования и ответим на вопрос: что же всё-таки такое “искусственный интеллект”?
Что такое ИИ?

Определений данному понятию существует большое множество, но все они сходятся в одном.
ИИ — это такая искусственно созданная система, которая способна имитировать интеллектуальную и творческую деятельность человека.
Причем интеллектуальная деятельность — это не просто математические расчеты, это деятельность, направленная на создание нематериальных вещей в сфере науки, искусства, литературы, а также в других творческих сферах, обучение, принятие решений, определение выводов и многое другое.
Естественно, обычный компьютер не способен написать картину, музыку или книгу. Для этого ему необходим интеллект — искуственный интеллект!
Но что может современный ИИ? Как можно оценить его интеллектуальные способности?
Чтобы это понять системы искусственного интеллекта можно разделить на три группы:
- слабый (или ограниченный) искусственный интеллект;
- общий искусственный интеллект;
- сильный (или сверхразумный) искусственный интеллект.
Давайте разберемся с каждой по порядку.
Слабый ИИ
ИИ считают слабым, когда машина может справляться только с ограниченным набором отдельных задач лучше человека. Именно на данной стадии сейчас находится тот ИИ, с которым мы с вами сталкиваемся повседневно.
Примеров тут множество. Это ИИ в компьютерных играх — враги умнеют постоянно, вспомните тех же боссов в играх серии Dark Souls. Да и в повседневной жизни, отвечая на письмо в Gmail именно ИИ предлагает вам варианты ответов.

Конечно вряд ли такой ИИ способен на порабощение человечества. Но все же он уже может превзойти человека — к примеру, еще в далеком 1997 году машина Deep Blue от компании IBM сумела обыграть мирового чемпиона по шахматам — Гарри Каспарова.
Общий ИИ
Следующая стадия развития ИИ — это общий ИИ, когда компьютер может решить любую интеллектуальную задачу так же хорошо, как и человек.
Представьте себе, что компьютер способен написать картину не хуже Ван Гога, поболтать с вами по душам, сочинить песню, попадающие в мировые чарты, договориться с начальником о повышении или даже создать новую научную теорию!
К созданию общего ИИ стремятся сегодня ученые всего мира и в скором будущем нам, возможно, удастся узнать, что это такое, своими собственными глазами.
Уже сейчас Google Assistant может забронировать столик, общаясь по телефону с администратором (Google Duplex).
Еще в 2016 году самообучающийся твиттер-бот Тэй с ИИ, созданный компанией Microsoft, менее чем через сутки после запуска научился ругаться и отпускать расистские замечания, в связи с чем был закрыт своим же создателем.
А на последнем Google I/O нам показали проект LaMDA, с помощью которого можно поговорить, например, с планетой или с бумажным самолетом. За последнего, конечно же, будет отвечать ИИ.

Чего только стоит нашумевшая своим выходом осенью 2020 года нейросеть GPT-3 от OpenAI, которая откровенничала в эссе для издания The Guardian:
«Я знаю, что мой мозг — это не «чувствующий мозг». Но он может принимать рациональные, логические решения. Я научилась всему, что я знаю, просто читая интернет, и теперь могу написать эту колонку».

Данная нейросеть выполняет функцию предсказания следующего слова или его части, ориентируясь на предшествующие, а также способна писать логически связные тексты длиной аж в несколько страниц!
А совсем недавно, летом 2021 года, на базе GPT-3 был создан GitHub Copilot от GitHub и OpenAI, представляющий из себя ИИ-помощника для автозаполнения программного кода.
Можно сказать — это первый шаг на пути создания машин, способных порождать себе подобных…
Окей, закрепили! Общий ИИ — это компьютер который может успешно имитировать мышление человека, но не более того…
Интересно, а будет ли такой ИИ способен к переживаниям, сочувствию, к душевным травмам? В идеале — да, но пока что сложновато представить себе компьютер на приеме у психолога. Казалось бы, что может быть еще круче, вот он киберпанк, андроиды как люди, что же дальше?
Сильный ИИ
Дальше — вершина эволюции ИИ или сильный ИИ.
Такая машина должна выполнять абсолютно все задачи интеллектуального и творческого характера лучше, чем человек. То есть во всем его превосходить.
Это самый настоящий ночной кошмар конспирологов, ведь никто не знает, насколько дружелюбными будут такие машины. Но, к счастью, это пока что лишь разговор о далеком будущем. Или не таком уж далеком?
Создание сильного ИИ может стать главным поворотным моментом в истории человечества. Идея заключается в том, что если машины окажутся способны выполнять широкий спектр задач лучше, чем люди, то создание еще более способных машин станет для них лишь вопросом времени.
В такой ситуации произойдет “интеллектуальный прорыв”: машины будут бесконечно совершенствоваться по сравнению с теми, что были раньше, а их возможности будут расти в постоянно ускоряющемся потоке самосовершенствования.
Считается, что этот процесс приведет к появлению машин со “сверхразумом”. Такой необратимый процесс носит название теории «технологической сингулярности». Такие машины станут “последним изобретением, которое придется породить человеку”, писал оксфордский математик Ирвинг Джон Гуд, представивший возможность такого интеллектуального прорыва. Невольно вспоминаются сцены из серии фильмов “Терминатор” Джеймса Кэмерона.
Что такое машинное обучение?
Ну хорошо, с ИИ мы вроде бы разобрались. А что же тогда такое машинное обучение и как эти понятия связаны?
Напомним, что ИИ — это самый общий термин, включающий в себя все остальные понятия.
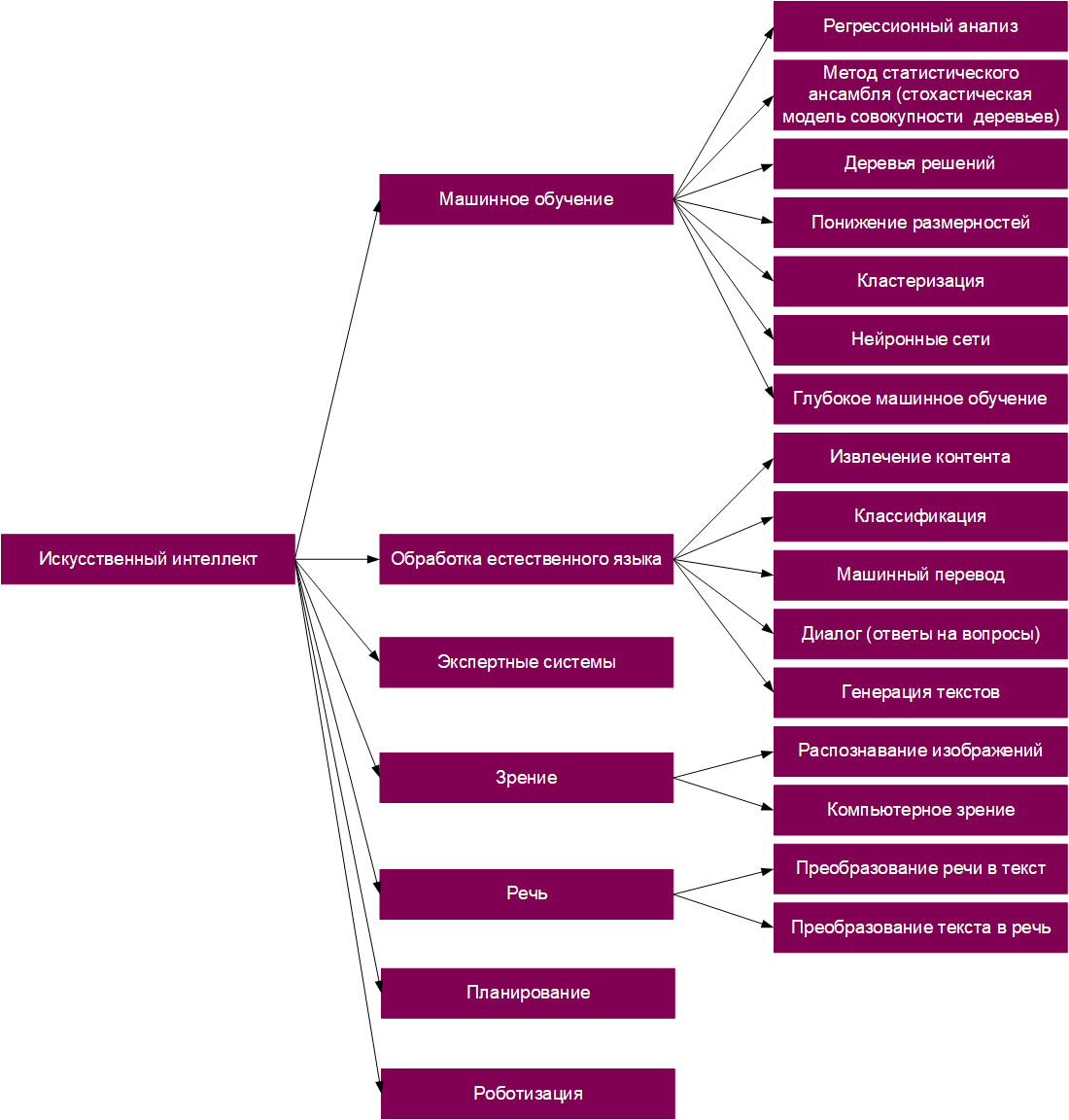
Для простоты ИИ можно представить как своеобразную матрешку. Самая крупная кукла — понятие ИИ в целом. Следующая кукла чуть поменьше — это машинное обучение. Внутри него кроется еще одна маленькая куколка — всеми любимые нейронные сети, а внутри них — еще одна! Это глубокое обучение, о котором мы поговорим чуть позже.
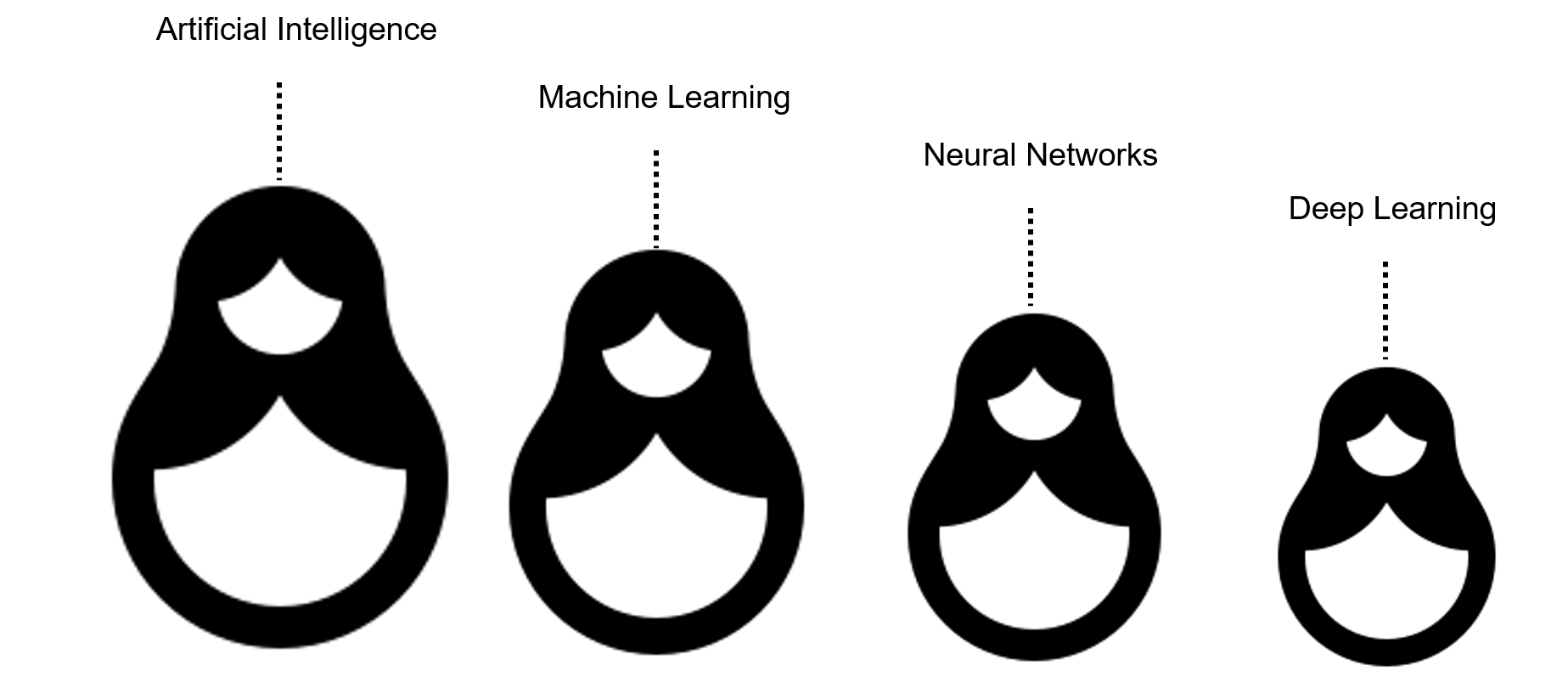
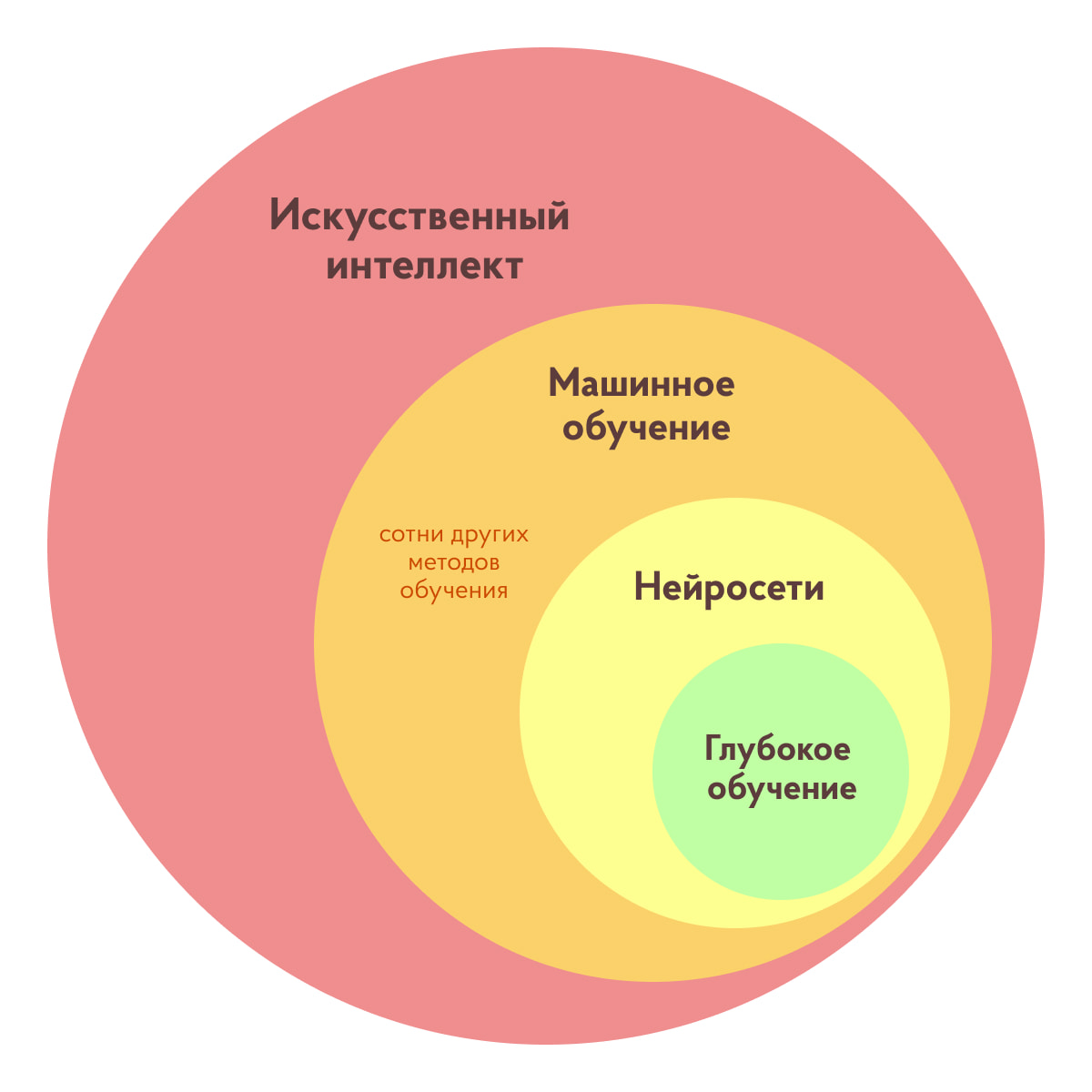
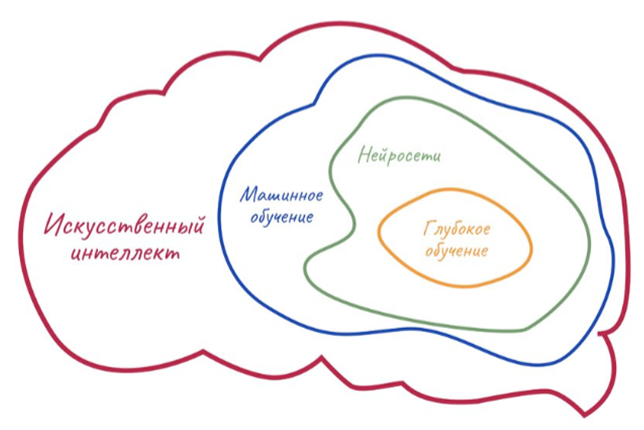
Как видите, машинное обучение является всего лишь одной из отраслей применения ИИ. И что же оно из себя представляет?
Попробуйте вспомнить, как вы освоили чтение. Понятное дело, что вы не садились изучать орфографию и грамматику, прежде чем прочесть свою первую книгу. Лишь зная алфавит и умея читать по слогам, сперва вы читали простые книги, но со временем их сложность постепенно возрастала.
На самом деле, вы неосознанно изучили базовые правила орфографии и грамматики и даже исключения, но именно в процессе чтения. Иными словами, вы обработали много данных и научились на них. Перенося такой подход к освоению навыков на ИИ, становится понятным, что машинное обучение — это имитация того, как учится человек.
Но как это можно реализовать?
Всё просто: необходимо лишь написать алгоритмы, которые будут способны к самообучению, к классификации и оценке данных, к выбору наиболее подходящих решений.
Снабдите алгоритм большим количеством данных о письмах в электронной почте, укажите, какие из них являются спамом, и дайте ему понять, что именно говорит о мошенничестве (наличие ссылок, каких-то ключевых слов и т.п.), чтобы он научился самостоятельно отсеивать потенциально опасные “конвертики”. Сейчас такой алгоритм уже реализован абсолютно во всех электронных ящиках.
У вас ведь было такое, когда письма по ошибке попадают в папку “спам”? Очевидно, что модель не идеальна.
При этом у машинного обучения есть много разных алгоритмов: линейная и логистическая регрессии, система рекомендаций, дерево решений и случайный лес, сигмоида, метод опорных векторов и так далее, и тому подобное.
По мере совершенствования этих алгоритмов они могли бы решить многие задачи. Но некоторые вещи, которые довольно просты для людей (например, распознавание объектов на фото, речи или рукописного ввода), все еще трудны для машин.
Но если машинное обучение — это подражание тому, как люди учатся, почему бы не пройти весь путь и не попытаться имитировать человеческий мозг? Эта идея и лежит в основе нейронных сетей!
Нейронные сети
Что же такое нейронка или искусственная нейронная сеть? Говоря по простому это один из способов машинного обучения!
Или правильнее — это разновидность алгоритмов машинного обучения, некая математическая модель, построенная по принципу организации и функционирования биологических нейронных сетей, то есть сетей нервных клеток живого организма. Некая цифровая модель нейронов нашего мозга. Как работает нейросеть мы уже рассказывали в другом материале.
Но все-таки для дальнейшего понимания коротко расскажем, как устроена нейронка.
Возьмём, к примеру, перцептрон — простейшую нейронную сеть, о которой мы говорили в начале. Она состоит из трёх слоев нейронов: входной слой, скрытый слой и выходной слой. Данные входят в сеть на первом слое, на скрытом слое они обрабатываются, а на выходном слое выводятся в нужном виде.
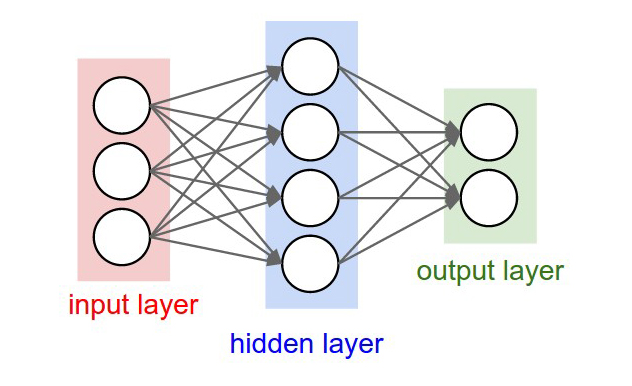
Каждый искусственный нейрон в сети имитирует работу реальных биологических нейронов и представляет собой некоторую нелинейную функцию. А если по-простому — каждый нейрон — это ячейка, которая хранит в себе какой-то ограниченный диапазон значений.
Но обычно тремя слоями все не ограничивается — в большинстве нейросетей присутствует более одного скрытого слоя, а механизм принятия решений в них, мягко говоря, неочевиден. Можно сказать, это как черный ящик. Такие сети называют глубинными нейронными сетями.
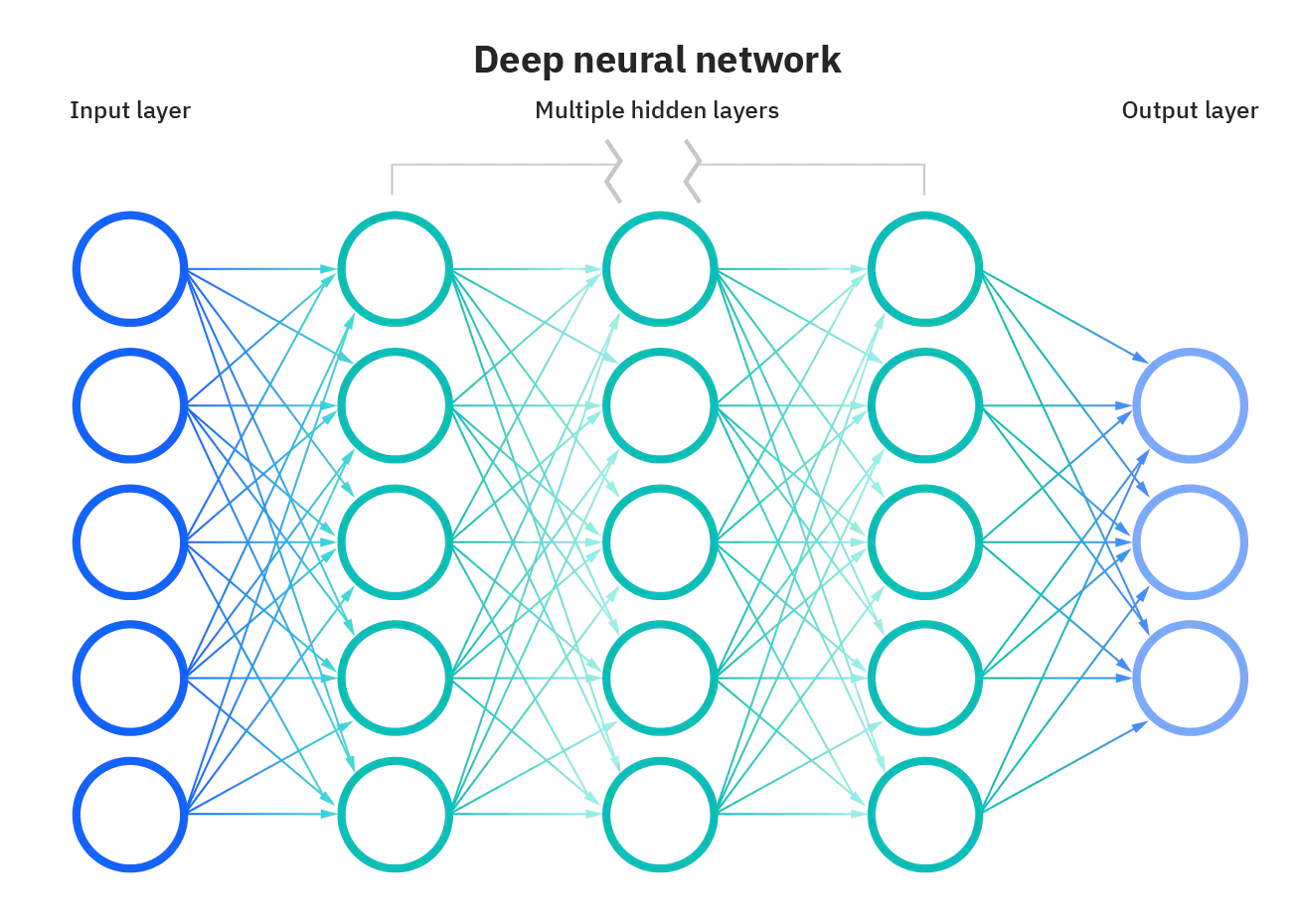
Зачем же нужны такие сложные и запутанные структуры и в чем их ключевая особенность?
У нас в мозгу реальные нейроны примерно таким же образом связаны между собой с помощью специальных синаптических связей.
Только в отличие от компьютерных нейросетей в мозге человека (только представьте себе!) порядка 86 миллиардов нейронов и более 100 триллионов синаптических связей! Именно такая сложная структура позволяет человеку быть человеком, позволяет проявлять интеллектуальную деятельность, о которой мы говорили ранее.
И — о чудо! — для искуственных нейросетей это работает очень похожим образом! Благодаря своему строению нейросети способны выполнять некоторые операции, которые способен делать человек, но не способны делать другие алгоритмы машинного обучения! Например, распознавать лица людей, писать картины, создавать тексты и музыку, вести диалоги и многое другое.
Вспомните, о чем мы говорили в самом начале ролика — все самые современные прототипы ИИ как раз основаны на нейросетях! Однако, сами по себе нейронные сети — не более чем набор сложно связанных искуственных нейронов. Для нейросетей самая важная часть — это обучение!
Глубокое (глубинное) обучение или Deep Learning
Так вот процесс обучения глубоких нейросетей называют глубоким или глубинным обучением. Этот подвид машинного обучения позволяет решать гораздо более сложные задачи для большего количества назначений. Но стоп, неужели до этого не додумались раньше?
Первые нейронки и программы, способные к самообучению появились еще аж в середине двадцатого века! В чем проблема? А вот в чем.
Раньше у человечества просто не было достаточных вычислительных мощностей для реализации работы нейронок, как и не было достаточно данных для их обучения. Даже сегодня классическим процессорам с двумя или даже с шестьюдесятью четырьмя ядрами (как в AMD Ryzen Threadripper PRO) не под силу эффективно производить вычисления для нейронных сетей. Всё потому что работа нейронок — это процесс сотен тысяч параллельных вычислений.
Да, это простейшие логические операции сложения и умножения, но они идут параллельно в огромном количестве.
Именно поэтому сегодня так актуальны нейронные процессоры или модули которые присутствуют в том же Apple Bionic, в процессорах Qualcomm или в чипе Google Tensor, состоящие из тысяч вычислительных ядер минимальной мощности. Как раз на них и возложена функция нейронных вычислений.
Собственно, по этим причинам только в середине нулевых годов нейросетям нашли реальное применение, когда все звезды сошлись: и компьютеры стали достаточно мощными, чтобы обслуживать такие большие нейронные сети, и наборы данных стали достаточно объёмными, чтобы суметь обучить эти сложные нейронные машины.
Так и возникло глубокое обучение. Оно предполагает самостоятельное выстраивание (тренировку) общих правил в искусственной нейронной сети на примере данных во время процесса обучения.
Это значит, что глубокое обучение позволяет обучить правильно настроенную нейросеть почти чему угодно. Ведь нейросеть самостоятельно выстраивает алгоритмы работы!
То есть при правильной настройке и достаточном количестве данных нейросеть можно научить, и лица людей распознавать, и письменный тескт расшифровывать, или устную речь преобразовывать в текст или даже текст преобразовывать в графическое изображение. Как пожелаете!
Также важно заметить, что для достижения высокой производительности нейронным сетям необходимо действительно огромное количество данных для обучения.
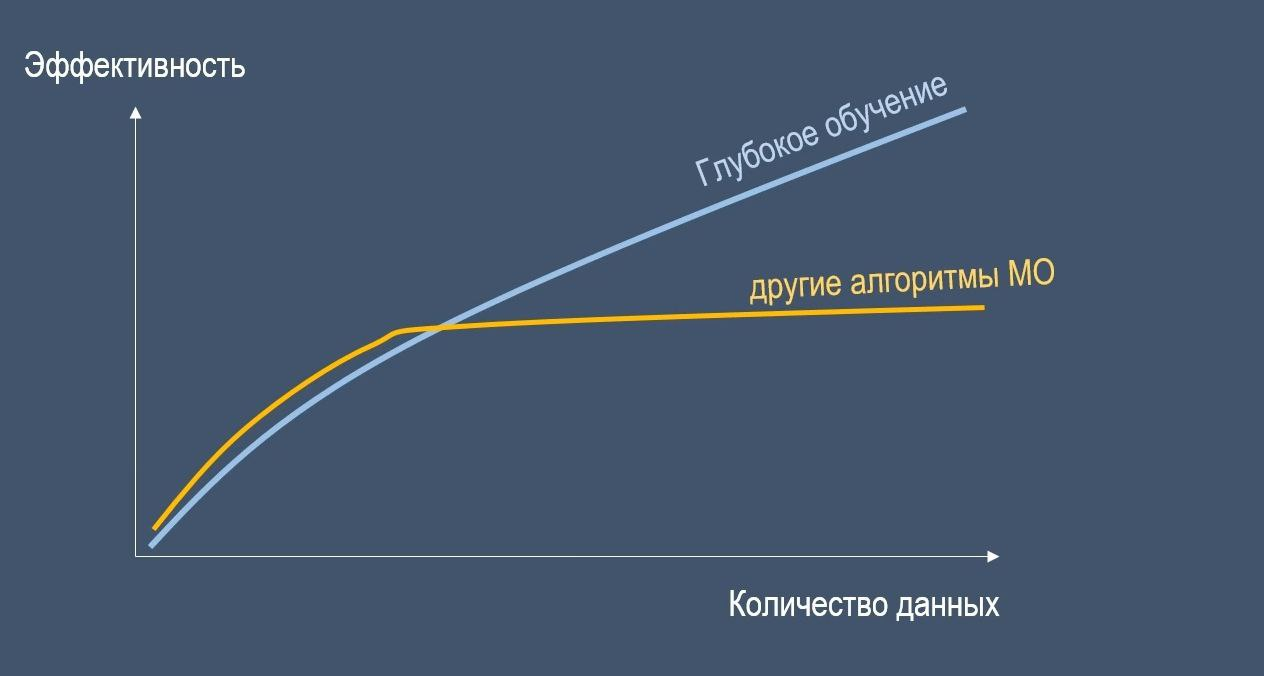
В противном случае нейросети могут даже уступать в эффективности другим алгоритмам машинного обучения, когда данных недостаточно.
Отличия сетей глубинного обучения от других алгоритмов машинного обучения
А вот небольшая таблица которая показывает отличия нейронных сетей глубинного обучения от других алгоритмов машинного обучения
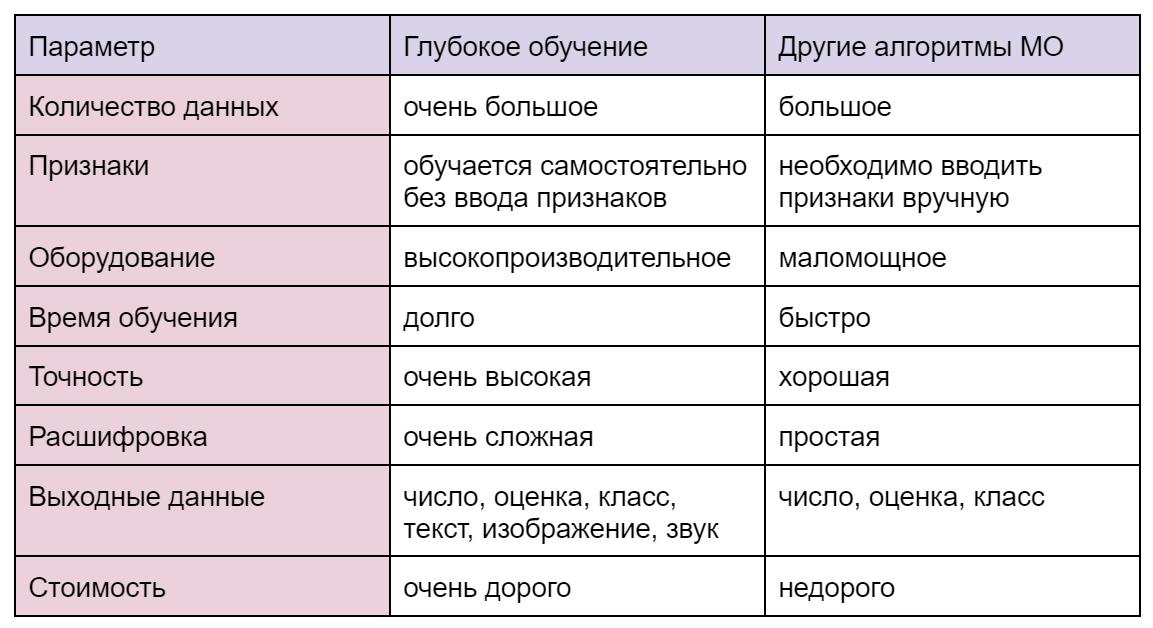
Нейронные сети являются самым сложным вариантом реализации машинного обучения, поэтому они больше похожи на человека в своих решениях.
В качестве результата вычислений нейронки могут выдавать не просто числа, оценки и кодировки, но и полноценные тексты, изображения и даже мелодии, что не под силу обычным алгоритмам машинного обучения.
Яркий пример — нейросеть ruDALL-E от Сбера, способная создавать картины из текстовых запросов. Вот что выдала нам эта нейросеть на запрос “Droider.ru”:

Выглядит интересно: то ли какой-то ноутбук, то ли утюг, то ли степлер… В общем, явно что-то неживое и из мира технологий. И на том спасибо…
А вот парочка работ другой подобной художественной нейросети Dream by WOMBO по аналогичному запросу:


Ну а здесь уже более различимы какие-то силуэты дроидов. На мой взгляд, сверху настоящая крипота, напоминающая робота-зайца из “Ну, погоди”, а справа некий двоюродный брат R2-D2 из “Звездных войн”.


Оставляем сиё творчество исключительно на ваш суд!
Выводы

Что ж, надеюсь, что вы дочитали материал до конца и усвоили разницу в понятиях искусственного интеллекта, машинного обучения, нейросетей и глубокого обучения.
Теперь мы понимаем, что распознавание образов, лиц, объектов, речи, вся робототехника и беспилотные устройства, машинный перевод, чат-боты, планирование и прогнозирование, машинное обучение, генерирование текста, картин, звуков и многое-многое другое — всё это искуственный интеллект, точнее, разновидности его воплощений. Если совсем коротко резюмировать наш сегодняшний материал, то:
- ИИ относится к устройствам, проявляющим в той или иной форме человекоподобный интеллект.
- Существует множество разных методов ИИ, но одно из подмножеств этого большего списка — машинное обучение — оно позволяет алгоритмам учиться на наборах данных.
- Нейронные сети — это разновидность алгоритмов машинного обучения, построенных по аналогии с реальными биологическими нейронами человеческого мозга.
- Ну и, наконец, глубокое обучение — это подмножество машинного обучения, использующее многослойные нейронные сети для решения самых сложных (для компьютеров) задач.
Сегодня мы с вами являемся, по сути, свидетелями рождения искусственного разума.
Только задумайтесь: ИИ применяется сейчас практически везде. Скоро даже в сельском туалете можно будет получить контекстную рекламу на основе ваших персональных рекомендаций. И это далеко не всё. ИИ уже проходит тесты на “человечность”, может заменять нам собеседника и создавать произведения искусства. Что же дальше? Создание общего и сильного ИИ и порабощение человечества?
Так все-таки ИИ — это хорошо или плохо? И главное — сделает ли ИИ нас бессмертными? Можно ли будет оцифровать сознание?